






目录
1.拷贝
1.1 浅拷贝
浅拷贝拷贝可变类型,只会对可变类型的最外层对象进行拷贝,生成新的引用地址,里面的元素是不会生成新的引用地址
# 可变类型: 列表 字典 和 集合(本身是可变类型,但是集合中的元素必须是不可变类型)
import copy
# 在python实现 浅拷贝,使用 模块 copy 模块, copy.copy(要拷贝的数据) 对数据进行浅拷贝
# 1. 浅拷贝拷贝可变类型 列表 (通过浅拷贝拷贝列表,拷贝出来的列表和原列表的引用地址 不一致)
my_list = [1,2,3]
# 对上述的列表进行拷贝
my_list1 = copy.copy(my_list)
# 观察一下 原列表 和现在的列表 关系,(引用地址是否一致)
print(f'my_list 的引用地址为: {id(my_list)}')
print(f'my_list1 的引用地址为: {id(my_list1)}')
my_list[1] = 666
print(f'my_list ===> {my_list}')
print(f'my_list1 ===> {my_list1}')
print('-'* 50)
# 如果列表里面元素又嵌套的是列表,那么使用浅拷贝的时候, 只会 拷贝 最外层的那个列表,生成新的引用地址
my_list2 = [[1,2], [3, 4]]
# 对上述嵌套的列表进行拷贝
my_list3 = copy.copy(my_list2)
# my_list3 和 my_list2 的引用地址 不一致的
print(f'mylist2 的引用地址: {id(my_list2)}')
print(f'mylist3 的引用地址: {id(my_list3)}')
print(f"my_list2[1] 的引用地址为: {id(my_list2[1])}")
print(f"my_list3[1] 的引用地址为: {id(my_list3[1])}")
my_list2[1][1] = 888
print(f"my_list2----> {my_list2}")
print(f"my_list3----> {my_list3}")
print('-'*50)
# 定义一个字典
my_dict = {"a":1, "b": 2}
my_dict1 = copy.copy(my_dict)
print(f"my_dict----的引用地址: {id(my_dict)}")
print(f"my_dict1----的引用地址: {id(my_dict1)}")
# 浅拷贝对 可变类型进行拷贝的时候,最外层的会生成一个新的引用地址,只会对可变类型的最外层的进行拷贝浅拷贝拷贝了 不可变类型,不会生成的新的引用地址
# 不可变类型: int float 字符串 元组 bool
import copy
# 1. 字符串
my_str = "hello"
my_str1 = copy.copy(my_str)
print(f'my_str 的引用地址 {id(my_str)}')
print(f'my_str1 的引用地址 {id(my_str1)}')
# 2. int
my_num = 1
my_num1 = copy.copy(my_num)
print(f'my_num-----> {id(my_num)}')
print(f'my_num1-----> {id(my_num1)}')
print('-' * 50)
# 浅拷贝 去拷贝不可变类型数据,没有生成新的引用地址。
my_tuple = (1, 2, 3)
my_tuple1 = copy.copy(my_tuple)
