









今天讲BevFusion:Simple and Robust LiDAR-Camera Fusion Framework. 这篇
因为本文太过经典,网上资源比较多,后续笔者会贴参考网址,希望读者都能够去看一看,加深印象。
本博客适用于刚看BEV感知的读者,如有错误还请指正。
BEVFusion: A Simple and Robust LiDAR-Camera Fusion Framework
论文网址:https://arxiv.org/abs/2205.13790.pdf
代码网址:https://github.com/ADLab-AutoDrive/BEVFusion
PS:
2025
/
03
/
05
更新,评论区反馈论文和代码地址给错,已更改。
\textcolor{red}{2025/03/05更新,评论区反馈论文和代码地址给错,已更改。}
2025/03/05更新,评论区反馈论文和代码地址给错,已更改。
还有一篇MIT的BEVfusion(不是本篇后续讲解的内容,不过内容也很新颖,也推荐去看看)
BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation
论文网址:https://arxiv.org/abs/2205.13542
代码网址:https://github.com/mit-han-lab/bevfusion
激光雷达与相机图像融合的方式
Bevfusion做的是雷达和图像的融合,然后得到BEV特征用于后续的3D检测(或其他下游任务)
首先,就来讲讲雷达和图像的融合方式,如下图所示:
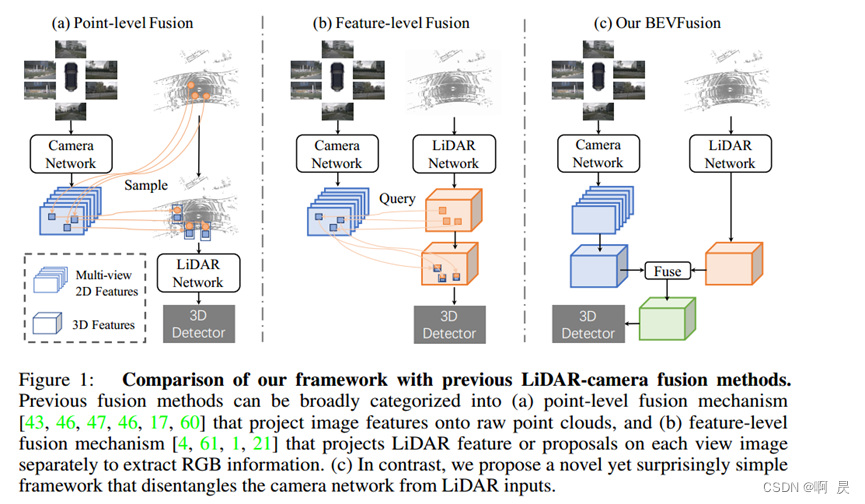
(a) Point-level Fusion,译为点级的融合。
(b) Feature-level Fusion,译为特征级融合。
前两种的缺点:
关注上图的(a)和(b)子图,会发现这两种方案其实都离不开一个映射的过程(3D点云–映射–>2D图像)
缺点1:3D–>2D的投影需要的是内参矩阵和外参矩阵,内参矩阵和相机有关。而外参矩阵如果产生偏差,那么投影也会产生偏差。
缺点2: 如果投影到2D图像上是没有图像特征,或者图像特征很糟,也会带来不好的BEV特征
