







01人体关键点检测和MMPose
记录时间:2023年6月2日
人体姿态估计的介绍和应用
姿态估计
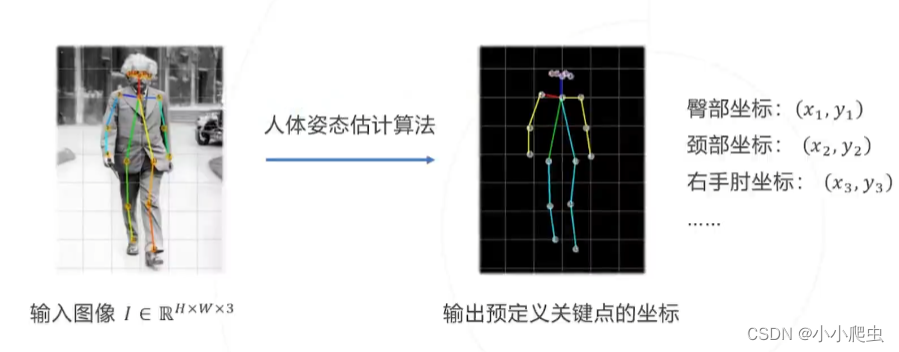
定义:从给定的图像中识别人脸、手部、身体等关键点
输入:图像I
输出:关键点坐标
(
x
1
,
y
1
)
,
.
.
.
,
(
x
j
,
y
j
)
(x_1,y_1),...,(x_j,y_j)
(x1,y1),...,(xj,yj),
j
j
j为关键点的总个数,大小取决于模型。
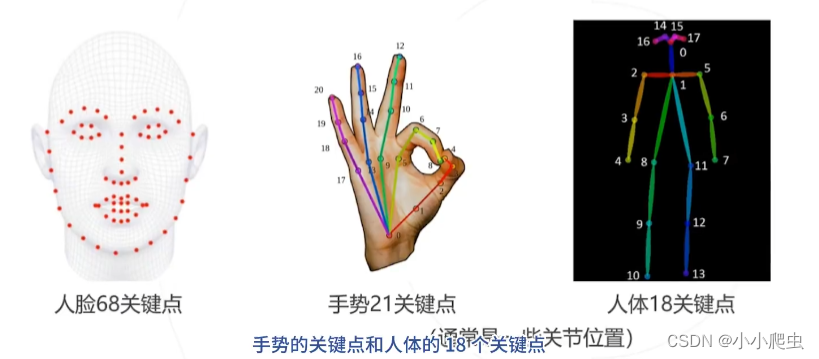
基本内容
- 2D姿态估计——在图像上定位人体关键点(通常为主要关节)的坐标。
- 3D姿态估计——预测人体关键点在三维空间中的坐标,可以在三维空间中还原人体的姿态
- 人体参数化模型——从图像或者视频中恢复出运动的3D人体模型
下游任务
- 行为识别——PoseC3D(基于人体姿态识别行为动作)
- CG、动画
- 人机交互(手势识别)
- 动物行为分析
2D姿态估计
定义:在图像上定位人体关键点(通常为主要关节)的坐标。
关键点检测的两种思路
思路1:基于回归(Regression Based),将关键点检测问题建模成一个回归问题
问题:深度模型直接回归坐标有困难,精度不是最优

思路2:基于热力图(Heatmap Based),预测关键点每个位置的概率
优点:精度更高
问题:计算消耗大

问题1:从数据标注生成热力图的过程是怎么样子的?下图中的
H
j
(
x
,
y
)
H_j(x,y)
Hj(x,y)是否代表了一张热力图?其中的
x
j
,
y
j
,
σ
x_j,y_j,\sigma
xj,yj,σ是否均是人为给定的?

多人姿态估计的三种方法
方法1:自顶向下
step1:使用目标检测算法检测出每个人体
step2:基于单人图像估计每个人的姿态
缺点:整体精度受限于检测器的精度、速度和计算量与人数成正比

方法2:自底向上
step1:使用关键点检测模型检测出所有人体关键点
step2:基于关键点位置关系或其他辅助信息将关键点组合成不同的人
优点:推理阶段与人数无关

方法3:单阶段
结合方法1的step1与step2为一步
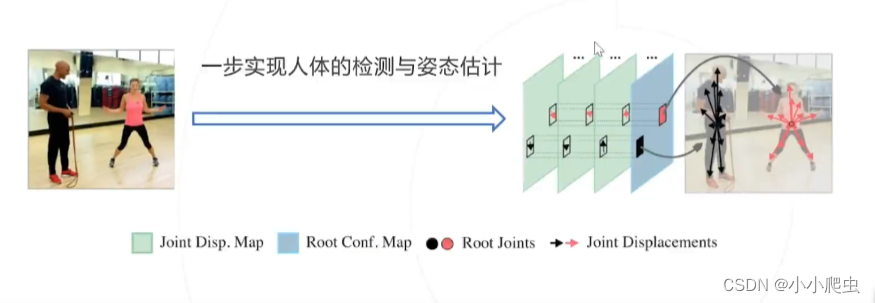
具体工作
基于回归的、自顶向下的方法
1. DeepPose
论文:
核心思路:以分类网络为基础,将最后一层改为回归,一次性预测所有
J
J
J个关键点的坐标;通过最小化平方误差训练网络;通过级联提高精度。

