







这是本人的学习过程,看到的同道中人祝福你们心若有所向往,何惧道阻且长;
但愿每一个人都像星星一样安详而从容的,不断沿着既定的目标走完自己的路程;
最后想说一句君子不隐其短,不知则问,不能则学。
如果大家觉得我写的还不错的话希望可以收获关注、点赞、收藏(谢谢大家)
一、SparkStreaming概述
1.1 SparkStreaming是什么
SparkStreaming用于流式数据的处理。
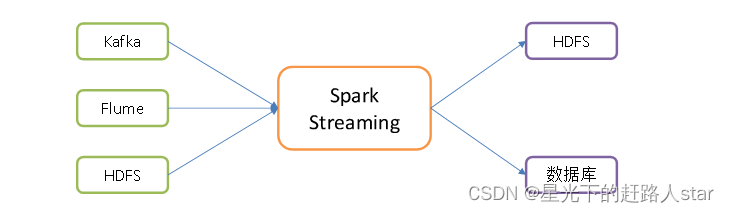
(1)SparkS支持的数据输入源很多,例如kafka、Flume、HDFS等。
(2)数据输入可以用Spark的高度抽象原语如:map、Reduce、join、Window等进行运算
(3)而且结果也能保存在很多地方,例如HDFS、数据库等。
1.2 SparkStreaming架构原理
1.2.1 什么是DStream
SparkCore==>RDD
SparkSQL==>DataFrame、DataSet
SparkStreaming使用离散化流作为抽象表示,叫作DStream
DStream是随时间推移而受到的数据序列
在DStream是随时间推移而收到的数据都作为RDD存在,而DStream是由这些RDD所组成的序列(因此被称为离散化)。
所以,简单来说,DStream就是对RDD的实时数据处理场景的一种封装。

1.2.2 架构图
1、整体架构图
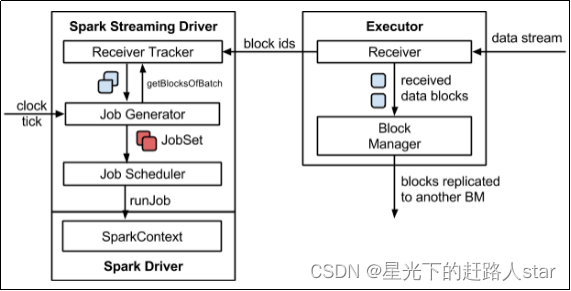
2、SparkStreaming架构图
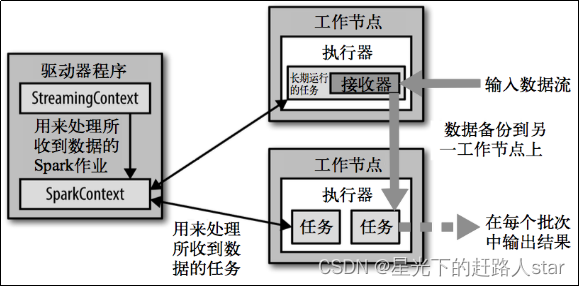
1.2.3 背压机制
1、Spark1.5 以前的版本:
用户可以通过设置静态配置参数“spark.streaming.receiver.maxRate”的值来限制Receiver的数据接收速率。
优点:此举虽然可以通过限制接收速率,来适配当前的处理能力,防止内存溢出,但也会引入其它问题。
缺点:producer数据生产高于maxRate,当前集群处理能力也高于maxRate,这就会造成资源利用率下降等问题。
2、1.5版本及以后版本
Spark Streaming可以动态控制数据接收速率来适配集群数据处理能力。
背压机制(SparkStreaming Backpressure):
更具JobScheduler反馈作业的执行信息来动态调整Receiver数据接受率。
通过属性“spark.streaming.backpressure.enabled”来控制是否启用背压机制,默认值是false,即不启用。
1.3 SparkStreaming特点
1、易用
2、容错
3、易整合到Spark体系
二、DStream入门
2.1 WordCount案例实操
1、需求:使用netcat工具向9999端口不断的发送数据,通过SparkStreaming读取端口数据并统计不同单词出现的次数。
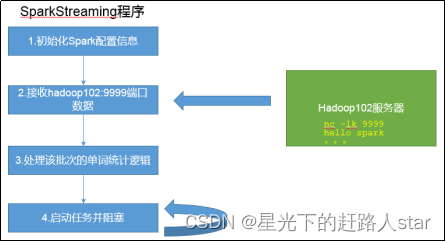
2、添加依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
3、编写代码
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test01_wordCount
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/3 20:49
* @Version 1.0
*/
public class Test01_wordCount {
public static void main(String[] args) throws InterruptedException {
//TODO 第一步 创建SparkConf对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test01_wordCount");
//TODO 第二步 创建JavaStreamingContext对象,并设置批次时间
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(3L));
//TODO 第三步 地读取数据开始业务逻辑计算
//1、对接数据源获取数据
JavaReceiverInputDStream<String> lineDStream = ssc.socketTextStream("hadoop102", 44444);
//2、切分
JavaDStream<String> flatMapDStream = lineDStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.asList(s.split(" ")).iterator();
}
});
//3、转换word->(word,1)
JavaPairDStream<String, Integer> javaPairDStream = flatMapDStream.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//4、统计单词个数
JavaPairDStream<String, Integer> reduceByKeyDStream = javaPairDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//5、输出结果
reduceByKeyDStream.print();
//TODO 第四步 启动阻塞进程
ssc.start();
ssc.awaitTermination();
