









siamfc论文:Fully-Convolutional Siamese Networks for Object Tracking
gitHub代码:https://github.com/huanglianghua/siamfc-pytorch
论文模型架构:
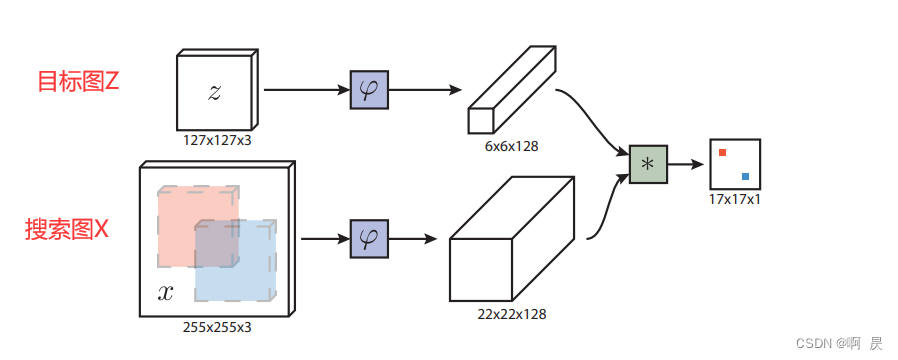
在此文章中将以代码+注释的形式详解推理过程,即test.py中的代码。
后续有空将会详解训练过程即train.py的代码。
推理大致流程代码阅读顺序:
|—test.py
|——TrackerSiamFC类
|———初始SiamFC超参
|———Net
|————BackBone
|————head*
|————Loss(BalancedLoss,测试的时候不会使用)
|————Optimizer(SGD)
|————Lr
|——ExperimentOTB类
|———OTB类(继承Object)
|——run函数
|——eport函数(结果)
代码流程
test.py:
首先看到trackerSiamFC类(test.py --Line15)
crtl+左键点进去,进入到siamfc.py中
TrackerSiamFC类中init函数:
代码详解(注释)
过程简述:
- 超参初始化
- 创建siamfc架构;
- 模型加载;
- 定义损失函数(BalancedLoss,测试的时候不会使用);
- SGD优化器;
- 获得指数衰减学习率因子函数:ExponentialLR
回到test.py中,看到ExperimentOTB类(test.py --Line19)
crtl+左键点进去。进入到experiments\otb.py中
ExperimentOTB类中init函数:
这是Siamfc作者定义的一个类,方便使用OTB10K数据集。
init()中:
- 首先用OTB类初始化好数据集
- 初始化结果路径
补充:OTB类代码详解(注释)
回到test.py中,看到run函数(test.py --Line20),crtl+左键点进去。
experiments/otb.py下run函数
代码详解(注释)
过程简述:
通过for循环遍历dataset
并执行如下操作:
- 创建输出结果.txt(如果不存在的话)
- 进行推理 (最重要)
- 结果保存
当前函数中看到tracker.track(experiments/otb.py—Line55)
这是最关键的一步,点进去,进入到siamfc.py下的track函数
siamfc.py下track函数
代码详解(注释)
过程简述:
- 获得第一个框(目标框的参数)
- 如果是第一帧,进行推理初始化(init函数)
- 如果是非第一帧,进行正常推理(update函数)
- 结果框的显示
如果是第一帧,跳转进入到Init函数(siamfc.py --Line299):
siamfc.py下init函数:
代码详解(注释)
过程简述:
- 获得第一帧图片的annontation值
- 初始化裁剪图片的中心点坐标 (self.center)
- 初始化最终目标框图片大小 (self.target)
- 初始化响应图进行上采样后的大小(即 17*16==272)
- 初始化汉宁窗
- 初始化裁剪图的缩放因子
- 初始化裁剪z图片和x图片的大小
- 初始化feature_z并固定
如果非第一帧,跳转进入到update函数(siamfc.py --Line301):
siamfc.py下update函数:
代码详解(注释)
过程简述:
- 通过Crop_and_resize函数来获得不同尺度下的搜索图片大小
- 通过backbone获得feature_x;进而获得响应图response
- 上采样response为了后续计算中心偏差和图片大小偏差
- 获得最优响应图对应id(index)
- 计算中心偏差和图片大小偏差
- 修改下一帧的中心偏差和图片大小偏差
- 返回Box值,用于后续可显示化
————————————————————————————————————
代码解析:
TrackerSiamFC类init函数
额外补充:
self.parse_args函数
head=SiamFC()函数
BalancedLoss()类,测试的时候不会使用
ExponentialLR()类
class TrackerSiamFC(Tracker):
def __init__(self, net_path=None, **kwargs):
super(TrackerSiamFC, self).__init__('SiamFC', True)
self.cfg = self.parse_args(**kwargs)##超参数的定义
# setup GPU device if available
self.cuda = torch.cuda.is_available()
self.device = torch.device('cuda:0' if self.cuda else 'cpu')
# setup model
self.net = Net(
backbone=AlexNetV1(), ##特征提取层,在此不做赘述
head=SiamFC(self.cfg.out_scale))
##头处理,详看补充代码解析(注释)
ops.init_weights(self.net)
# load checkpoint if provided
if net_path is not None:
self.net.load_state_dict(torch.load(
net_path, map_location=lambda storage, loc: storage))
self.net = self.net.to(self.device)
# setup criterion
self.criterion = BalancedLoss()
##定义损失函数,详看补充代码解析(注释)
# setup optimizer
self.optimizer = optim.SGD(
self.net.parameters(),
lr=self.cfg.initial_lr,
weight_decay=self.cfg.weight_decay,