问题2:学习AlexNet、ResNet
问题3:级联的具体实现方法
优势:
- 理论上可达到无限精度,热力图方法受限于特征图的空间分辨率(加上期望可能不太相同);
- 不需要维持高分辨率的特征图,计算方面成本更低,效率更高。
劣势:
精度弱于热力图,因此DeepPose提出很长一段时间,2D关键点预测算法主要基于热力图
2. Residual Log-likelihood Estimation(RLE)
论文:Human pose regression with residual log-likelihood estimation(ICCV2021)
核心思路:对关键点进行更准确的概率建模(将简单的高斯分布替换为一个可学习的、表达能力更强的分布,更好的拟合关键点的实际分布),提高位置预测的精度;利用重参数化的技巧降低模型拟合真实分布的难度;利用残差似然函数的技巧降低模型拟合真实分布的难度。
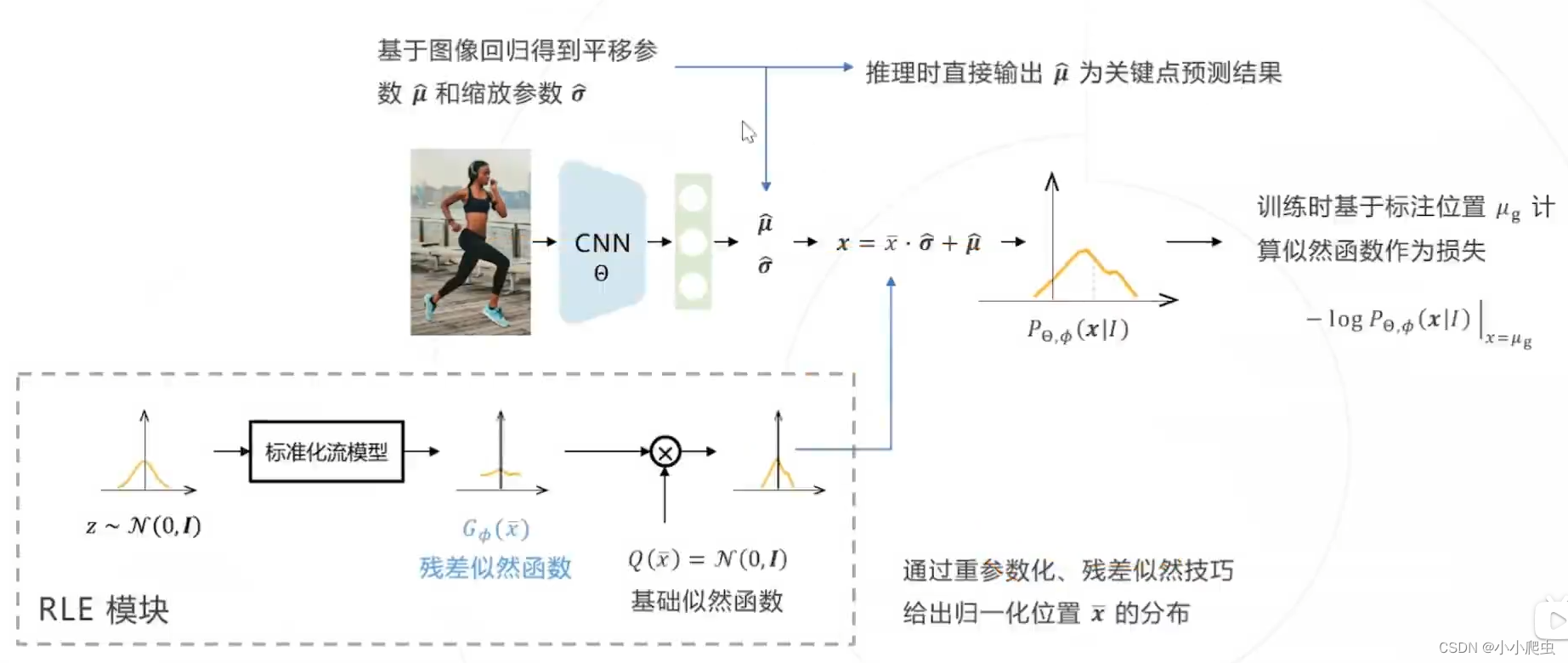
背景知识:
-
回归和最大似然估计的联系——基于二范数误差的回归和基于高斯似然的最大似估计是等价的。结论:二范数回归隐含了关键点位置符合固定方差的各向同性的高斯分布的假设

-
标准化流——一种生成建模方法,通过一系列可学习的可逆的映射,将标准分包的随机变量映射成复杂分布的随机变量,可用于建模复杂的概率分布。
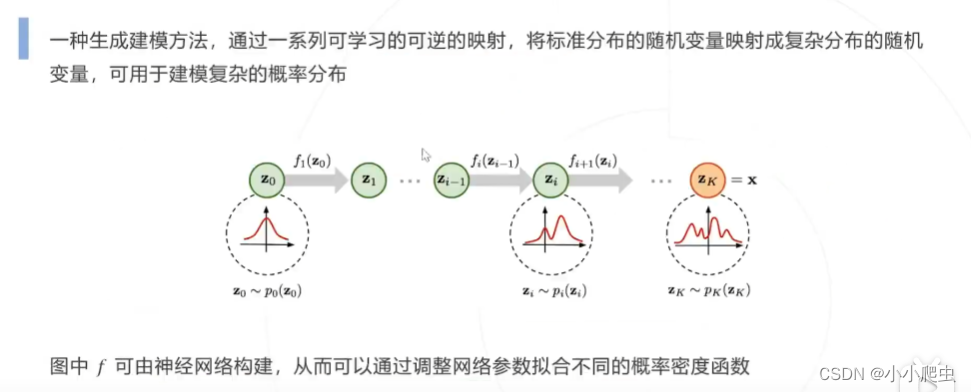
-
重参数化——(未理解)