缺点3:主次关系强,点云投影决定图像区域,如果点云数据丢失或异常,即使图像数据没有问题,也会发生采样异常进而影响投影异常。
( c ) 本文的策略的融合
( c ) 图中可以看到输入是图像和点云,通过两条并行的网络去做各自处理,然后通过一个融合模块(Fuse)去做融合,这样就没有主次依赖关系。即,将图像特征提取和点云特征提取的过程单独分离开来,然后在BEV空间做融合。
模型架构
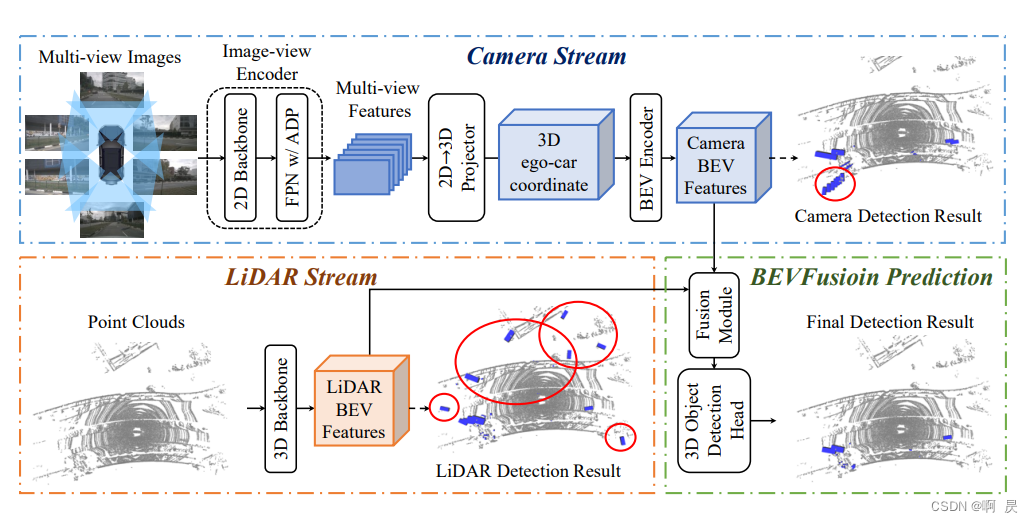
看上面的模型架构,由三块构成:相机分支、点云分支,融合预测。下面笔者分开来讲解。
PS:BEVFusion 还有一个特点,除了一个融合特征的检测头之外(融合预测的头),它在每一个模态信息下面都额外接了一个检测头(相机分支结尾有个检测头,点云分支结尾有个检测头),作者的意思是说可能融合之后的效果也不是很好,那就单独使用图像或者点云分支检测,它们是可以融合工作也可以分开独立工作,所以尽可能地避免在一些偏极端情况下产生的一些影响。
整体代码流程:
https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/detectors/bevf_faster_rcnn.py#L100
相机支路(含部分代码流程)
输入图像通过 Camera Stream 图像流来处理,通过图像编码器 Encoder 可以得到 Multi-view Features 多视角的图像特征,然后通过一个 2D➡3D 的转换器,图像特征会从 2D 映射到 3D,再从 3D 投影到 BEV 空间得到所谓的 Camera BEV Features。
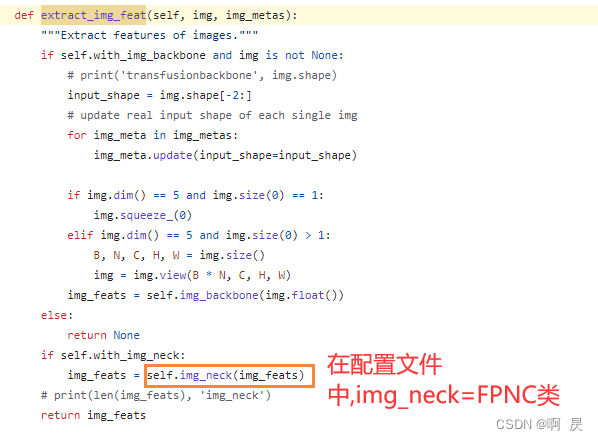
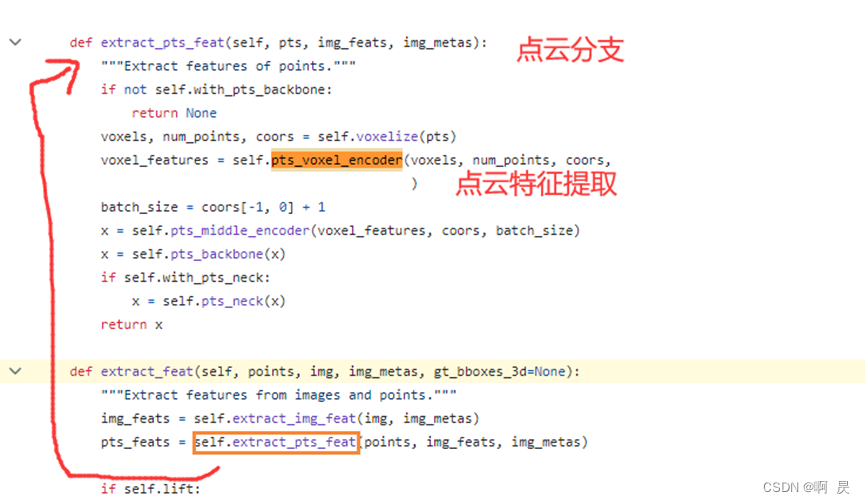
部分代码流程在整体流程里面,如下图,分别进行了图像分支(extract_img_feat)和点云分支(extract_pts_feat)的特征提取,我们先看相机支路

Image-view Encoder代码流程(对应上图的extract_img_feat函数):
