







⚠申明: 未经许可,禁止以任何形式转载,若要引用,请标注链接地址。 全文共计6444字,阅读大概需要10分钟
🌈更多学习内容, 欢迎👏关注👀【文末】我的个人微信公众号:不懂开发的程序猿
⏰个人网站:https://jerry-jy.co/❗❗❗知识付费,🈲止白嫖,有需要请后台私信或【文末】个人微信公众号联系我
基于Python实现ChiMerge算法对鸢尾花数据进行离散化
基于Python实现ChiMerge算法对鸢尾花数据进行离散化
实验目录
- 基于Python实现ChiMerge算法对鸢尾花数据进行离散
实验内容 - 基于Python实现ChiMerge算法对鸢尾花数据进行离散
知识点
- ChiMerge 是监督的、自底向上的(即基于合并的)数据离散化方法。它依赖于卡方分析:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则,基本思想:对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
实验目的
- 利用ChiMerge完成对鸢尾花数据的离散化
实验环境
- Oracle Linux 7.4
- Python 3
任务实施过程
1.打开Jupyter,并新建python工程
1.桌面空白处右键,点击Konsole打开一个终端
2.切换至/experiment/jupyter目录
cd experiment/jupyter
3.启动Jupyter,root用户下运行需加–allow-root
jupyter notebook --ip=127.0.0.1 --allow-root

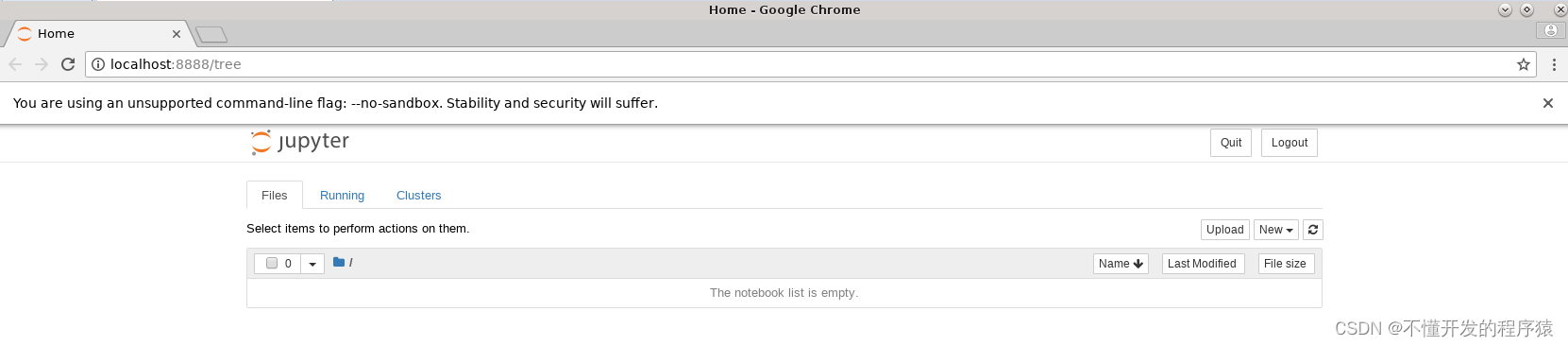
4.依次点击右上角的 New,Python 3新建python工程
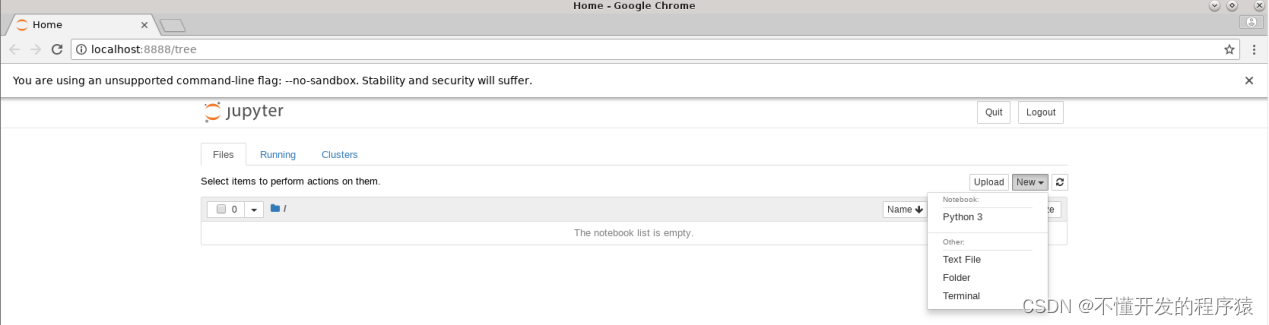
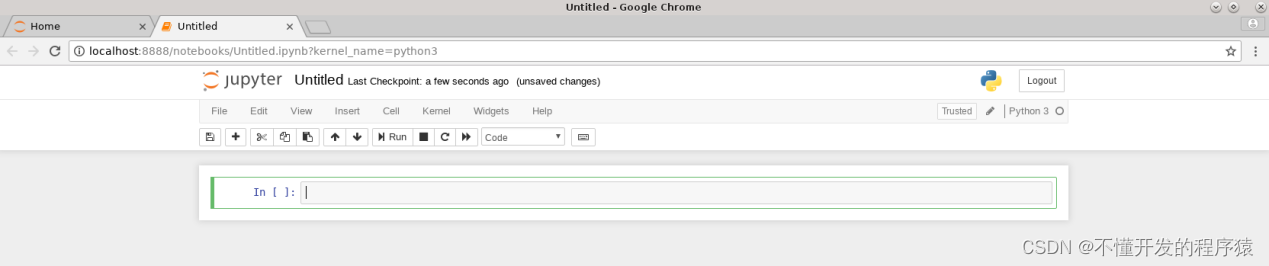
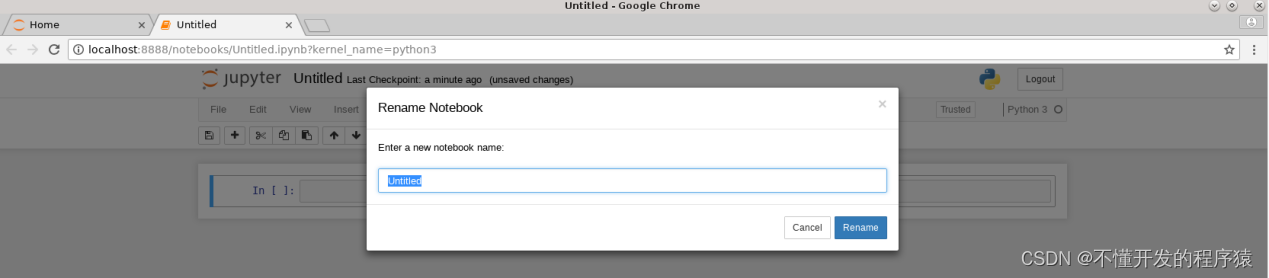
5.点击Untitled,在弹出框中修改标题名,点击Rename确认
2.数据准备
- 输入代码后,使用shift+enter执行,下同。
- 导入所需库
import math
import numpy as np #进行数学操作
import pandas as pd #读取数据