-
残差似然函数——(未理解)
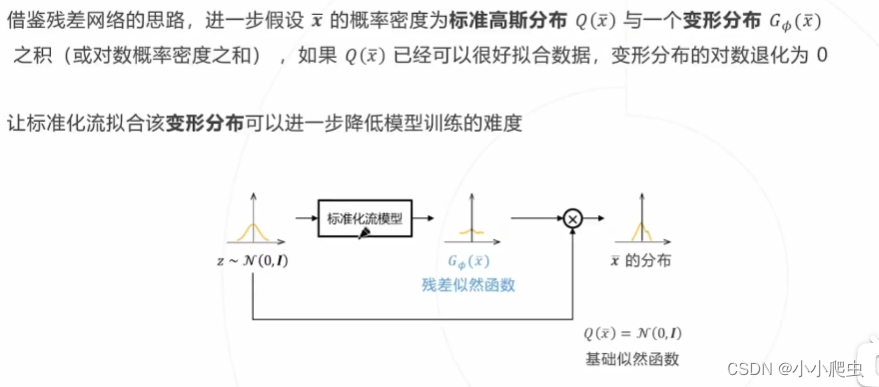
问题4:对于下面的话搞清楚并理解

问题5:了解回归与最大似然的关系,并搞清楚原理
问题6:掌握标准化流、重参数化、残差似然函数作为最基本的工具,并在以后进行使用
基于热力图、自顶向下的方法
1. Hourglass
论文:Stacked hourglass networks for human pose estimation(ECCV2016)
核心思路:准确的姿态估计需要结合不同尺度的信息;通过级联得到更强的模型
- 局部信息——检测不同身体组件
- 全局信息——建模组件之间的联系,在大尺度变形、遮挡时也可以准确推断出姿态。
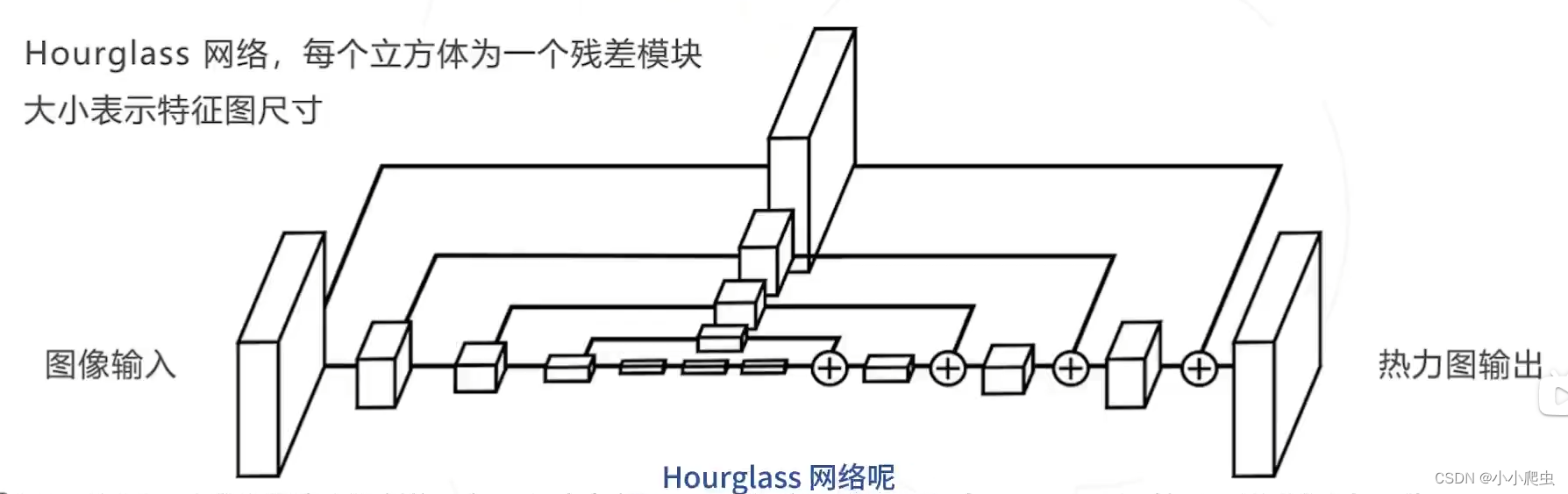 问题7:残差模块与上面的残差似然函数之间的关系?残差这一工具具体的使用方式是什么?