https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/detectors/transfusion.py#L40
其中包括backbone 和 FPN+ADP
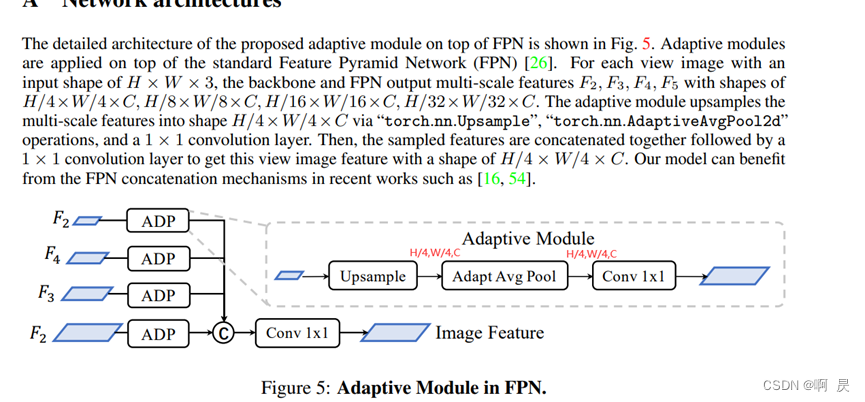
ADP模块的作用
多尺度特征尺寸是不一致的,没有办法通过级联或者相加的操作直接合在一起,所以 ADP 实现的一个重要功能就是通过上采样的操作将不同尺度的特征的尺寸变得一致。
具体流程如下图,其实还是比较清晰和简单的,Upsample之后,每个尺度的特征都变为了
C
,
H
4
,
W
4
C,\frac{H}{4},\frac{W}{4}
C,4H,4W 。
FPN+ADP代码流程(对应上图的self.img_neck调用的函数,实际上执行的是FPNC类):
https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/necks/fpnc.py#L45
主要来看前向过程: 其中的outs表示的是通过backbone输出的多尺度特征。 前面的ADP对应论文中的ADP模块

2D->3D Projector代码流程:https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/detectors/cam_stream_lss.py
其中的代码思想和LSS的代码思想是基本一致的(不了解LSS的读者可以看我上一篇LSS的讲解)。
相机支路中,图像shape总体流程的变化如下(不详细,有误请指正 )
#-------------- Image-view Encoder
B,N,3,H,W ##初始的输入图像,N表示相机的个数,一般是6
B*N,C_i,H_i,W_i ##通过backbone 得到多尺度的特征图 i表示各特征图的下标
B*N,C,H2,W2 ##通过FPN+ADP得到最终的图像特征 . 一般来说H2=H//4 W2=W//4 (原始图像大小的1/4)
#------------- 2D-->3D LSS的思想
初始x.shape== B*N,C,H2,W2,
B*N,(D+C2),H,W ## 通过一个linear层进行维度转换 D一般是41 C2一般是64