momentum=self.cfg.momentum)
# setup lr scheduler
gamma = np.power(
self.cfg.ultimate_lr / self.cfg.initial_lr,
1.0 / self.cfg.epoch_num)
self.lr_scheduler = ExponentialLR(self.optimizer, gamma)
##指数衰减学习率, 详看补充代码解析(注释)
## lr=lr*gamma**epoch
run函数
otb.py下run函数 (otb.py---Line38) def run(self, tracker, visualize=False):
print('Running tracker %s on %s...' % (
tracker.name, type(self.dataset).__name__))
# loop over the complete dataset
for s, (img_files, anno) in enumerate(self.dataset):
## img_files是list ,保存的是dataset中某一子文件夹中的所有图片路径
##anno 是list ,保存的是dataset中某一子文件夹中的groundtruth路径
seq_name = self.dataset.seq_names[s] ##取第s批数据
print('--Sequence %d/%d: %s' % (s + 1, len(self.dataset), seq_name))
# skip if results exist
record_file = os.path.join(
self.result_dir, tracker.name, '%s.txt' % seq_name)
if os.path.exists(record_file):
print(' Found results, skipping', seq_name)
continue
# tracking loop
boxes, times = tracker.track( ##最重要部分
img_files, anno[0, :], visualize=visualize)
assert len(boxes) == len(anno)
"""
img_files: 保存的是一个文件夹下所有图片的路径
anno[0, :]: 第一张图片的annotation值;目标框的annnotation值(因为siamfc始终实以第一帧图片作为目标框)
visualize: 结果的可视化
"""
# record results
self._record(record_file, boxes, times)
track函数
siamfc.py下track函数 (.siamfc.py---Line287) def track(self, img_files, box, visualize=False):
##box: 第一帧,在siamfc中是要跟踪的物体,且后续不会发生变化
frame_num = len(img_files) ##总帧数
boxes = np.zeros((frame_num, 4)) ##准备预测所有框的参数
boxes[0] = box ##获得第一个框(目标框的参数)
times = np.zeros(frame_num) ## 时间,用于后续计算fps
for f, img_file in enumerate(img_files):
img = ops.read_image(img_file)
##img_file 这里传入的是一个img路径
begin = time.time()
if f == 0: ##第一帧
self.init(img, box)
##初始化了很多参数,并固定feature_z 并作为后续的卷积核
else:##不过不是第一帧
boxes[f, :] = self.update(img) ##重要函数,实际推理过程
times[f] = time.time() - begin##耗时
if visualize:
ops.show_image(img, boxes[f, :])
return boxes, times
init函数
siamfc.py下init函数:(siamfc.py---Line116)额外补充:crop_and_resize函数
def init(self, img, box):
# set to evaluation mode
self.net.eval()##评估模式
# convert box to 0-indexed and center based [y, x, h, w]
box = np.array([ ##点转换
box[1] - 1 + (box[3] - 1) / 2,
box[0] - 1 + (box[2] - 1) / 2,
box[3], box[2]], dtype=np.float32)
self.center, self.target_sz = box[:2], box[2:]
##lefr,up,h,w--->center_y,center_x,h,w
# create hanning window
self.upscale_sz = self.cfg.response_up * self.cfg.response_sz
##reponse_sz==17 (对应论文)
##response_up : 将最后的响应图上采样的倍率 这里是16
##响应图上采样后的大小: upscale_sz==272
self.hann_window = np.outer(
np.hanning(self.upscale_sz),
np.hanning(self.upscale_sz))
self.hann_window /= self.hann_window.sum() ##汉宁窗的创建
##汉宁窗结果是越靠近中心,值越大
##在这里主要是为了抑制边缘特征,突出中心
# search scale factors
self.scale_factors = self.cfg.scale_step ** np.linspace(
-(self.cfg.scale_num // 2),