}
}
4、更改日志打印级别
如果不希望运行时打印大量日志,可以在resources文件夹中添加log4j2.properties文件,并添加日志配置信息。
# Set everything to be logged to the console
rootLogger.level = ERROR
rootLogger.appenderRef.stdout.ref = console
# In the pattern layout configuration below, we specify an explicit `%ex` conversion
# pattern for logging Throwables. If this was omitted, then (by default) Log4J would
# implicitly add an `%xEx` conversion pattern which logs stacktraces with additional
# class packaging information. That extra information can sometimes add a substantial
# performance overhead, so we disable it in our default logging config.
# For more information, see SPARK-39361.
appender.console.type = Console
appender.console.name = console
appender.console.target = SYSTEM_ERR
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n%ex
# Set the default spark-shell/spark-sql log level to WARN. When running the
# spark-shell/spark-sql, the log level for these classes is used to overwrite
# the root logger's log level, so that the user can have different defaults
# for the shell and regular Spark apps.
logger.repl.name = org.apache.spark.repl.Main
logger.repl.level = warn
logger.thriftserver.name = org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver
logger.thriftserver.level = warn
# Settings to quiet third party logs that are too verbose
logger.jetty1.name = org.sparkproject.jetty
logger.jetty1.level = warn
logger.jetty2.name = org.sparkproject.jetty.util.component.AbstractLifeCycle
logger.jetty2.level = error
logger.replexprTyper.name = org.apache.spark.repl.SparkIMain$exprTyper
logger.replexprTyper.level = info
logger.replSparkILoopInterpreter.name = org.apache.spark.repl.SparkILoop$SparkILoopInterpreter
logger.replSparkILoopInterpreter.level = info
logger.parquet1.name = org.apache.parquet
logger.parquet1.level = error
logger.parquet2.name = parquet
logger.parquet2.level = error
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
logger.RetryingHMSHandler.name = org.apache.hadoop.hive.metastore.RetryingHMSHandler
logger.RetryingHMSHandler.level = fatal
logger.FunctionRegistry.name = org.apache.hadoop.hive.ql.exec.FunctionRegistry
logger.FunctionRegistry.level = error
# For deploying Spark ThriftServer
# SPARK-34128: Suppress undesirable TTransportException warnings involved in THRIFT-4805
appender.console.filter.1.type = RegexFilter
appender.console.filter.1.regex = .*Thrift error occurred during processing of message.*