print(f'my_tuple-------> {id(my_tuple)}')
print(f'my_tuple1-------> {id(my_tuple1)}')
# 特殊
my_tuple2 = (1, 2, 3, [4, 5, 6])
my_tuple3 = copy.copy(my_tuple2)
print(f"t2 ------> {id(my_tuple2)}----> {id(my_tuple2[3])}")
print(f"t3 ------> {id(my_tuple3)}----> {id(my_tuple3[3])}")
1.2深拷贝
使用深拷贝要使用 函数 copy.deepcopy(要拷贝的对象)
深拷贝对可变类型进行拷贝,对每一层的可变类型进行拷贝,生成新的引用地址。
# 可变: 列表 字典 集合
import copy
my_list = [1, 2, 3]
# 丢上述的列表进行深拷贝
my_list1 = copy.deepcopy(my_list)
print(f'my_list =======> {id(my_list)}')
print(f'my_list1 =======> {id(my_list1)}')
# 嵌套关系的列表
my_list2 = [[1,2], [3,4], "abc"]
my_list3 = copy.deepcopy(my_list2)
print(f'my_list2 =======> {id(my_list2)}=====>{id(my_list2[2])}')
print(f'my_list3 =======> {id(my_list3)}=====>{id(my_list3[2])}')
# 结论:深拷贝:对每一层可变类型的对象 进行拷贝,生成新的引用地址
print('-'* 30)
my_dict = {"a":1, "b": [1,2,3]}
my_dict1 = copy.deepcopy(my_dict)
print(f"my_dict---> {id(my_dict)}---->{id(my_dict['b'])}")
print(f"my_dict1---> {id(my_dict1)}---->{id(my_dict1['b'])}")在不可变类型里面嵌套了可变类型的数据
会对可变类型的最外层以及每一层的可变类型数据生成新的引用地址
# int float bool str tuple
import copy
my_data = (1, 2, 3, [4, 5])
my_data1 = copy.deepcopy(my_data)
print(f'my_data-------> {id(my_data)}---->{id(my_data[3])}')
print(f'my_data1-------> {id(my_data1)}---->{id(my_data1[3])}')
# 使用深拷贝去拷贝 不可变类型,不会生成的新的引用地址。
# 但是 如果 不可变类型中嵌套了 可变类型的数据,那么 外层的不可变类型 以及 内层嵌套的 可变类型 的引用地址都会发生改变
# 都会生成新的引用地址
2.正则表达式
概念
记录文本规则的字符串,本质就是写了一个字符串。
如果想要从一段字符串中,将想要获取到的数据提取出来,或者想要去检验某个字符串是否符合某种规则,就可以使用正则表达式
2.1 re模块的基本使用
# 1. 导入模块
import re
# 准备一个字符串
my_str = "hello_python"
# 做一件时间,从字符串中将 hello提取出来
"""