3.导入iris数据
iris = pd.read_csv('/root/experiment/datas/iris1.csv', header=None) #读取数据
iris.columns = ['sepal_length', 'sepal_width',
'petal_length', 'petal_width', 'target_class'] #列名

3.将最小卡方值添加进DataFrame
def merge_rows(df,feature):
tdf = df[:-1]
distinct_values = sorted(set(tdf['chi2']), reverse=False)
col_names = [feature,'Iris-setosa', 'Iris-versicolor',
'Iris-virginica','chi2']
updated_df = pd.DataFrame(columns = col_names) #加入卡方值,生成新的数组
updated_df_index=0
for index, row in df.iterrows(): #对所有数据进行处理
if(index==0):#判别
updated_df.loc[len(updated_df)] = df.loc[index]
updated_df_index+=1
else:
if(df.loc[index-1]['chi2']==distinct_values[0]):
updated_df.loc[updated_df_index-1]['Iris-setosa']+=df.loc[index]['Iris-setosa']
updated_df.loc[updated_df_index-1]['Iris-versicolor']+=df.loc[index]['Iris-versicolor']
updated_df.loc[updated_df_index-1]['Iris-virginica']+=df.loc[index]['Iris-virginica']
else:
updated_df.loc[len(updated_df)] = df.loc[index]
updated_df_index+=1
updated_df['chi2'] = 0.
return updated_df #返回值

4.计算卡方值
def calc_chi2(array):
shape = array.shape
n = float(array.sum())
row={}
column={}
#计算每行的和
for i in range(shape[0]):
row[i] = array[i].sum()
#计算每列的和
for j in range(shape[1]):
column[j] = array[:,j].sum()
chi2 = 0
#卡方计算公式
for i in range(shape[0]):
for j in range(shape[1]):
eij = row[i]*column[j] / n
oij = array[i,j]
if eij==0.:
chi2 += 0. #确保不存在NaN值
else:
chi2 += math.pow((oij - eij),2) / float(eij)
return chi2

