







1、什么是模板引擎?
将数据变成视图最优雅的解决方法。
v-for:实际上也是一直模板引擎
历史方法:
1)纯DOM法:通过createElement标签,在追加节点(上树)。
2)数组join法:var str=['A','B','C','D'].join('') 输出结果:ABCD (可以实现换行)
3)ES6的模板语法:反引号、变量
4)模板引擎:mustache:{{}}
2、模板引擎的基本语法
1)基本对象:{{}}
2)循环数组:开始循环:{{#数组名}}
简单数组{{.}} 数组对象{{数组对象的键名}}
结束循环:{{/数组名}}
3)使用Mustache.render(temp,data);第一参数:模板;第二个参数:数据 返回结果:dom结构的字符串
3、Mustache的底层核心机理
猜测:简单情况:使用正则表达式+replace(); 复杂情况:不仅仅是正则
实际机理:
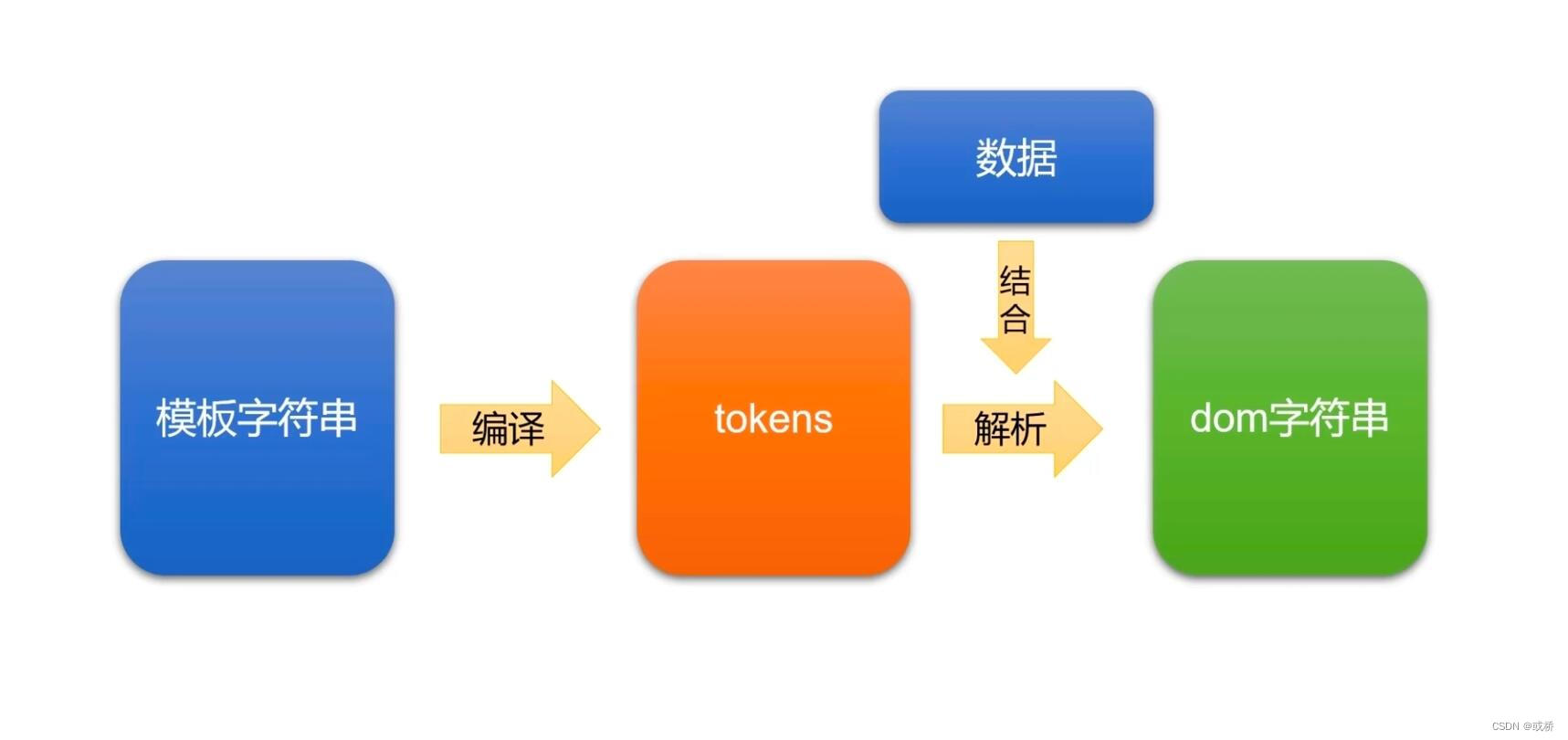
1)先将模板字符串编译成tokens:
tokens:是一个JS的嵌套数组,就是模板字符串用JS表示。是抽象语法树(AST)、虚拟节点等的开山鼻祖。

注意:当模板字符串中有循环存在,就会编译为嵌套更深的tokens
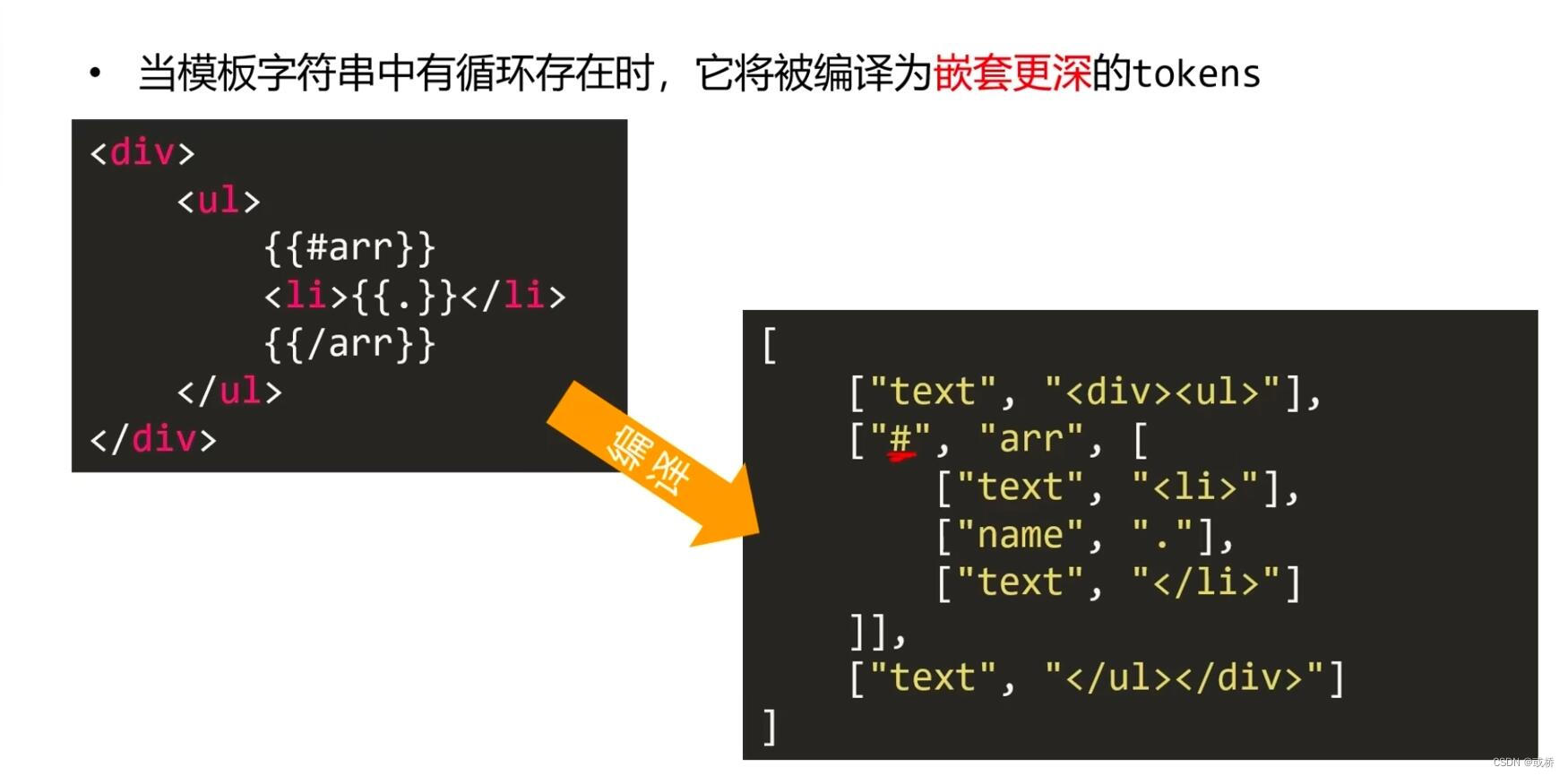
2)将tokens和数据进行结合,解析成dom字符串
4、实现模板引擎核心功能
1)定义一个扫描Scanner类,用于扫描传进来的模板字符串
(1)定义一个当扫描指针遇到“{{”等指定符号就跳过的scan()方法
(2)定义一个当扫描指针直到遇见指定内容结束,并返回扫描过的内容的scanUntil()方法
2)定义一个Totokens()函数:用于将模板字符串变为tokens数组,将扫描的内容push()进tokens数组里
1)简单情况(没有循环):
定义一个tokens,当扫描器扫描到{{}}里面的内容,就将其以["name":扫描的内容]的形式,作为一个token添加进tokens数组中;当扫描器扫描到{{}}之外的内容,将其以["text":扫描过的内容],作为一个token添加进tokens数组中
2)循环情况(带#和/):
当扫描器扫描到{{#数组名}}中的#时开始,到{{/数组名}}中的/结束,则说明将要循环遍历出里对应的token,作为一个子tokens,添加到toekens中。
附:定义一个nestTokens函数,用于处理循环情况,折叠tokens:将#号和/里的token整合。
3)定义一个renderTemp()函数:用于将tokens数组和data数据结合,变成dom字符串
(1)当每个token[0]是text类型时,就原样拼接该token[1]中的dom字符串