##分割下列两块,并通过 unsequenze 升维
B*N,1,C2,C,H,W ##先得到 为了方面下面的广播操作
B*N,D,1,C,H,W
##广播机制 对上列两个矩阵进行相乘
B*N,D,C,H,W ##得到结果 含有深度图的3D特征图
#------------- BEV Encoder
B,N,D,H,W,C ##reshape下
内参+外参的参数转换 ##(通过之前得到的图像视锥空间进行转换,这边代码比较繁琐,笔者没看懂) 。
B,C,Z,X,Y ---->B,C,H,W,L ##得到3D坐标以及原始的3D坐标对应特征C (Z,X,Y改写成H,W,L,不做任何处理,方便阅读)
##左边Z,X,Y是3D的坐标 右边H,W,L 分别表示3D空间的高度,宽度,长度)
B,C*H,W,L ## 3D--->2D 把高度和C乘起来,执行voxel操作 ,剩下的W,L其实就是对应2DBEV特征的W,H
B,C’,L,W ##最终的2D BEV特征, 对应 B,C,H,W (这里的L是3D里面的长,对应2DBEV图像的H)
2.2 点云支路
(这里需要一点基于点云的3D检测方面的知识。需要知道什么是点云和经典的3Dbackbone)
点云支路要容易得多,因为点云本身就是 3D 的,只要通过点云特征通过3D转2D模块即可得到BEV特征,具体的模块可以是卷积、池化等等都可以。
点云特征通过3D Backbone进行提取(基于点的方式的,也有基于体素的方式),在 BEVFusion 文章中作者本身也提供了很多可选择的方案,包括 PointPillars、CenterPoint、TransFusion。(具体代码本笔者将不会讲解,还请读者自行查找文章)
总体代码流程如下:https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/detectors/bevf_faster_rcnn.py#L100
最终输出的就是点云的BEV特征。
通过配置文解可以查到对应的类名。如下图,具体代码在:https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/voxel_encoders/pillar_encoder.py#L12