appender.console.filter.1.onMatch = deny appender.console.filter.1.onMismatch = neutral
5、启动程序并通过netcat发送数据(nc 再启动IEDA程序):
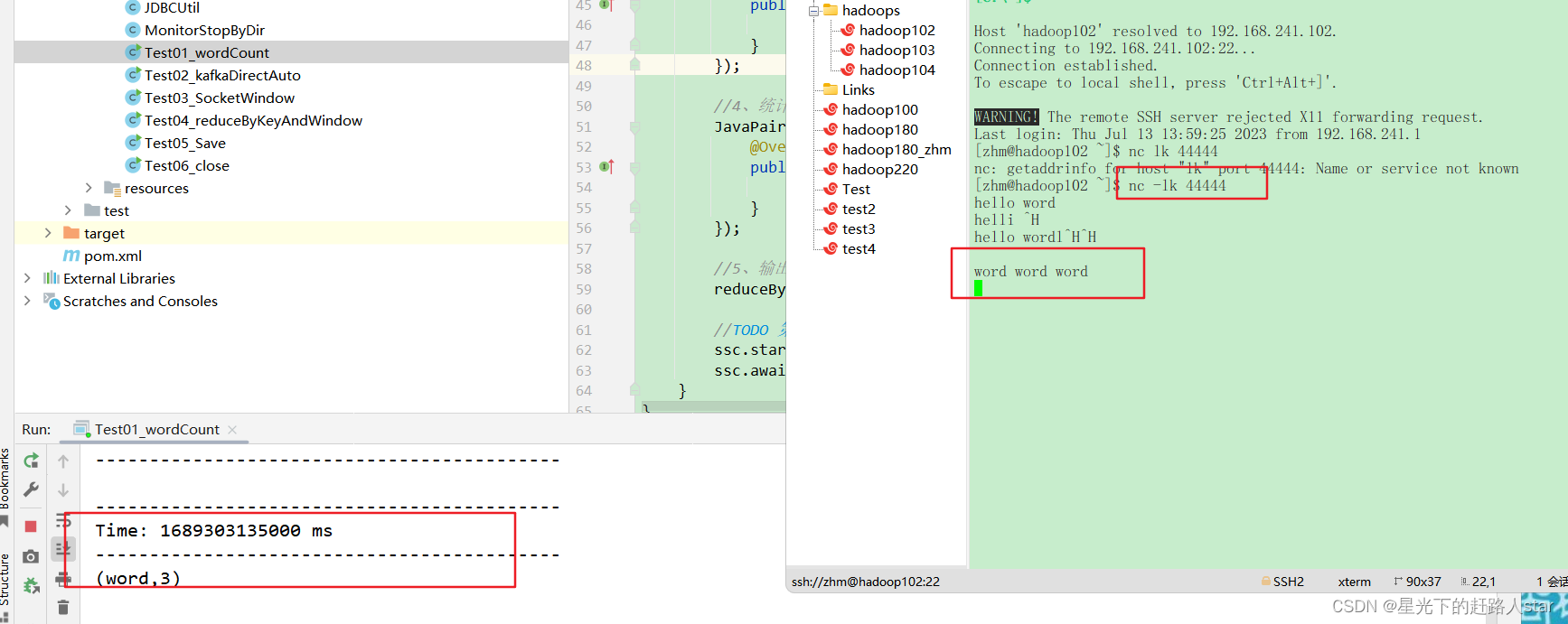
2.2 WordCount解析
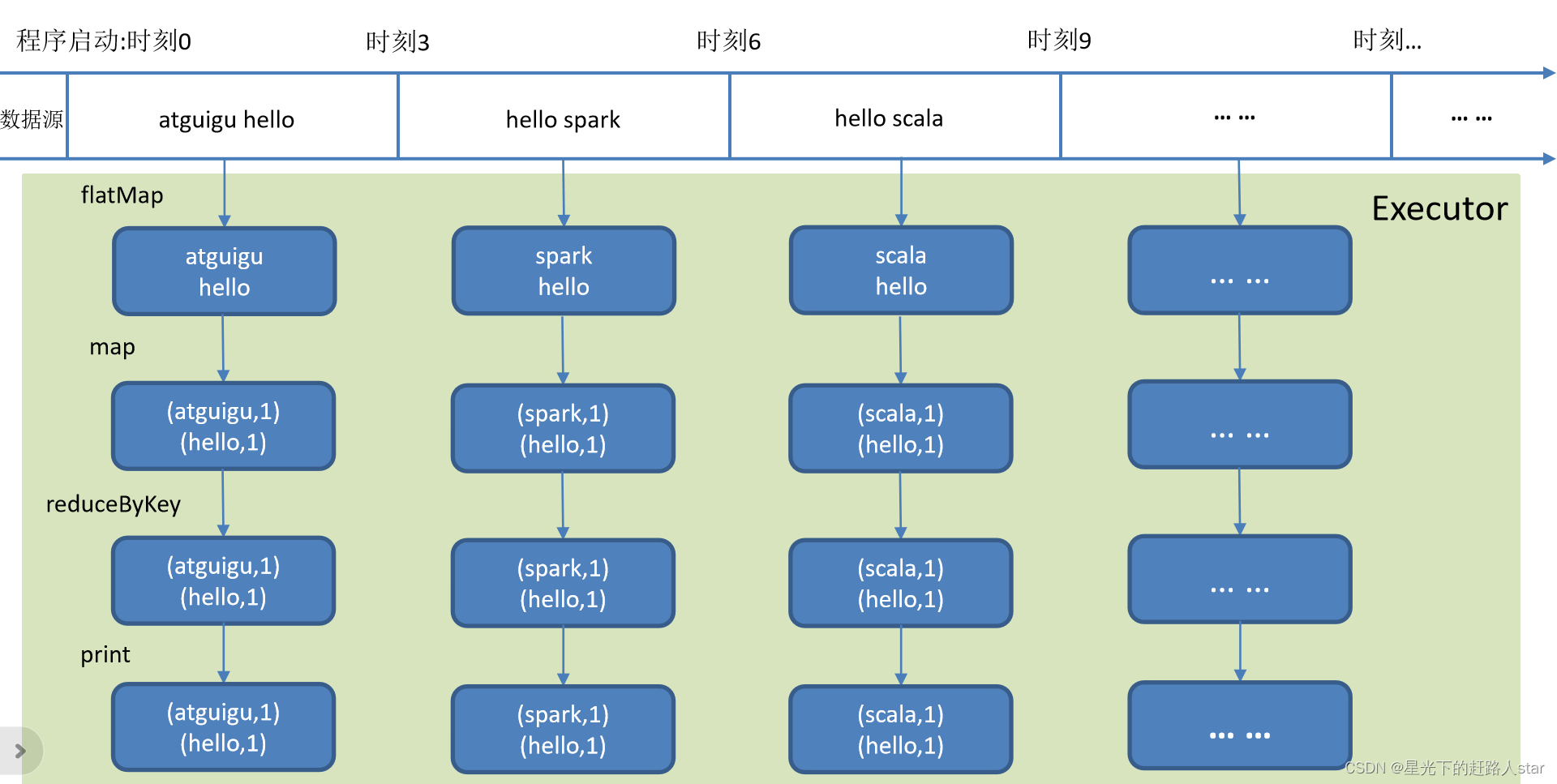
在SparkStreaming中,DataStream是基础抽象,代表这数据流和经过算子计算的结果流。SparkStreaming仍然是基于批处理的思想来处理流式数据的,在内部实现上,将每一批次的数据疯转为一个RDD,DStream就是一系列RDD的封装,接下来就是Spark引擎来对这些RDD进行转换。DStream中批次与批次之间计算相互独立。
3、kafka数据源
3.1 版本选型
1、ReceiverAPI:需要一个专门的Executor去接受数据,然后发生给其他的Executor做计算。
存在的问题:接受数据的Executor和计算的Executor速度会有所不同,特别在接受数据的Executor速度大于计算的Executor速度,会导致计算数据的节点内存溢出。
2、DirectAPI:是由计算的Executor来主动消费kafka的数据,速度由自身控制。
3.2 对接Kafka数据源
1、需求:通过SparkStreaming读取kafka某个主题的数据并输出打印到控制台。
2、添加依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.3.0</version>
</dependency>
</dependencies>
3、编写代码
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.common.protocol.types.Field;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.*;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Iterator;
/**
* @ClassName Test02_kafkaDirectAuto
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/3 21:05
* @Version 1.0
*/
public class Test02_kafkaDirectAuto {
public static void main(String[] args) throws InterruptedException {
//1、创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test02_kafkaDirectAuto");
//2、创建JavaStreamingContext对象
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(3L));
//3、业务逻辑
//4、定义要消费的kafka主题
ArrayList<String> topics = new ArrayList<>();
topics.add("first");
//5、定义kafka消费者配置以及创建消费者策略
HashMap<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
kafkaParams.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
kafkaParams.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,StringDeserializer.class.getName());
kafkaParams.put(ConsumerConfig.GROUP_ID_CONFIG,"ssID");
kafkaParams.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"latest");
ConsumerStrategy<Object, Object> consumerStrategy = ConsumerStrategies.Subscribe(topics, kafkaParams);
//6、对接kafka
JavaInputDStream<ConsumerRecord<Object, Object>> kafkaDStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent(), consumerStrategy);
//7、转换数据结构 consumerRecord==》consumerRecord.value
JavaDStream<String> lineDStream =kafkaDStream.map(new Function<ConsumerRecord<Object, Object>, String>() {
@Override
public String call(ConsumerRecord<Object, Object> v1) throws Exception {
return v1.value().toString();
}
});
//8、切分数据