问题7:残差模块与上面的残差似然函数之间的关系?残差这一工具具体的使用方式是什么?
2. Simple Baseline
论文:Simple baseline for human pose estimation and tracking.(ECCV2018)
核心思路:求结构简单,使用ResNet配合反卷积形成编码、解码器结构
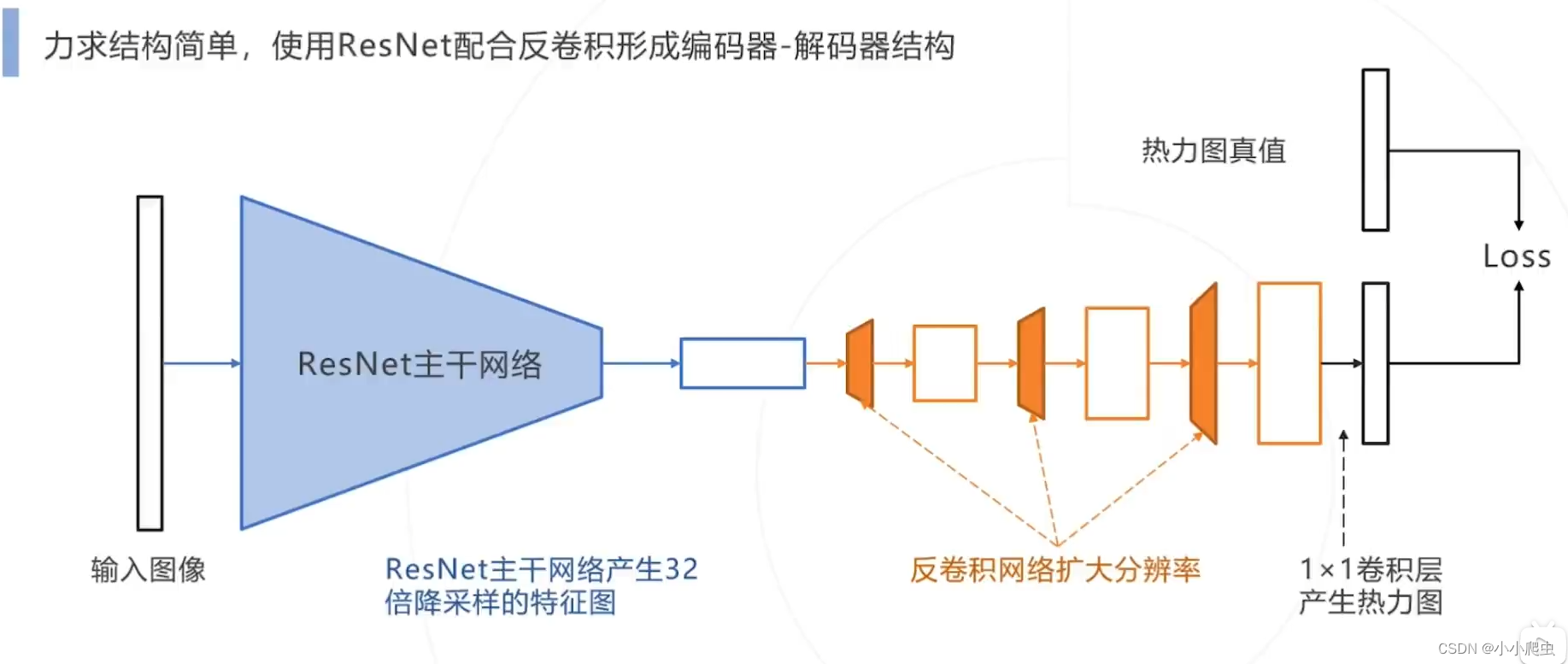
问题8:什么叫做反卷积?
3. HRNet
论文:Deep high-resolution representation learning for visual recongnition.(IEEE Transctions on pattern analusis and mechine intelligence,2020)