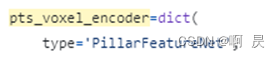
和pointpillar的预处理基本一致。不熟悉的读者可以先看看pointpillar的论文及相关讲解。
点云支路中,具体的流程
首先普通的体素(voxel),是对3D空间进行网格划分。划分 range_x /voxel_x ,range_y /voxel_y,range_z/voxel_z 。
pillar的方式相比voxel更为特殊, 划分的结果是一个长柱体,即Z方向划分的数量为1。
点云和pillar的index有一一映射的坐标关系
点云简单处理变为pillar时,每个点云特征最后会变成D=9个维度 x,y,z,r c_x,c_y,c_z ,offset_x,offset_y
ps:因为z=1所以没有 offset_z
x,y,z:点云坐标
r:反射率
c_x,c_y,c_z : 点云到每个pillar中聚类中心的距离
Offset_x,offset_y:点云的点到pillar中心的距离
由于点云的离散性, 最终会从 range_x /voxel_x *range_y /voxel_y个pillar中 选择P个pillar。P一般选择12000 ,每个pillar中最后也只会保存N个点云,N一般是100。
得到piilar特征: D,P,N (D为9对应上面x,y,z,r, c_x,c_y,c_z ,offset_x,offset_y)
然后进行如下操作得到BEV特征:
1)升维 C,P,N
2)pooling 削减点云的随机性 变为 C,P (PS这里就可以看作是图像特征中的C,L)
3)由于P是W*H维度得到的,所以后续可以生产伪2D图像(BEV特征), C,W,H
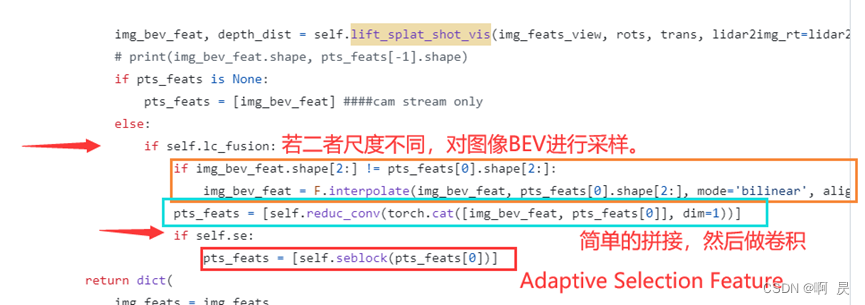
融合模块(含部分代码流程)
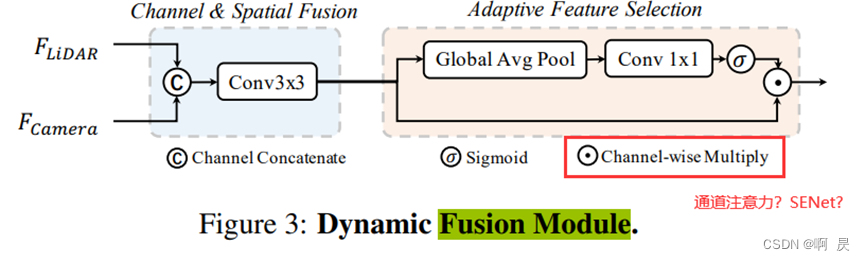
看上图,发现融合模块也是比较易懂的。首先将图像BEV和点云BEV拼接起来(注意这里,要确保二者BEV的H,W是一致的)。
然后进行Adaptive Feature Selection操作。这里我越看越眼熟,发现和SENet的结构是一致的。下面是SENet结构