(2)当每个token[0]是name类型时,则需要和data相关数据进行替换,最后将替换后的dom字符串拼接
注意:
1、当模板中要替换的数据为单层结构时:可直接根据data中数据的键名,取得相应数据
2、当模板中要替换的数据为多层结构时:如dataObj={a:{b:{c:100}}},我们需要将'a.b.c'的结果输出为:100。
所以定义一个lookup()函数,用于解决上述两个问题,实现可以在data对象中,寻找用续点符号的keyName属性
(3)当每个token[0]是#类型时,则需要根据data中的数组,递归实现实现将tokens和data数据结合,最后将替换好的dom字符串拼接。
定义一个parseArray()函数,用于将处理数组,结合renderTemp实现递归
* 第一个参数:token['#',数组名,tokens],不是tokens
* 这个函数递归调用renderTemp()的次数由data数组的长度决定
4)提供全局对象Template中一个render()方法,需要传递两个参数:一个为模板字符串,一个为对应数据data
5、相关函数的具体实现要点
1)scan(tag):路过指定内容,如:跳过}
判断this.tail.indexOf(tag) == 0是否遇到指定内容,遇到将指针向后移动指定内容的长度,改变剩余模板字符串
2)scanUntil(stopTag):让指针进行扫描,直到遇见指定内容结束,并返回扫描过的文字 stopTag:停止标志
循环执行扫描,改变指针的位置,当遇到指定内容时,返回路过的字符,并记录当前指针位置,直到扫描完模板字符串停止
3)Totokens(tempStr):将模板字符串(tempStr)变为tokens数组
创建一个扫描类,将扫描过的返回的模板字符串,根据返回的模板进行分类;
定义一个toekns数组,将不同分类都pish()进去
(1)nestTokens(tokens):折叠tokens,将#号和/里的token整合
*定义一个栈结构(先进后出):存放小tokens,
*定义一个收集器collector:开始指向nestTokens这个结果数组 var collector = nestTokens
*收集器的指向会变化,当遇见#,收集器指向这个token的下标为2的新数组
当遇到#时:
// 收集器里放入token
collector.push(token);
// 入栈
sections.push(token);
//收集器换为下标为2的数组['#','name',[]]
collector = token[2] = [];
当遇到"/"时:
// 出栈 pop()会返回弹出的项
sections.pop();
// 改变栈结构栈顶,那一项下标为2的数组
collector = sections.length > 0 ? sections[sections.length - 1][2] : nestTokens;