核心思路:下采样时通过保留原分辨率分支来保持网络全过程特征图的高分辨率和空间位置信息,并设计了独特的网络结构实现不同分辨率的多尺度特征融合。
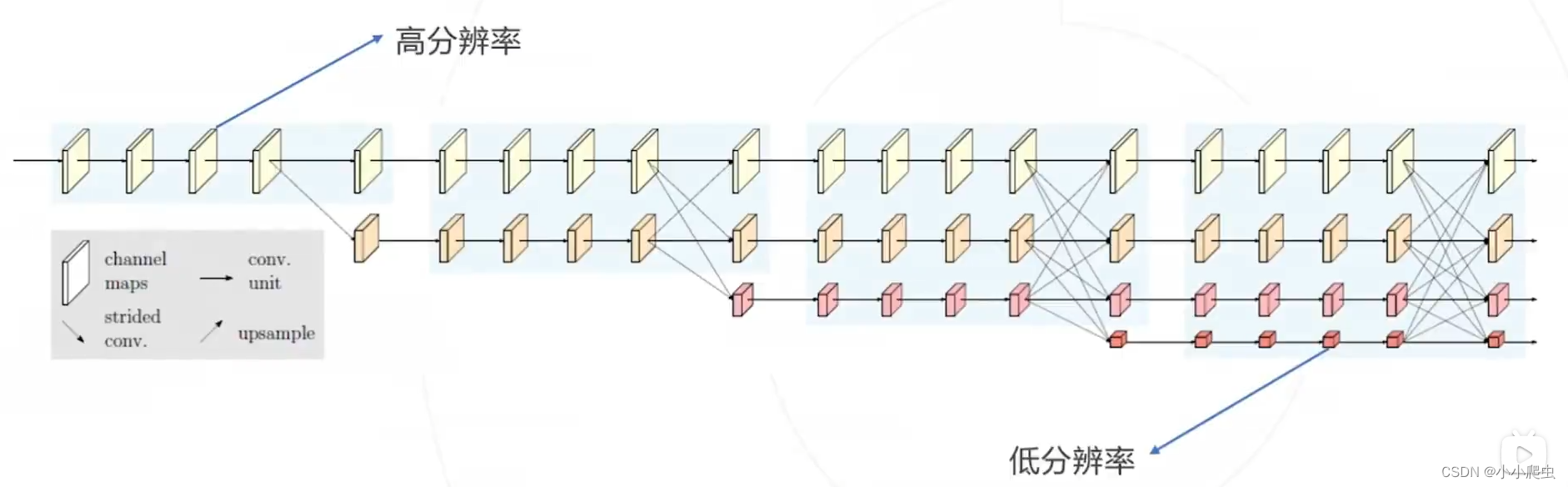
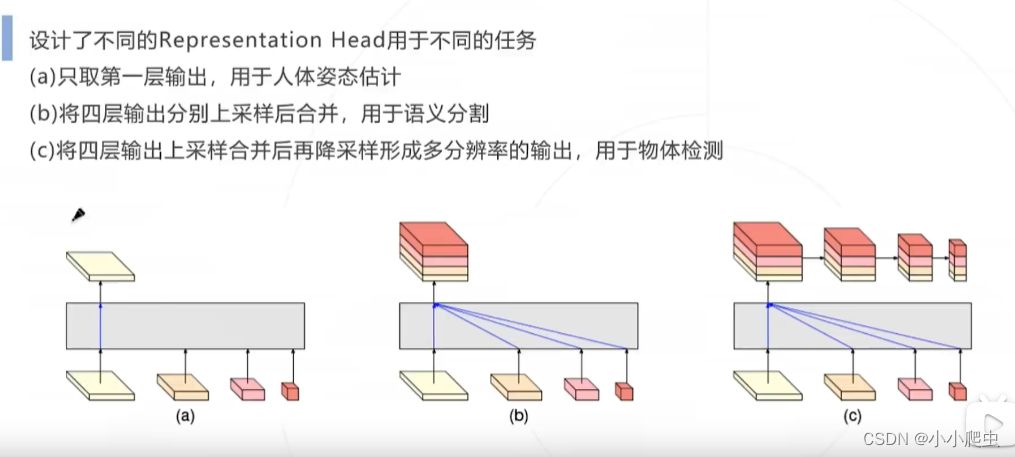
问题9:任务头(Representation Head)是什么意思?作用如何?
自底向上的方法
-
Part Affinity Fields & OpenPose
论文:没给(2016)
核心思路:同时预测关节位置和四肢走向,利用肢体走向辅助关键点聚类,如果两个关键点与同一个肢体相连,则为同一个个体。
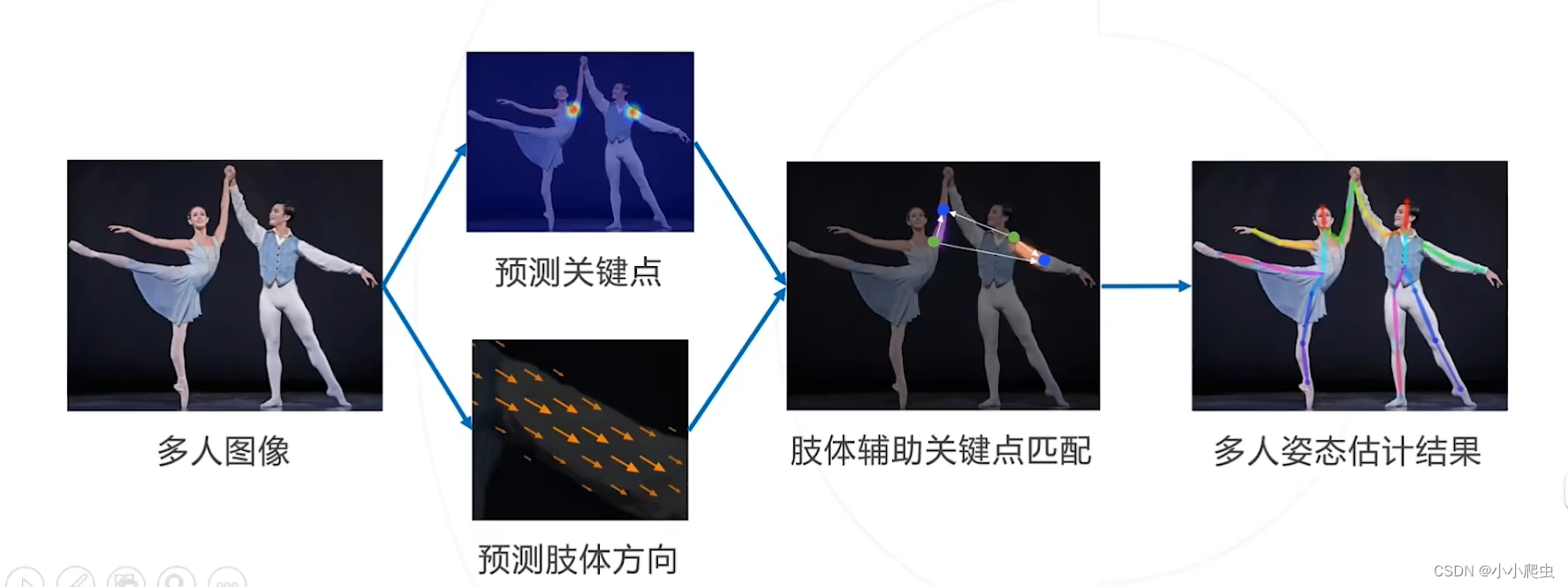