JavaDStream<String> flatMapDStream = lineDStream.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String s) throws Exception {
return Arrays.stream(s.split(" ")).iterator();
}
});
//9、转换数据结构 word->(word,1)
JavaPairDStream<String, Integer> mapToPairDStream = flatMapDStream.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2<>(s, 1);
}
});
//10、按照key进行聚合value
JavaPairDStream<String, Integer> reduceByKeyDStream = mapToPairDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//11、打印结果输出流
reduceByKeyDStream.print();
//x. 启动并阻止线程
ssc.start();
ssc.awaitTermination();
}
}
运行结果
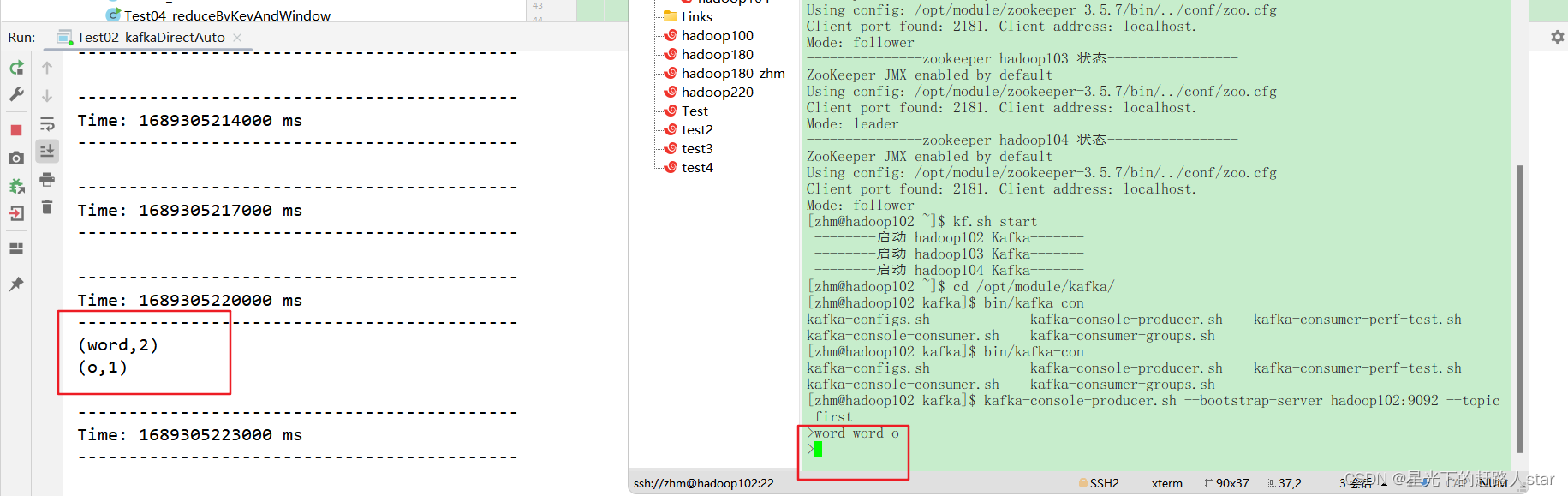
4、DStream转换
DStream上的操作和RDD类型,分为转换和输出两种类型,此外转换操作中还有一些比较特殊的原语,如:transform()以及各种Window相关的原语。
4.1 无状态转换操作
无状态转换操作就是把RDD转换操作应用到DStream每个批次上,每个批次相互独立,自己算自己的。
4.1.1 常规无状态转换操作
DStream的部分无状态转换操作列表
| 函数名称 | 目的 | 函数类型 |
|---|---|---|
| map() | 对DStream中的每个元素应用给定函数,返回有各元素输出的元素组成的DStream | Function<in,out> |
| flatMap() | 对DStream中的每个元素应用给定函数,返回由各元素输出的迭代器组成的DStream | FlatMapFunction<in,out> |
| filter() | 返回由给定DStream中通过筛选的元素组成的DStream | Function<in,Boolean> |
| mapToPair() | 改变DStream的分区数 | PairFunction<in,key,value> |
| reduceByKey() | 将每个批次中键相同的记录规约 | Function2<in,in,in> |
需要注意的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD批次组成,且无状态转换操作是分别应用到每个RDD(应该批次的数据)上。
4.2 窗口操作
4.2.1 WindowOperations
1、Window Operations:可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Streaming的允许状态。
2、参数:所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长。
(1)窗口时长:计算内容的时间范围
(2)滑动步长:隔多久触发一次计算
注意:这两者都必须为采集批次大小的整数倍。

4.2.2 Window
1、基本语法
window(windowLength, slideInterval): 基于对源DStream窗口的批次进行计算返回一个新的DStream。
2、 需求:统计WordCount:3秒一个批次,窗口6秒,滑步3秒。
3、代码实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test03_SocketWindow
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/3 21:27
* @Version 1.0
*/
public class Test03_SocketWindow {
public static void main(String[] args) throws InterruptedException {
//1、创建SparkConf配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test03_SocketWindow");
//2、创建JavaStreamingContext对象,并且设置批次时间
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(3L));
//3、编写业务逻辑
// 3.1 对接数据源,获取数据
JavaReceiverInputDStream<String> linesDStream = ssc.socketTextStream("hadoop102", 44443);
// 3.2 切分数据并转换为kv
JavaPairDStream<String, Integer> wordOneDStream = linesDStream.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
Iterator<String> iterator = Arrays.asList(s.split(" ")).iterator();
ArrayList<Tuple2<String, Integer>> resultList = new ArrayList<>();