self.cfg.scale_num // 2, self.cfg.scale_num)
##截取 搜索框框图片时不同的缩放因子
##当 scale_num==3 and scale_step==1.3075
##则sacle_factos的值为:[0.9638 1 1.0375]
##获得裁剪图片大小
# exemplar and search sizes
context = self.cfg.context * np.sum(self.target_sz)
##self.cfg.context==0.5
self.z_sz = np.sqrt(np.prod(self.target_sz + context))
##目标框(Z)图片裁剪的宽和高
##np.prob 表示内积: 即 w*h
self.x_sz = self.z_sz * \
self.cfg.instance_sz / self.cfg.exemplar_sz
###乘以 255/127 获得搜索框框(x)图片裁剪的宽和高
##x,sz 一般为 220左右
# exemplar image
self.avg_color = np.mean(img, axis=(0, 1)) ##原始图片img
##三通道求均值,用于后续填充使用
z = ops.crop_and_resize(
img, self.center, self.z_sz,
out_size=self.cfg.exemplar_sz,
border_value=self.avg_color)
##中心,按照 z_sz大小裁剪,并resize到 emamplar_sz
# exemplar features
z = torch.from_numpy(z).to(
self.device).permute(2, 0, 1).unsqueeze(0).float()
self.kernel = self.net.backbone(z) ##卷积kernel====feature_z (目标框特征), 放到init函数中代表后续的卷积核不会改变(因为在推理过程)
update函数
siamfc.py下update函数 (./siamfc.py---Line172) def update(self, img): ##非第一帧,要进行实际预测
# set to evaluation mode
self.net.eval()
# search images
x = [ops.crop_and_resize(
img, self.center, size=self.x_sz * f, ##第二帧时,self.center 为第一帧的中心
out_size=self.cfg.instance_sz,
border_value=self.avg_color) for f in self.scale_factors]
##通过 len (scale_factors)个尺度,获得不同的 img_x
x = np.stack(x, axis=0) #堆叠
##X.shape=B,W,H,C ## B==len(scale_factors)
x = torch.from_numpy(x).to(
self.device).permute(0, 3, 1, 2).float()
##B,W,H,C-->B,C,W,H
# 获得相应图responses
x = self.net.backbone(x) ## feature_x
responses = self.net.head(self.kernel, x) ##得到相应图 response
responses = responses.squeeze(1).cpu().numpy()####N,1,W,H--->N,W,H
# upsample responses and penalize scale changes
responses = np.stack([cv2.resize(
u, (self.upscale_sz, self.upscale_sz),
interpolation=cv2.INTER_CUBIC)
for u in responses])
##上采样缩放图
##resspnses.shape:N,1,272,272
"""
对发生形变的图片对应的响应图进行惩罚
如果self.cfg.scale_num ==3
对第一张和第三张图片进行尺度惩罚,因为除了第二张,其他图片都发生了形变(乘了 self.sacle_factor)
中间图片不进行缩放尺度惩罚
"""
responses[:self.cfg.scale_num // 2] *= self.cfg.scale_penalty
responses[self.cfg.scale_num // 2 + 1:] *= self.cfg.scale_penalty
##PS: cfg.scale_penalty:0.9745
# peak scale
scale_id = np.argmax(np.amax(responses, axis=(1, 2))) ##获得最好的响应图对应的下标
###np.amax(responses, axis=(1, 2)): 每个响应图的 峰值
##返回这些峰值中最大的下标
# peak location
response = responses[scale_id] ##获得最好的响应图情况
response -= response.min()
response /= response.sum() + 1e-16
#归一化
response = (1 - self.cfg.window_influence) * response + \
self.cfg.window_influence * self.hann_window ##余弦窗惩罚
"""
self.cfg.window_influence:0.176
尺度惩罚因子,超参数
"""
loc = np.unravel_index(response.argmax(), response.shape) ## 获得实际的中心点坐标,在siamfc中默认最大值为图片中心的
"""
np.unravel_index函数: 返回 响应图峰值下标(index)在shape下对应的坐标点
e.g.