问题6:什么叫做Convolutional Pose Machine
缺陷:只计算了方向,没有计算距离
先计算关键点亲和度,之后可以根据亲和度再进行聚类、匹配。(可以借鉴一些亲和度计算方法,来在需要聚类的地方当作参考,比如说加密密文中,如果要确定某一些密文的重要性,可以根据重要的密文和与之相关联的密文的亲和度来判断(一个思路,不一定对))

单阶段方法
-
SPM
论文:Singele-stage multi-preson pose machines(ICCV2019)
核心思路:首次提出单阶段方法(思路老师说很像物体检测,但是暂时不太懂)
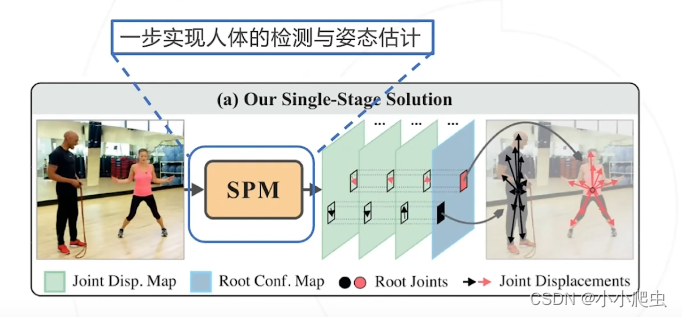
SPR:
以一个中心点回归各个方向的关节点Hierarchical SPR:
 网络设计、回归策略、损失函数为后续讲的三部分内容,需要注意关注。
网络设计、回归策略、损失函数为后续讲的三部分内容,需要注意关注。
基于Transform的方法
-
PRTR
论文:Pose recognition with cascade transformers(CVPR2021)
核心思路:人体姿态估计与物体检测都涉及到图像内容定位,可以借助注意力机制逐渐聚焦到特定的物体上。

-
TokenPose
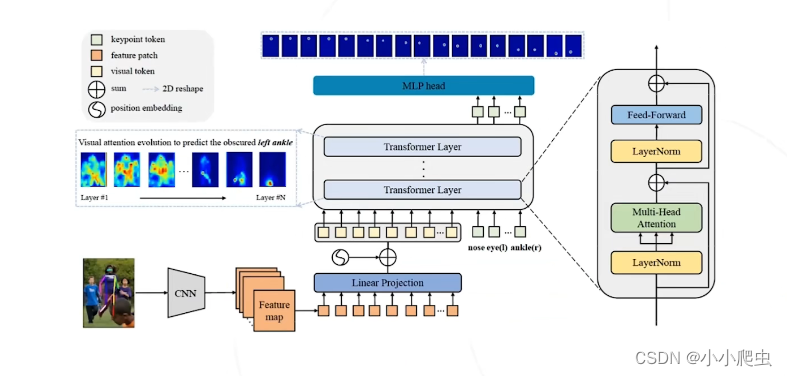
论文:Tokenpose:Learning keypoint tokens for human pose estimation(ICCV2021)
核心思路:不理解(上篇还没整明白呢)
3D姿态估计
定义:通过给定图像预测人体关键点再三维空间中的坐标,可以在三维空间中还原人体的姿态。
输入:
I
∈
R
H
×
W
×
3
I\in\mathbb{R}^{H\times W\times 3}
I∈RH×W×3
输出:所有人 所有关键点的空间坐标
{
(
x
j
i
,
y
j
i
,
z
j
i
)
}
j
=
1
,
.
.
.
,
J
i
=
1
,
.
.
.
,
N
\{(x_j^i,y_j^i,z_j^i)\}^{i=1,...,N}_{j=1,...,J}
{(xji,yji,zji)}j=1,...,Ji=1,...,N