while (iterator.hasNext()) {
resultList.add(new Tuple2<>(iterator.next(), 1));
}
return resultList.iterator();
}
});
//3.3 添加窗口:窗口大小6s,滑动步长为3s
JavaPairDStream<String, Integer> windowDStream = wordOneDStream.window(Duration.apply(6000L), Duration.apply(3000L));
//3.4 对开窗的数据流进行窗口计算
JavaPairDStream<String, Integer> reduceByKeyDStream = windowDStream.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
//3.5打印结果流
reduceByKeyDStream.print();
//4、启动并阻塞线程
ssc.start();
ssc.awaitTermination();
}
}
运行结果:
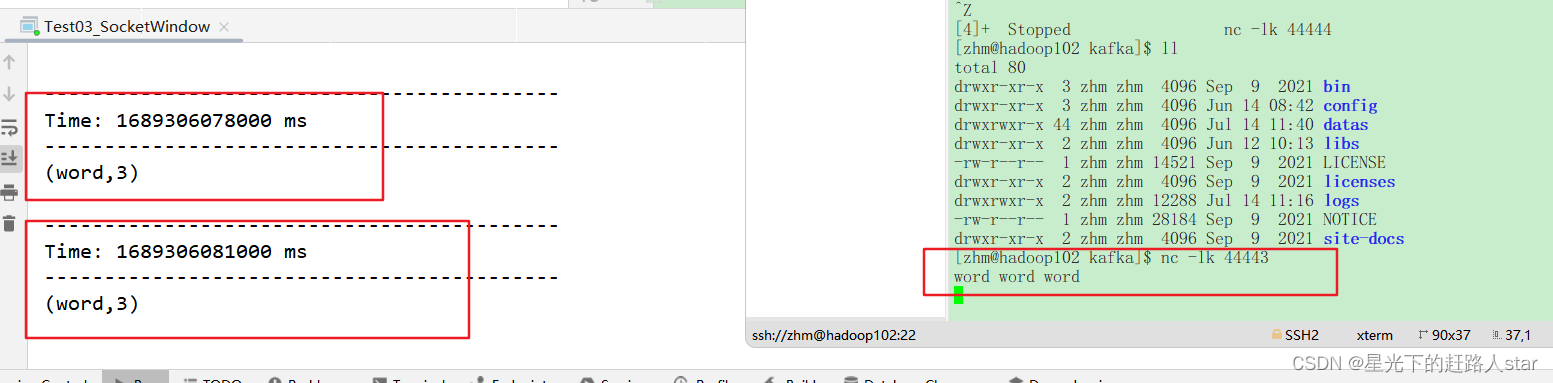
因为添加了窗口,所以控制台打印了两次。
4、如果有多批数据进入窗口,最终也会通过window操作变成统一的RDD处理。
4.2.3 reduceByKeyAndWindow
1、基本语法
reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]):
当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。
2、需求:统计WordCount:3秒一个批次,窗口6秒,滑步3秒。
3、代码编写
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test04_reduceByKeyAndWindow
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/4 9:29
* @Version 1.0
*/
public class Test04_reduceByKeyAndWindow {
public static void main(String[] args) throws InterruptedException {
//1、创建sparkConf配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test04_reduceByKeyAndWindow");
//2、创建JavaStreamingContext对象,并设置批次时间
JavaStreamingContext ssc = new JavaStreamingContext(conf, Duration.apply(3000L));
//3、业务逻辑
//3.1 对接数据源,获取数据
JavaReceiverInputDStream<String> lineDStream = ssc.socketTextStream("hadoop102", 44442);
//3.2 切分数据并转换为kv
JavaPairDStream<String, Integer> flatMapToPairDStream = lineDStream.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
Iterator<String> iterator = Arrays.stream(s.split(" ")).iterator();
ArrayList<Tuple2<String, Integer>> result = new ArrayList<>();
while (iterator.hasNext()) {
result.add(new Tuple2<>(iterator.next(), 1));
}
return result.iterator();
}
});
//3.3 对数据流直接开窗计算
JavaPairDStream<String, Integer> resultDStream = flatMapToPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}, Duration.apply(6000L), Duration.apply(3000L));
//3.4 打印结果流
resultDStream.print();
//4、启动并阻塞线程
ssc.start();
ssc.awaitTermination();
}
}
运行结果:
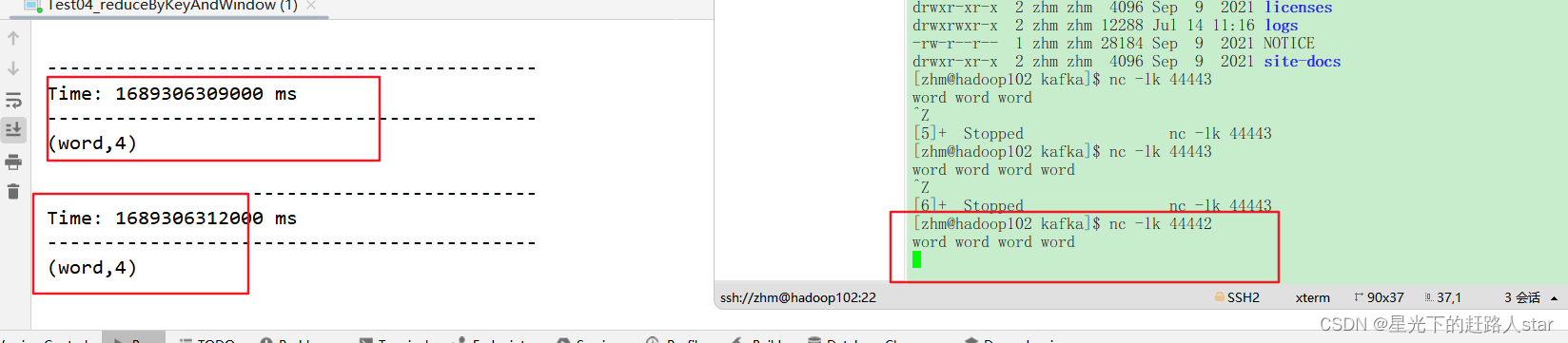
因为添加了窗口,所以控制台打印了两次。
5、DStream输出
DStream通常将数据输出到外部数据库或屏幕上。
DStream与RDD中的惰性求值类似,如果一个DStream及派生出的DStream都没有执行输出操作,那么这些DStream就都不会被求值。如果StreamingContext中没有设定输出操作,整个Context就都不启动。
1、输出操作API如下:
| saveAsTextFiles(prefix, [suffix]) | 以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。“prefix-Time_IN_MS[.suffix]”注意:以上操作都是每一批次写出一次,会产生大量小文件,在生产环境,很少使用 |