pattern: 正则表达式规则的字符串
string: 要提取数据的字符串,要检验是否符合规则的字符串
flag : 标识符,
"""
# match方法,从头开始匹配内容,如果开头都不符合正则表达式,那么返回None,如果能匹配到返回的就是一个match对象
result = re.match(r"hello", my_str)
# print(result)
# 获取到匹配之后的结果, 可以使用 match.group() 如果没有匹配到 None ,
if result:
print(f"匹配到的结果为:{result.group()}")
else:
print('没有匹配到内容')
re.match方法
从头开始匹配内容,如果开头都不符合正则表达式,那么返回none,如果能匹配就返回一个match对象
参数
pattern
正则表达式规则的字符串
string
要提取数据的字符串,要检验是否符合规则的字符串
flag
标识符
re.search
扫描整个字符串,返回匹配到的第一个内容,匹配到返回match对象,可以使用match..group()获取匹配到的字符串,如果匹配不到就返回none
re.findall
扫描整个字符串,返回所有的匹配内容,返回一个列表。匹配不到返回一个空列表
re.sub(正则,新的字符串,旧的字符串,count)
根据正则表达式将匹配到的内容替换成新的字符。等同于方法:字符串.replace()
re.split(正则,字符串,count)
分割,根据正则匹配到的字符对整个字符串进行分割,返回列表
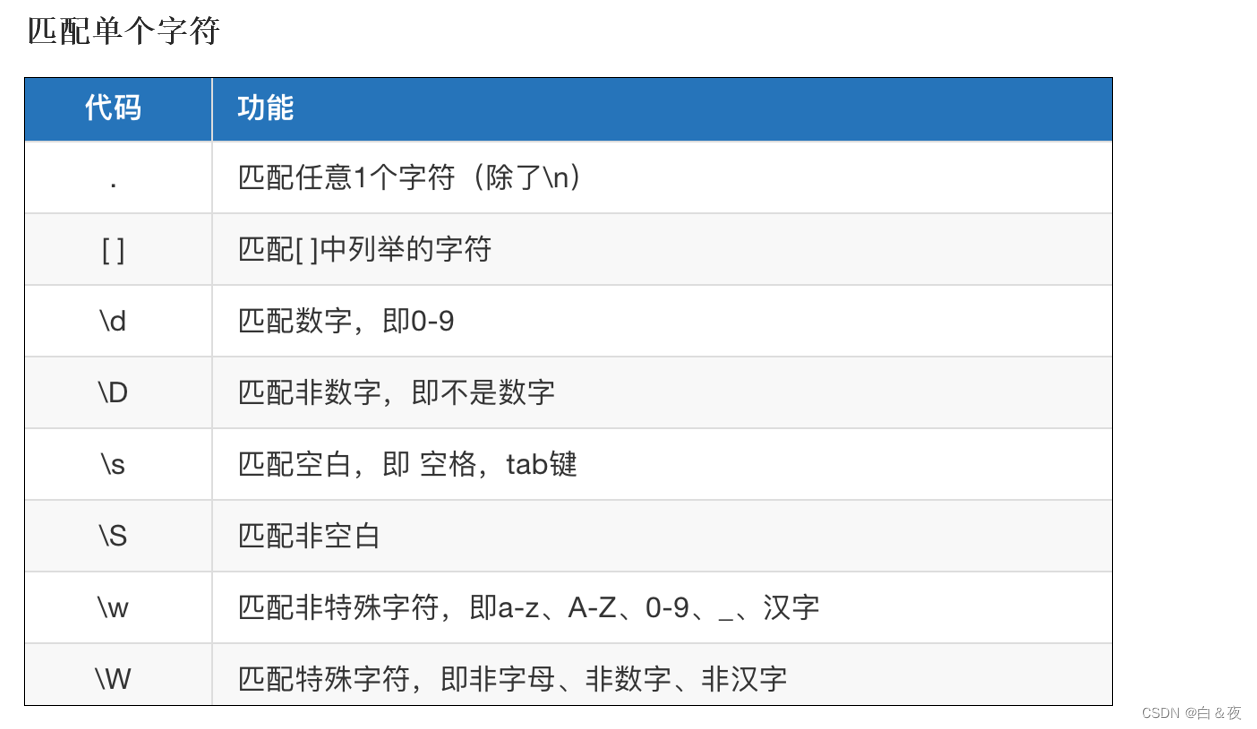
2.2 匹配单个字符
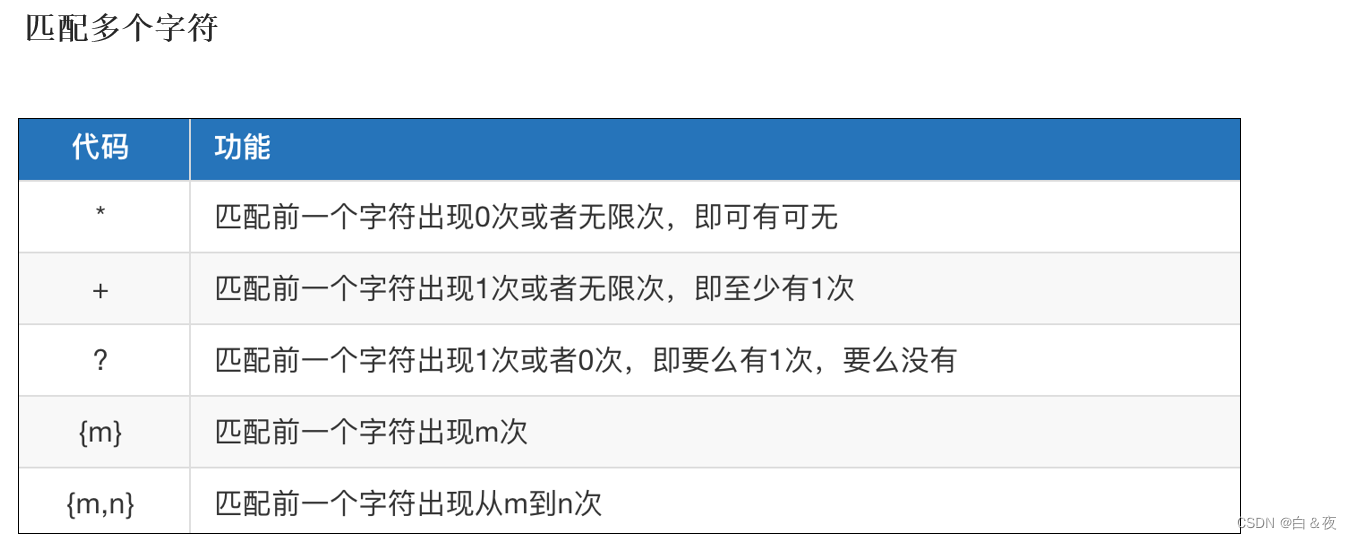
2.3 匹配多个字符
import re
my_str = "t11111o"
# 1. * 表示前一个字符出现 0次到无限次 可有可无
# result = re.match(r't\d*o', my_str)
# 2. + 表示前一个字符串 出现 1次到无限次,至少有一次
# result = re.match(r't\d+o', my_str)
# 3. ? 表示前一个字符串出现 1次或 0次,要么有1次,要么没有
# result = re.match(r't\d?o', my_str)
# 4. {num} 表示前一个字符 出现 num 次
# result = re.match(r't\d{5}o', my_str)
# 5. {m,n} 表示前一个字符串出现 m到n次 3,6 前一个字符可以出现:3 4 5 6 次
result = re.match(r't\d{3,6}o', my_str)
if result:
print(f'匹配到的内容为:{result.group()}')
else:
print('没有匹配到内容')2.4 匹配开头和结尾
字符串判断xxx开头xx结尾:
-
判断以xx开头: 字符串.startswith() 返回True 表示就是以xx开头,返回False不是。
-
判断以xx结尾: 字符串.endswith() 返回True 是以xx结尾,返回False就是不是

import re
# 要求,一个字符串,必须以数字开头,并且这个字符串要求 5-8位
# \d 匹配一个字符 要求 剩下 4-7位 11111111
# ^ 表示匹配以某个字符开头
# result = re.match(r"^\d\S{4,7}", "1abcdeio")
# 匹配以某个字符结尾: 一个字符串,必须以数字开头,并且这个字符串要求 5-8位, 必须以数字结尾
# $ 表示匹配某个字符结尾
# result = re.match(r"^\d\S{3,6}\d$", "1abcde")
# ^ 表示以某个字符开头, 如果将 ^ 放到 [] 中使用,表示取反
result = re.match(r'[^\D]', "1")