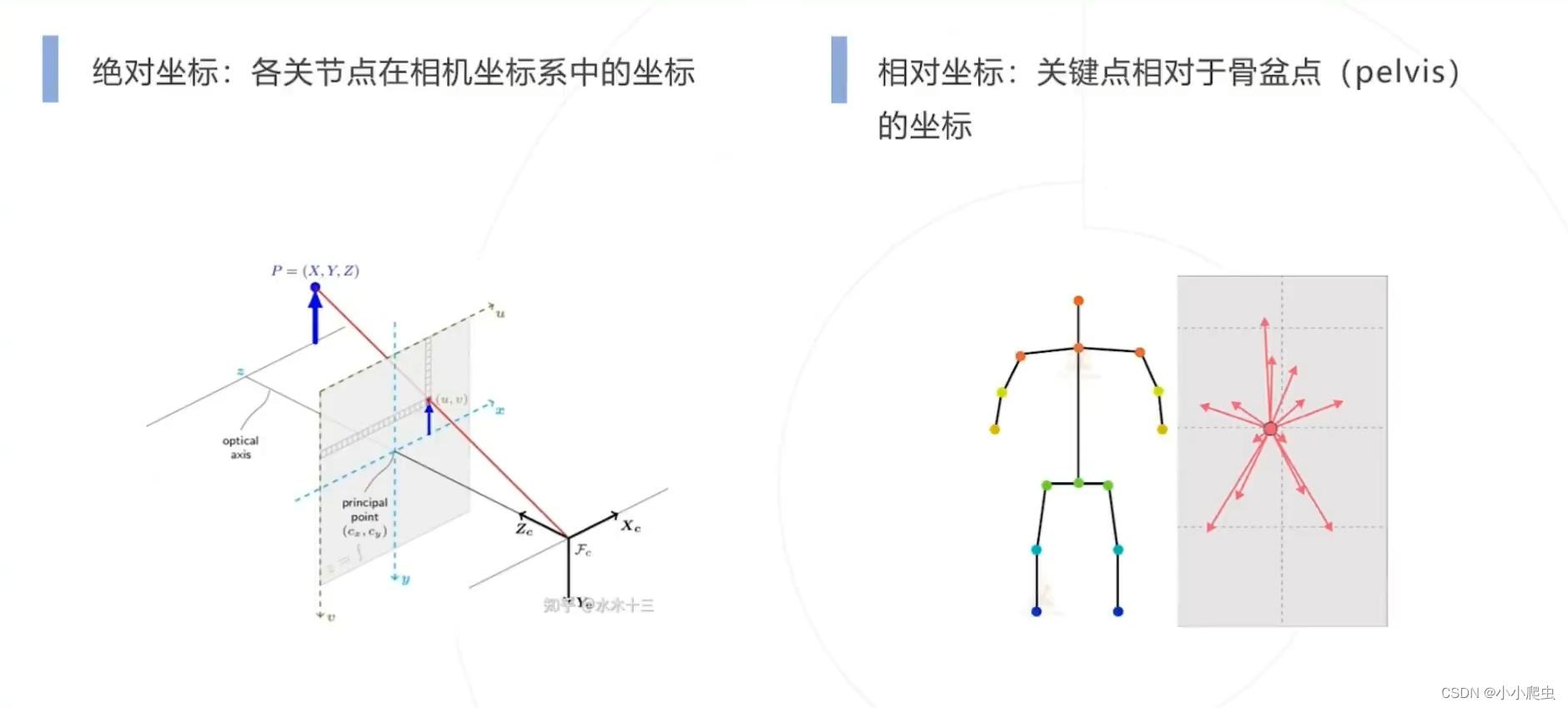
背景知识
绝对坐标与相对坐标
目标
从2D图像(或视频)中恢复3D信息
思路1:直接预测
隐式借助了语义特征或人体的刚性来实现3D姿态推理(未理解)
思路2:利用视频信息
利用视频获取更多的帧间信息辅助判断

思路3:利用多视角图像
运用对同一对象的多视角拍摄的图片还原3D信息(多个摄像头)

研究工作
1、Coarse-to-Fine Volumetric Prediction(2017)
论文:Coarse-to-fine volumetric prediction for single-image 3D human pose (CVPR2017)
思路:单张图片输入卷积网络,预测3D热力图
问题:细节不懂,需要看论文

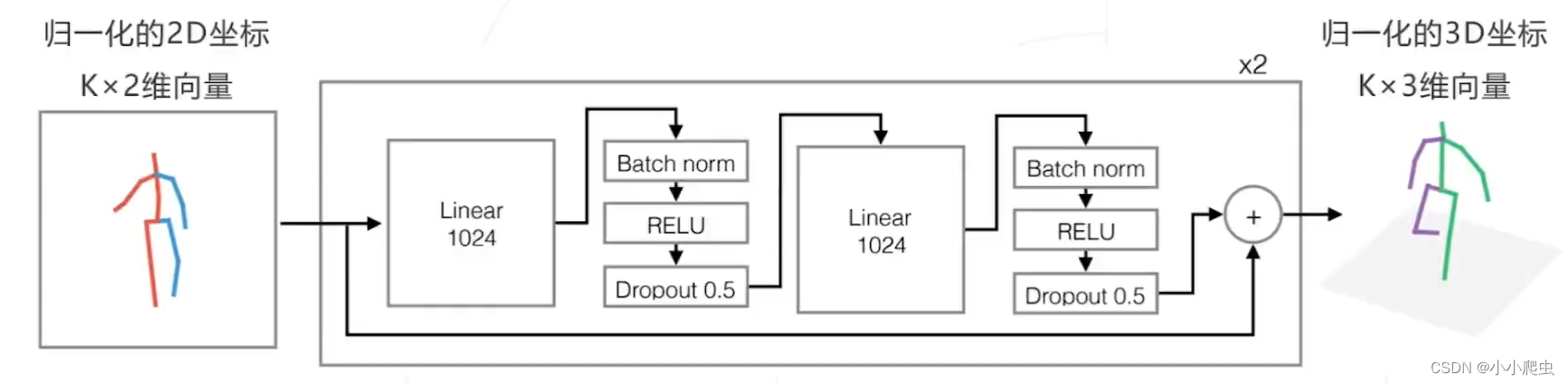
2、Simple Baseline 3D(2017)
论文:A simple yet effective baseline for 3d human pose estimation.(ICCV2017)
思路:一个有趣的发现——直接用2D坐标预测3D可以取得比较好的效果
问题:细节不懂,需要看论文
3、VideoPose3D(2018)
网址:Github上查询
思路:基于单帧图像预测2D关键点,再基于多帧2D关键点预测3D关键点位置
问题:细节不懂,需要看代码