loc=np.unravel_index(20,(5,5)) ##loc===(4,0)
"""
# locate target center
disp_in_response = np.array(loc) - (self.upscale_sz - 1) / 2 ##实际中心点坐标减去 上采样后的response的中心;;;这里获得偏移误差
## 272图片大小中, 中心点的偏移误差
disp_in_instance = disp_in_response * \
self.cfg.total_stride / self.cfg.response_up
###total_stride==8
disp_in_image = disp_in_instance * self.x_sz * \
self.scale_factors[scale_id] / self.cfg.instance_sz
##e.g. self.x_sz约为220 self.cfg.instance_sz==255
## 转移到 127图片大小中, 中心点的偏移误差
self.center += disp_in_image ## 修改下一预测框的中心
##这里的center尺度是127*127 图片大小的
# update target size
scale = (1 - self.cfg.scale_lr) * 1.0 + \
self.cfg.scale_lr * self.scale_factors[scale_id] ## 按权重修改 图片缩放比例
##形似 (1-a) * scale1 + a * scale2
## 1- a: 原图缩放比占的比率,
## 1.0 :相对于原图的缩放比率,1.0表示维持当前情况
## scale_factors[sacle_id] : 最优 响应图 对应的缩放比率
##
self.target_sz *= scale ##下一预测框的大小要改变
self.z_sz *= scale ##Z的剪切大小 * 优化缩放比例
self.x_sz *= scale ##X的剪切大小 * 优化缩放比例
# return 1-indexed and left-top based bounding box
box = np.array([
self.center[1] + 1 - (self.target_sz[1] - 1) / 2,
self.center[0] + 1 - (self.target_sz[0] - 1) / 2,
self.target_sz[1], self.target_sz[0]])
##得到:left right w,h
return box ##预测的结果框
————————————————————————————————————
额外补充:
parse_args函数
parse_args函数 TrackerSiamFC类下parse_args函数 (siamfc.py---Line82) 功能:定义一些超参数(固定,推理时用到,训练时用到)cfg = {
# basic parameters
'out_scale': 0.001, ##获得响应图后对整体结果进行sacle缩放
'exemplar_sz': 127, ## 默认目标图像X的大小
'instance_sz': 255, ## 默认搜索图像Z的大小
'context': 0.5, ## 后续做图像切割使用
# inference parameters
'scale_num': 3, ##推理过程中,候选尺度窗的个数
'scale_step': 1.0375, ##最大候选尺度窗相对于上一帧的缩放因子
'scale_lr': 0.59, ##
'scale_penalty': 0.9745, ## 惩罚项因子
'window_influence': 0.176, ##
'response_sz': 17, ##最终得到响应图的大小
'response_up': 16, ## 响应图上采样的倍率 16*17=272
'total_stride': 8,
# train parameters
'epoch_num': 50,
'batch_size': 8,
'num_workers': 32,
'initial_lr': 1e-2, ##初始lr
'ultimate_lr': 1e-5, ##最终Lr
'weight_decay': 5e-4,
'momentum': 0.9, ##SGD
'r_pos': 16, ## 两个用来构造训练时的 label
'r_neg': 0} ## 两个用来构造训练时的 label
for key, val in kwargs.items():
if key in cfg:
cfg.update({key: val})
return namedtuple('Config', cfg.keys())(**cfg)
SiamFC类
.heads.pyclass SiamFC(nn.Module):
def __init__(self, out_scale=0.001):
super(SiamFC, self).__init__()
self.out_scale = out_scale
def forward(self, z, x):
return self._fast_xcorr(z, x) * self.out_scale
def _fast_xcorr(self, z, x): ##互相关操作
# fast cross correlation
nz = z.size(0) ##z.shape==Batch*1,128,h_z,w_z (B*1,128,6,6)
nx, c, h, w = x.size() ##x.shape==Batch*3,128,h_x,w_x (B*3,128,22,22)
##一般来说nx=B* 3(等于len(self.arg.scale_num))
x = x.view(-1, nz * c, h, w) ##3,128*B,22,22
out = F.conv2d(x, z, groups=nz)
##:x.shape==3,128*B,22,22 ,z.shape==B*1,128,6,6 ,groups=B
##得到结果Out.shape==3,B,17,17
out = out.view(nx, -1, out.size(-2), out.size(-1))
##最后out shape:[B*nx, 1, 17,17]
return out
其中F.conv2d(x, z, groups=nz)是组卷积
x.shape=3,128×B,22,22 ,z.shape=B×1,128,6,6 ,groups=B
首先考虑输出的size = (W − F + 2P )/S+1(W=22,F=6,P=0,S=1)
即size=17
组卷积步骤:
- 将x按照通道数(axis=2)划分B个,会将z按照batch(axis=3)划分B个。每个子x.shape为3,128,22,22,每个子z.shape为1,128,6,6。
- 每个子z与与子x(卷积核)进行卷积,得到子输出out.shape为3,1,17,17。
- 共进行groups=B次卷积,并按照通道数(axis=3)堆叠。即最终输出out.shape为3,B,17,17。
OTB类
/datasets/otb.py---Line72简述:
init中,会将所有图片的路径和文件夹里面的groundtruth.txt的路径保存到List里面,方便后续调用
代码解析(注释):
def __init__(self, root_dir, version=2015, download=True):
super(OTB, self).__init__()
assert version in self.__version_dict
##...