if result:
print(f'匹配到的内容为:{result.group()}')
else:
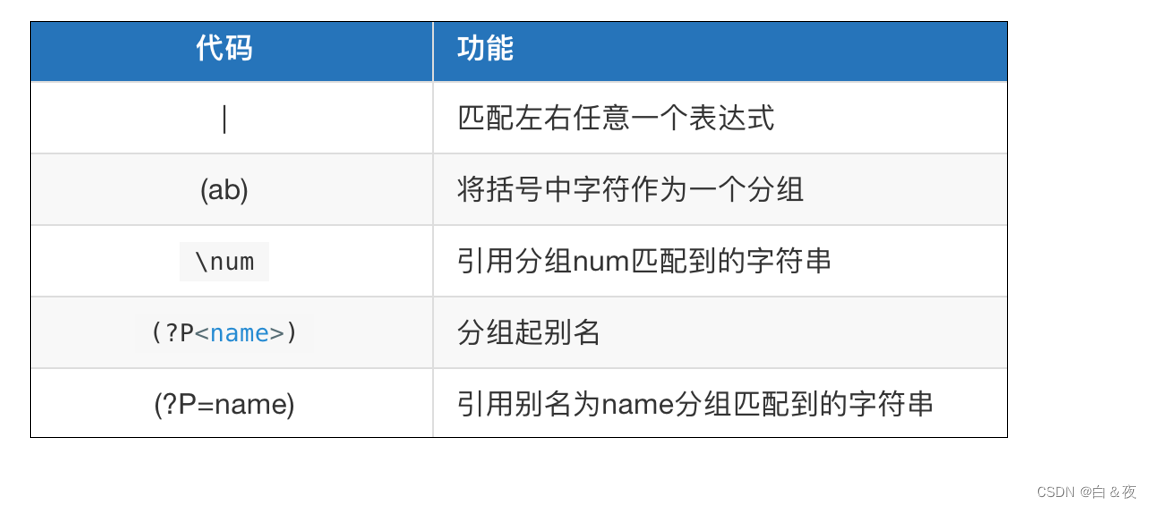
print('没有匹配到内容')2.5 匹配分组
# 在列表中["apple", "banana", "orange", "pear"],
# 匹配apple和pear
# 1. 正则1|正则2 表示匹配|左右任意一个正则。|
import re
# my_list = ["apple", "banana", "orange", "pear"]
#
# for fruit in my_list:
# result = re.match(r'apple|pear', fruit)
# if result:
# print(f'{result.group()}')
#
# print(re.match(r"abc|cba", "cba").group())
# xxxxxxx@qq、163、sina等等等.com @前面是一部分,@到. 是一部分,最后 com cn
# 第一部分规则: 数字 字母 下划线 5-20位
# @
# 第二部分的规则: qq 163 sina 126
# .
# 第三部分 com
# (正则) 就是一个分组。只要看到() 表示就是分组,分组是有编号的。 从1开始
result = re.match(r'([0-9A-Za-z_]{5,20})@(qq|163|sina|126)\.com', "12345678@qq.com")
# match.group() 里面什么都不传,表示获取到 完整的结果, group(组号) 获取某一个分组中匹配到的结果
if result:
print(f'匹配到的内容为:{result.group()}')
else:
print('没有匹配到内容')import re
my_str = "<h1>这个是一级标题</h1>"
# \num num 表示的是分组的编号, 表示去引用某个分组匹配到的字符串
# result = re.match(r'<(\S*)>(\w*)</\1>', my_str)
# (\S*) 可以将他理解为 一个变量 这个变量的值 是 (\S*) = "h1" 给这个变量 指定了一个编号 1
# </h1> 构造一个字符串 </h1> ----> </(\S*)> ----> </\1>
# 2. 给分组起别名, (?P<别名>正则表达式)
# result = re.match(r'<(?P<ha>\S*)>(?P<content>\w*)</\1>', my_str)
# 3. 引用分组别名,去使用分组中匹配到的字符串, 类似于 \num (?P=分组别名) 引用分组匹配到的字符串
result = re.match(r'<(?P<ha>\S*)>(?P<content>\w*)</(?P=ha)>', my_str)
if result:
print(f'匹配到的内容为:{result.group()}')
else:
print('没有匹配到内容')














 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