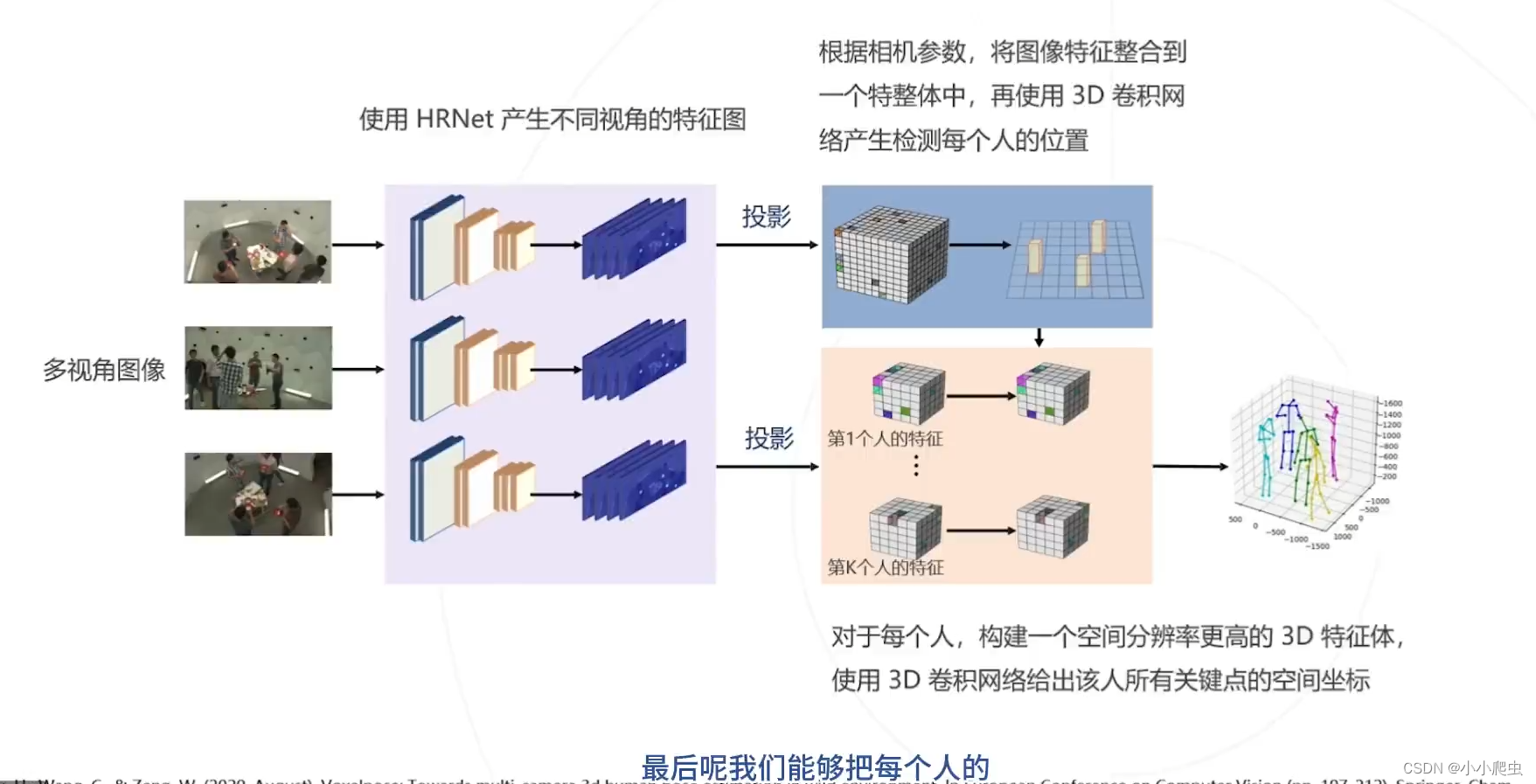
4、VoxelPose(2020)
论文:Voxepose:Towards multi-camera 3d human pose setimation in wild environment(ECCV2020)
思路:没听懂
问题:同思路
评估指标
此处先记录了评价指标,公式后期再补上
1、Percentage of Correct Parts(PCP)
以肢体检出率作评价指标
2、Percentage of Detected Joints(PDJ)
以关节点的位置精度作为评价指标
3、Percentage of Correct Key-points(PCK)
以关键点的检测精度作为评价指标
4、Object Keypoint Similarity(OKS) based mAP
以关键点相似度作为评价指标计算mAP
问题:什么是mAP?
以下的部分逻辑暂时未理清,明日继续
DensePose(2018)
论文: Densepose:Dense human pose estimation in the wild(CVPR2018)
Body Mesh(2019)
论文:Humanmeshnet: Polygonal mesh revocery of humans.(ICCV2019)
身体表面网络(Body Mesh):由多边形网格组成构建的人体表面模型,通常由具有3D位置坐标的顶点来定义
Blend Skining
混合蒙皮技术(Blend Skining);使身体表面网络随内在骨骼形变的方法。
两种常见的技术:
1、LBS(Linear Blend Skining):线性混合蒙皮
公式
2、DQBS(Dual-Quaternions Blend Skinning):双四元数混合蒙皮















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