##...
##...
self.seq_dirs = [os.path.dirname(f) for f in self.anno_files]
##保存所有文件夹中groundtruth.txt路径
self.seq_names = [os.path.basename(d) for d in self.seq_dirs]
##保存所有文件夹中图片路径
# rename repeated sequence names
# (e.g., Jogging and Skating2)
self.seq_names = self._rename_seqs(self.seq_names)
crop_and_resize函数
.ops.py—Line92
参数:
def crop_and_resize(img,
center, ##裁剪中心
size, ##裁剪大小
out_size, ##最后输出大小
border_type=cv2.BORDER_CONSTANT, ##边缘填充方式:固定值填充
border_value=(0, 0, 0), ##默认固定值填充;;本文中是取每个通道均值
interp=cv2.INTER_LINEAR): ##resize是的方法:线性插值法
功能:在center位置剪切size大小图片并且缩放到output_size大小
代码解析(注释):
def crop_and_resize(img, center, size, out_size,
border_type=cv2.BORDER_CONSTANT,
border_value=(0, 0, 0),
interp=cv2.INTER_LINEAR):
# convert box to corners (0-indexed)
size = round(size)
##center[0]==center_x
##center[1]==center_y
corners = np.concatenate((
np.round(center - (size - 1) / 2),
np.round(center - (size - 1) / 2) + size))
corners = np.round(corners).astype(int)
##corners[0]==[left,up] ##左上顶点
##corners[1]==[right,down] ##右下顶点
# pad image if necessary
pads = np.concatenate((
-corners[:2], corners[2:] - img.shape[:2]))
npad = max(0, int(pads.max())) ##如果要裁剪的大小超出图像大小,则会进行pad ,##一般情况下不会发生这种情况, 则npad==0
if npad > 0:
img = cv2.copyMakeBorder(
img, npad, npad, npad, npad,
border_type, value=border_value)
# crop image patch
corners = (corners + npad).astype(int) ##一般情况下 npad==0
patch = img[corners[0]:corners[2], corners[1]:corners[3]] #截断操作,left:right, up:down 图片裁剪
# resize to out_size
patch = cv2.resize(patch, (out_size, out_size),
interpolation=interp) ##resize
return patch
BalancedLoss类,测试的时候不会使用
.losses.py—Line27 (该py文件下还有其他的损失函数,感兴趣可以自行查阅)
功能:通过看最后一行,可以发现就是(binary_cross_entropy)交叉熵损失函数,只不过多了一个weight权重,用于平衡计算最终loss。
代码解析(注释):
class BalancedLoss(nn.Module):
def __init__(self, neg_weight=1.0):
super(BalancedLoss, self).__init__()
self.neg_weight = neg_weight
def forward(self, input, target):
"""
##测试的时候不会用到,训练时:
##target是0和1 矩阵,shape==(1,15,15)
##(至于为什么不是论文中的1,17,17,主要原因是预处理时,x.shape=B,C,239,239;;详情看训练时代码解析的博客)
"""
pos_mask = (target == 1) #获得target中 1(正样本)对应的下标
neg_mask = (target == 0) #获得target中 0(负样本)对应的下标
pos_num = pos_mask.sum().float()#获得1的总数
neg_num = neg_mask.sum().float()#获得0的总数
weight = target.new_zeros(target.size())
weight[pos_mask] = 1 / pos_num
#接着生成weight矩阵, 其中正样本对应下标的值为1/正样本总数
weight[neg_mask] = 1 / neg_num * self.neg_weight
#同理,负样本对应下标的值为1/负样本总数*权重比(超参数)
weight /= weight.sum()#weight归一化
return F.binary_cross_entropy_with_logits(
input, target, weight, reduction='sum')
ExponentialLR类
网上一查便知公式,在此不做详细解析。 [学习率衰减策略 ](https://zhuanlan.zhihu.com/p/475824165)学习率计算公式: lr = lr * gamma^epoch
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:refreshmentccoffee@gmail.com















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