5.计算每一个类别的卡方值
def update_chi2_column(contingency_table,feature):
for index, row in contingency_table.iterrows():
if(index!=contingency_table.shape[0]-1):
list1=[]
list2=[] #定义存储list
list1.append(contingency_table.loc[index]['Iris-setosa'])#添加值,下同
list1.append(contingency_table.loc[index]['Iris-versicolor'])
list1.append(contingency_table.loc[index]['Iris-virginica'])
list2.append(contingency_table.loc[index+1]['Iris-setosa'])
list2.append(contingency_table.loc[index+1]['Iris-versicolor'])
list2.append(contingency_table.loc[index+1]['Iris-virginica'])
prep_chi2 = np.array([np.array(list1),np.array(list2)])
c2 = calc_chi2(prep_chi2) #array格式数据
contingency_table.loc[index]['chi2'] = c2
return contingency_table #返回值

6.计算频次表
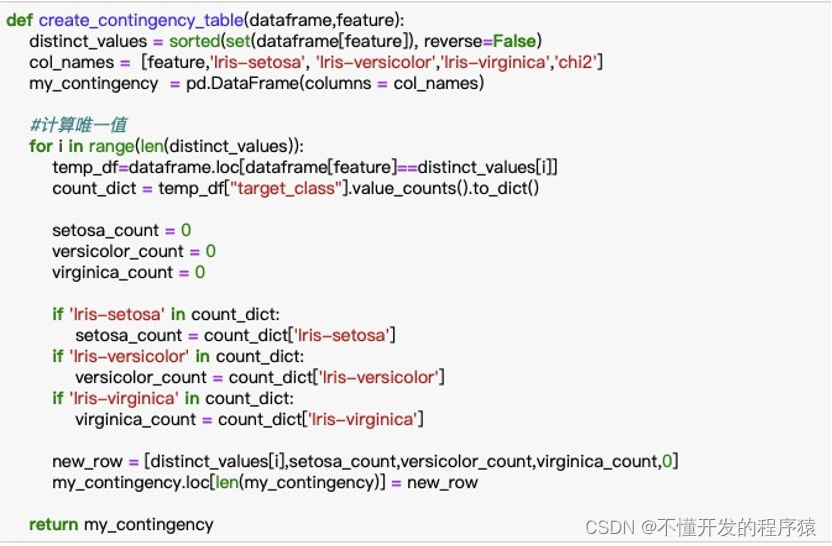
def create_contingency_table(dataframe,feature):
distinct_values = sorted(set(dataframe[feature]), reverse=False)#排序
col_names = [feature,'Iris-setosa', 'Iris-versicolor','Iris-virginica','chi2']
my_contingency = pd.DataFrame(columns = col_names) #DataFrame数据格式
#计算唯一值
for i in range(len(distinct_values)):
temp_df=dataframe.loc[dataframe[feature]==distinct_values[i]]
count_dict = temp_df["target_class"].value_counts().to_dict()
setosa_count = 0
versicolor_count = 0
virginica_count = 0
if 'Iris-setosa' in count_dict:
setosa_count = count_dict['Iris-setosa']
if 'Iris-versicolor' in count_dict:
versicolor_count = count_dict['Iris-versicolor']
if 'Iris-virginica' in count_dict:
virginica_count = count_dict['Iris-virginica']
new_row = [distinct_values[i],setosa_count,versicolor_count,virginica_count,0] #列表生成
my_contingency.loc[len(my_contingency)] = new_row
return my_contingency #返回值
7.ChiMerge函数定义
def chimerge(feature, data, max_interval):
df = data.sort_values(by=[feature],ascending=True).reset_index()
#传入频次表
contingency_table = create_contingency_table(df,feature)
#计算初始间隔值
num_intervals= contingency_table.shape[0]
#是否满足最大间隔
while num_intervals > max_interval:
#相邻列的卡方值
chi2_df = update_chi2_column(contingency_table,feature)
contingency_table = merge_rows(chi2_df,feature)
num_intervals= contingency_table.shape[0]
#打印输出结果
print('The split points for '+feature+' are:')
for index, row in contingency_table.iterrows():
print(contingency_table.loc[index][feature])
#打印输出结果
print('The final intervals for '+feature+' are:')
for index, row in contingency_table.iterrows():
if(index!=contingency_table.shape[0]-1):
for index2, row2 in df.iterrows():
if df.loc[index2][feature]<contingency_table.loc[index+1][feature]:
temp = df.loc[index2][feature]
else:
temp = df[feature].iloc[-1]
print("["+str(contingency_table.loc[index][feature])+","+str(temp)+"]")
print(" ")

8.对Iris数据
#对Iris进行函数操作
for feature in ['sepal_length', 'sepal_width', 'petal_length','petal_width']:
chimerge(feature=feature, data=iris, max_interval=6)



数据集资源
链接: https://pan.baidu.com/s/1Cnnhdw1IQeBWtATjCpz3tw?pwd=2024
提取码: 2024
–end–
说明
本实验(项目)/论文若有需要,请后台私信或【文末】个人微信公众号联系我
















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