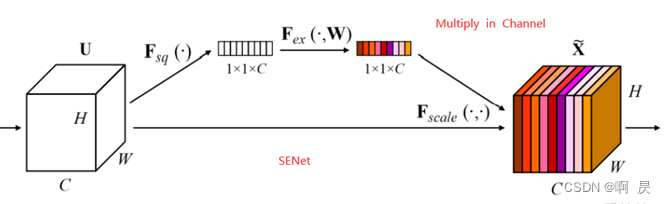
凑巧的是,作者的代码实现中Adaptive Feature Selection就是用的SENet。
代码流程如下:https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/mmdet3d/models/detectors/bevf_faster_rcnn.py#L131
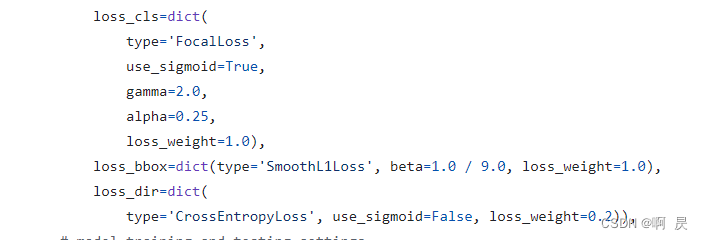
损失函数
模型架构中有三个检测头,自然就有三个损失函数
Camera Dection Head
Lidar Dection Head
Fusion Dection Head
具体公式就不说明了。
可以在下面看到(点云分支是pointpillar(pp)):
https://github.com/ADLab-AutoDrive/BEVFusion/blob/main/configs/bevfusion/bevf_pp_2x8_1x_nusc.py#L110
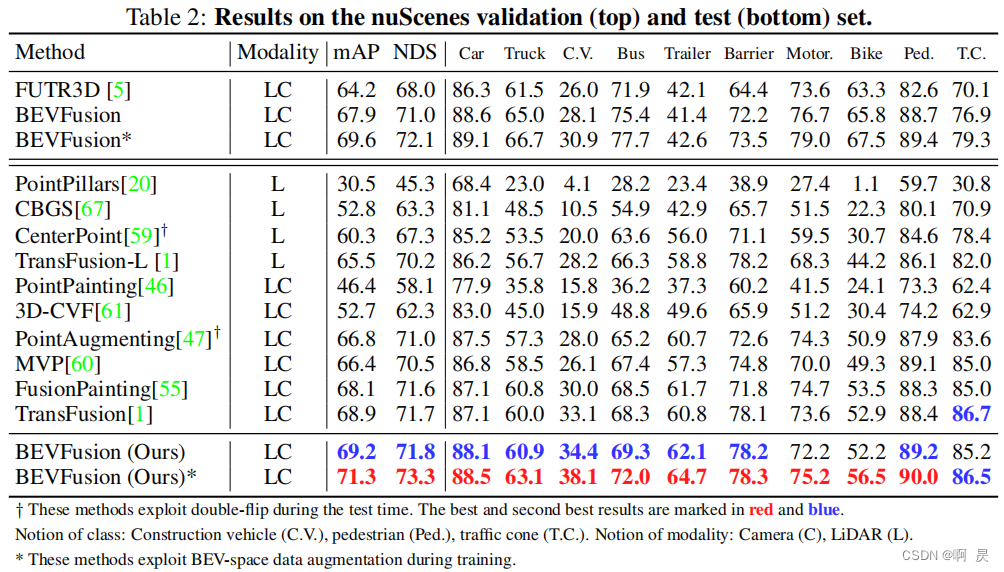
实验结果和消融实验
实验结果
看总体结果,下表是不同算法在 nuScenes 验证集和测试集上的结果,可以看到和同时期的算法相比性能还是不错的,是有明显提升的。
消融实验
选择的分支+不同的Lidar分支方法
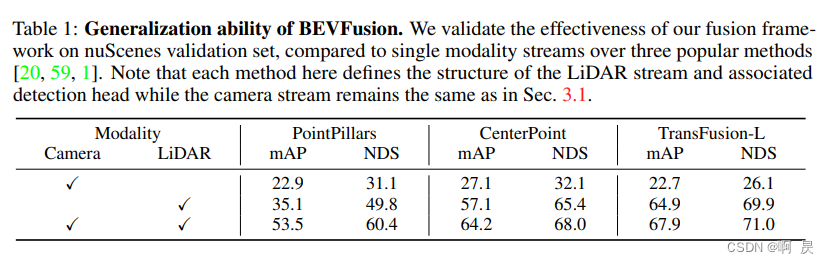
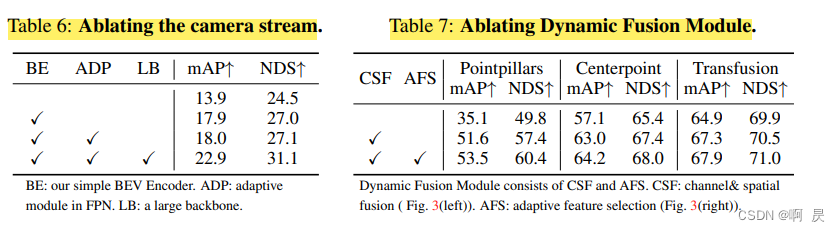
表6是相机分支那边的消融实验。
表7是特征融合模块构件的消融实验,其中CSF是图3的左边,就是对相机BEV和点云BEV拼接+卷积的操作;AFS就是图3的右边,就是Adaptive Feature Selction 也就是SENet的操作。
额外补充
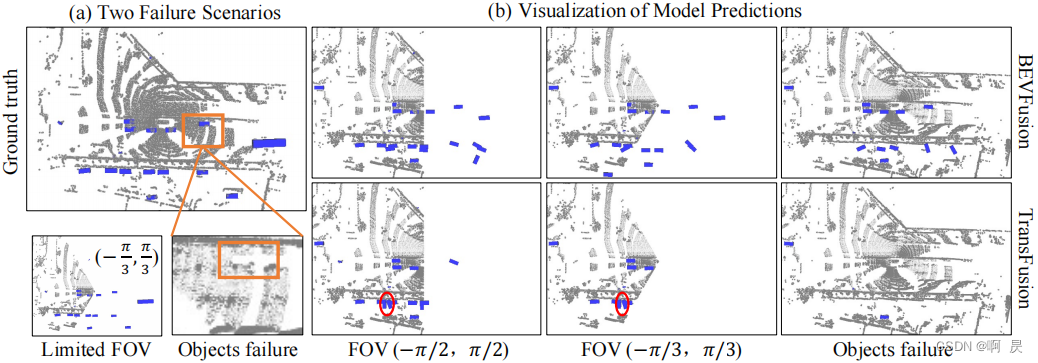
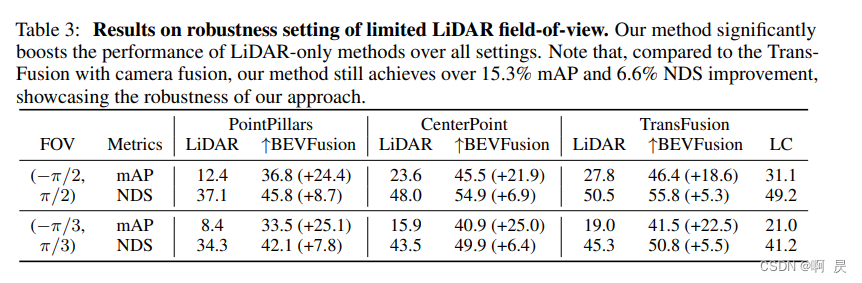
这里作者为了验证 BEVFusion 的一个性能还提供了一些困难场景,一个是视场角限制,一个是点云丢失