当其他情况:
//将token放入收集器里
collector.push(token);
最后将折叠好的nestTokens返回。
4)renderTemp(tokens,data):用于将tokens数组和data数据结合,变成dom字符串
将Totokens(tokens)处理好返回的tokens和data传入renderTemp()函数中,根据tokens中每个token[0]中的类型进行数据匹配。
*当token[0]是text类型:
只需要将每个token[1]进行追加
*当token[0]是name类型:
(1)lookup(dataObj, keyName):实现可以在data对象中,寻找用续点符号的keyName属性(主要解决多层的数据结构)
先判断keyName是否含有点符号(如'a.b')keyName.indexOf(".") != -1 && keyName!==".",
如果有,则拆开为数组keyName.split('.');再循环一层一层找下去对应数据。
如果没有,则直接返回dataObj[keyName]
*当token[0]是#类型:
(1)parseArray(token, data):用于将处理数组,结合renderTemp实现递归
* 处理数组,结合renderTemp实现递归
* 第一个参数:token['#',数组名,tokens],不是tokens
* 这个函数递归调用renderTemp()的次数由data数组的长度决定
// 得到整体数据data中的这个数组要使用的部分
var v = lookup(data, token[1]);
// 当v是一个数组时
v.forEach(element => {
// 注意:当数据为:a.b的形式时,这里需要补一个“.”属性,
resultStr += renderTemp(token[2], {
...element,
'.': element
})
});返回resultStr
5)render(tempStr, data):
1)调用Totokens函数,将模板字符串变为tokens数组
2) 调用renderTemp函数,将tokens数组变成dom字符串,
3)返回dom字符串
备注:作为学习记录总结分享,有问题欢迎指正!!!
详情代码,gitee地址:
或桥/source-code-learning (gitee.com) https://gitee.com/li_jiaze/vue-source-code-learning/
https://gitee.com/li_jiaze/vue-source-code-learning/

















 1081
1081

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