| print() | 在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试 |
| foreachRDD(func) | 即将函数func用于产生DStream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者写入数据库这是最通用的输出操作 |
在企业开发操作中通常采用foreachRDD(),它用来对DStream中的RDD进行任意计算。可以让我们访问任意的RDD。在foreachRDD()中,可以重用在Spark中实现的所以行动算子操作(action算子)。
2、案例需求:将端口数据流进行窗口计算,并将结果输出到mysql的test_result库中的result表中。
3、编写数据库连接工具类JDBCUtil
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
/**
* @ClassName JDBCUtil
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/4 9:55
* @Version 1.0
*/
public class JDBCUtil {
public static Connection connection;
public static Connection getConnection(String user,String password){
try {
//1、加载驱动类
Class.forName("com.mysql.jdbc.Driver");
connection= DriverManager.getConnection("jdbc:mysql://hadoop102:3306/test_result?useSSL=false&useUnicode=true&characterEncoding=UTF-8",
user,
password);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
} catch (SQLException e) {
throw new RuntimeException(e);
}
return connection;
}
}
4、编写主类Test05_save对端口数据进行窗口计算并存储到MySQL中
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test05_Dave
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/4 9:58
* @Version 1.0
*/
public class Test05_Save {
/**
*① 连接不能写在Driver层面(序列化)
* ② 如果写在foreach则每个RDD中的每一条数据都创建,得不偿失;
* ③ 增加foreachPartition,在分区创建(获取)
*/
public static void main(String[] args) throws InterruptedException {
//1、创建SparkConf配置对象
SparkConf conf = new SparkConf();
conf.setMaster("local[*]");
conf.setAppName("Test05_Save");
//2、创建JavaStreamContext对象,并设置批次时间
JavaStreamingContext ssc = new JavaStreamingContext(conf, Duration.apply(3000L));
//3、读取数据开始业务逻辑计算
//3.1 对接数据源
JavaReceiverInputDStream<String> lineDStream = ssc.socketTextStream("hadoop102", 44442);
//3.2 切分并转换为kv
JavaPairDStream<String, Integer> flatMapToPairDStream = lineDStream.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
Iterator<String> iterator = Arrays.stream(s.split(" ")).iterator();
ArrayList<Tuple2<String, Integer>> resultList = new ArrayList<>();
while (iterator.hasNext()) {
resultList.add(new Tuple2<>(iterator.next(), 1));
}
return resultList.iterator();
}
});
//3.3 按照key聚合value
JavaPairDStream<String, Integer> resultDStream = flatMapToPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}, Duration.apply(6000L), Duration.apply(3000L));
//3.4 将数据保存到mysql中
resultDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> stringIntegerJavaPairRDD) throws Exception {