视场角限制是说比如只能获取到 -60° 到 +60° 的视场数据,那这个视场角外的数据是没有的,是第一种情况。第二种情况是说的数据丢失,物体的点云数据丢失,比如上图中的橘色框内是存在物体的,不过由于各种原因没有点云的反射值回传,也就是没有点云数据
那在这两种情况下,BEVFusion 其实都可以检测到,很好理解,点云虽然丢失但图像还在,而且它们之间是没有主次关系的,哪个好用哪个,所以说在 BEVFusion 中即使点云丢失了,BEVFusion 也是可以去做检测的,因为图像内容还在。
总结
一种非常经典的多模态融合感知方案叫 BEVFusion。这是一种用于多任务多传感器 3D 感知的高效通用框架。BEVFusion 将相机和 LiDAR 功能统一在共享 BEV 空间中,完全保留几何和语义信息。相机和点云分支没有明显的主次关系,相互独立,结果上又相辅相成。
高效、准确的多传感器感知对于自动驾驶汽车的安全至关重要。 BEVFusion 将最先进的多传感器融合模型的计算成本降低了一半,并在小而远的物体以及雨天和夜间条件下实现了大幅精度提高。它为安全、稳健的自动驾驶铺平了道路。
参考
自动驾驶之心的BEVFusion笔记(笔者反复观看):https://blog.csdn.net/qq_40672115/article/details/134891133
BEVFusion论文阅读: https://blog.csdn.net/qq_44114055/article/details/133833655
BEVFusion论文阅读:https://blog.csdn.net/qq_41204464/article/details/134724055
欢迎指正
因为本文主要是本人用来做的笔记,顺便进行知识巩固。如果本文对你有所帮助,那么本博客的目的就已经超额完成了。
本人英语水平、阅读论文能力、读写代码能力较为有限。有错误,恳请大佬指正,感谢。
欢迎交流
邮箱:refreshmentccoffee@gmail.com

















 2634
2634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