stringIntegerJavaPairRDD.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> tuple2Iterator) throws Exception {
//TODO 在此处可创建JDBC连接,可在每个分区创建一个连接后,同一个分区重复使用
//3.4.1 创建数据库连接对象
Connection connection = JDBCUtil.getConnection("root", "123456");
//3.4.2 编写sql语句
String sql="insert into result values(?,?);";
//3.4.3 预编译sql语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3.4.4 结果数据集储存到MySQL中
while (tuple2Iterator.hasNext()){
//3.4.5 获取数据
Tuple2<String, Integer> valueKV = tuple2Iterator.next();
preparedStatement.setString(1,valueKV._1);
preparedStatement.setInt(2,valueKV._2);
//3.4.6 执行sql
preparedStatement.execute();
}
//3.4.7关闭资源
connection.close();
}
});
}
});
//4、启动并阻塞线程
ssc.start();
ssc.awaitTermination();
}
}
运行结果:
输入

输出(MySQL中的数据)

注意:因为是开窗了所以有两份。
5、总结
(1)连接不能写在Driver层面(序列化)
(2)如果写在foreach则每个RDD中的每条数据都创建
(3)增加foreachPartition,在分区创建
6、优雅关闭
流式任务需要7*24小时执行,但是有时涉及到升级代码需要主动停止程序,但是分布式程序,没办法做到一个个进程去杀死,所以配置优雅的关闭就显得至关重要了。
关闭方式:创建子线程,在子线程中监听指定路径,如果出现目标文件夹(stopSpark)就控制内部程序关闭。
1、主程序
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFlatMapFunction;
import org.apache.spark.api.java.function.VoidFunction;
import org.apache.spark.streaming.Duration;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Iterator;
/**
* @ClassName Test06_close
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/4 10:46
* @Version 1.0
*/
public class Test06_close {
public static void main(String[] args) throws InterruptedException {
//1、创建SparkConf对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("Test06_close");
//2、创建JavaStreamingContext对象并设置批次时间
JavaStreamingContext ssc = new JavaStreamingContext(conf, Duration.apply(3000L));
//3、业务逻辑
//3.1 对接数据源
JavaReceiverInputDStream<String> lineDStream = ssc.socketTextStream("hadoop102", 44441);
//3.2 切分并转换为kv
JavaPairDStream<String, Integer> flatMapToPairDStream = lineDStream.flatMapToPair(new PairFlatMapFunction<String, String, Integer>() {
@Override
public Iterator<Tuple2<String, Integer>> call(String s) throws Exception {
Iterator<String> iterator = Arrays.stream(s.split(" ")).iterator();
ArrayList<Tuple2<String, Integer>> resultList = new ArrayList<>();
while (iterator.hasNext()) {
resultList.add(new Tuple2<>(iterator.next(), 1));
}
return resultList.iterator();
}
});
//3.3 按照key聚合value
JavaPairDStream<String, Integer> resultDStream = flatMapToPairDStream.reduceByKeyAndWindow(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}, Duration.apply(6000L), Duration.apply(3000L));
//3.4 将结果保存到mysql中
resultDStream.foreachRDD(new VoidFunction<JavaPairRDD<String, Integer>>() {
@Override
public void call(JavaPairRDD<String, Integer> stringIntegerJavaPairRDD) throws Exception {
stringIntegerJavaPairRDD.foreachPartition(new VoidFunction<Iterator<Tuple2<String, Integer>>>() {
@Override
public void call(Iterator<Tuple2<String, Integer>> tuple2Iterator) throws Exception {
//TODO 在此处可创建JDBC连接,可在每个分区创建一个JDBC连接对象后,重复使用
//3.4.1 创建数据库对象
Connection connection = JDBCUtil.getConnection("root", "123456");
//3.4.2 编写sql语句
String sql="insert into result values(?,?);";
//3.4.3 预编译sql语句
PreparedStatement preparedStatement = connection.prepareStatement(sql);
//3.4.4 将结果集储存到MySQL中
while (tuple2Iterator.hasNext()){
//3.4.5 获取数据
Tuple2<String, Integer> next = tuple2Iterator.next();
//3.4.6 向sql语句传参
preparedStatement.setString(1, next._1);
preparedStatement.setInt(2, next._2);
//3.4.7 执行sql语句
preparedStatement.execute();
}
connection.close();
}
});
}
});
//TODO 启动监控线程
new Thread(new MonitorStopByDir(ssc)).start();
//4、启动并阻塞线程
ssc.start();
ssc.awaitTermination();
}
}
2、编辑监听类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.spark.streaming.StreamingContextState;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @ClassName MonitorStopByDir
* @Description TODO
* @Author Zouhuiming
* @Date 2023/7/4 10:58
* @Version 1.0
*/
public class MonitorStopByDir implements Runnable{
private JavaStreamingContext ssc=null;
public MonitorStopByDir(JavaStreamingContext ssc) {
this.ssc = ssc;
}
/**
* 监控程序:当指定的hdfs根目录下出现stopSpark文件夹,就停止ssc
*/
@Override
public void run() {
try {
//1、获取hdfs文件对象
FileSystem fileSystem = FileSystem.get(new URI("hdfs://hadoop102:8020"), new Configuration(), "zhm");
//2、轮询
while (true){
Thread.sleep(5000);
boolean isStop = fileSystem.exists(new Path("/stopSpark"));
if (isStop){
if (ssc.getState()== StreamingContextState.ACTIVE){
ssc.stop(true,true);
System.exit(0);
}
}
}
} catch (IOException e) {
throw new RuntimeException(e);
} catch (URISyntaxException e) {
throw new RuntimeException(e);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
3、测试
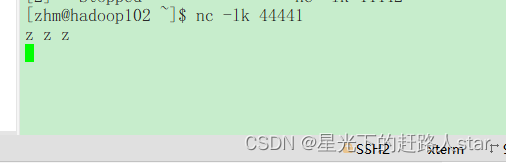
(1)发送数据
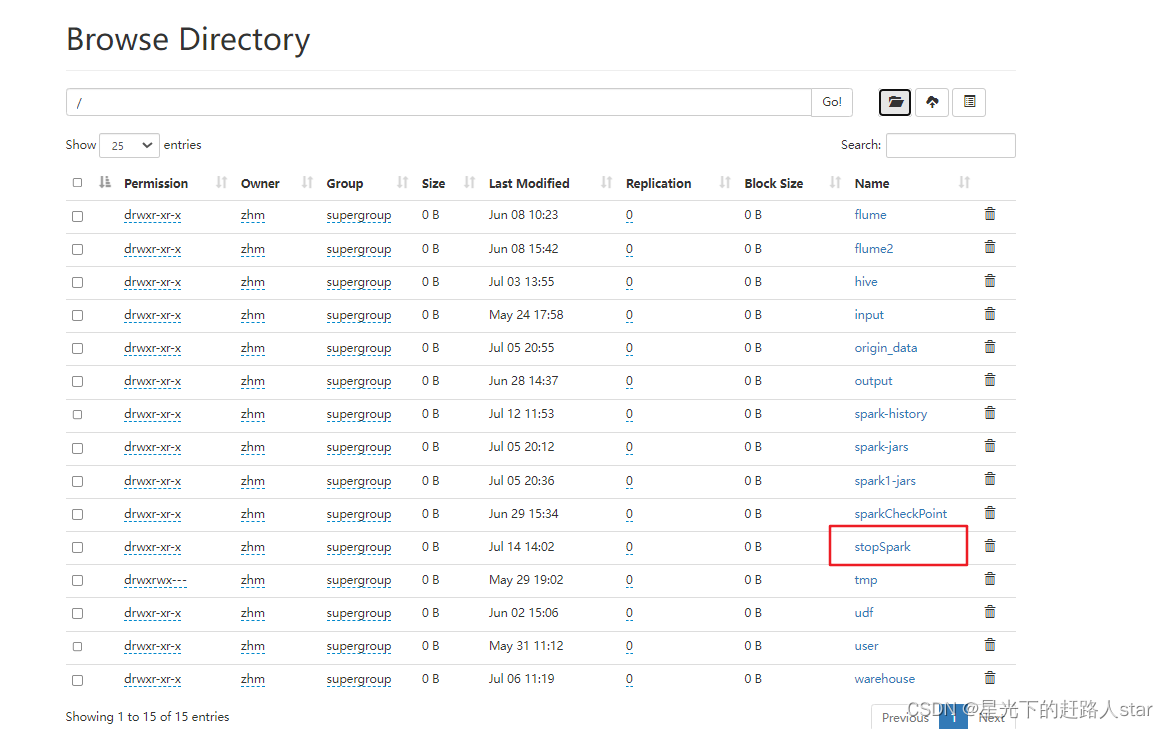
(2)启动Hadoop集群,并且创建目录/stopSpark
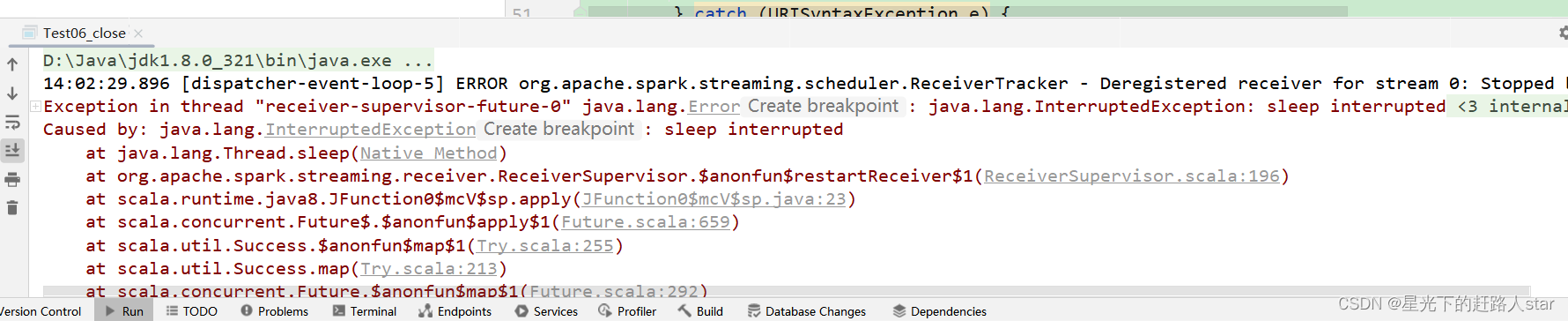
(3)IDEA控制台
恭喜大家看完了小编的博客,希望你能够有所收获,我一直相信躬身自问和沉思默想会充实我们的头脑,希望大家看完之后可以多想想喽,编辑不易,求关注、点赞、收藏(Thanks♪(・ω・)ノ)。















 8419
8419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











