







1.nn.Conv1d
torch.nn.Conv1d() 是 PyTorch 中用于定义一维卷积层的类。一维卷积层常用于处理时间序列数据或具有一维结构的数据。

构造函数 torch.nn.Conv1d() 的语法如下:
torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
"""
参数说明:
in_channels:输入的通道数,即输入的特征图的深度。
out_channels:输出的通道数,即卷积核的数量,也是输出的特征图的深度。
kernel_size:卷积核的大小,可以是一个整数或一个元组/列表。
stride:卷积核的步幅大小,默认为 1。
padding:在输入的两侧添加填充的大小,默认为 0。
dilation:卷积核元素之间的间距,默认为 1。
groups:将输入和输出连接的组数,默认为 1。
bias:是否在卷积中使用偏置,默认为 True。
"""
一维卷积层的输入形状为 (batch_size, in_channels, input_length),其中 batch_size 是批次大小,input_length 是输入序列的长度。输出形状为 (batch_size, out_channels, output_length),其中 output_length 是输出序列的长度,由输入序列长度、卷积核大小、填充和步幅等参数决定。
import torch
import torch.nn as nn
# 创建一个一维卷积层
conv_layer = nn.Conv1d(in_channels=3, out_channels=10, kernel_size=3, stride=1, padding=1)
# 输入数据
input_data = torch.randn(32, 3, 100) # 输入数据形状为 (batch_size, in_channels, input_length)
# 前向传播
output = conv_layer(input_data)
print("输出形状:", output.shape) # 输出形状为 (32, 10, 100)


2.torch.nn.Conv2d()
torch.nn.Conv2d() 是 PyTorch 中用于定义二维卷积层的类。二维卷积层在处理图像数据或具有二维结构的数据时非常常用。
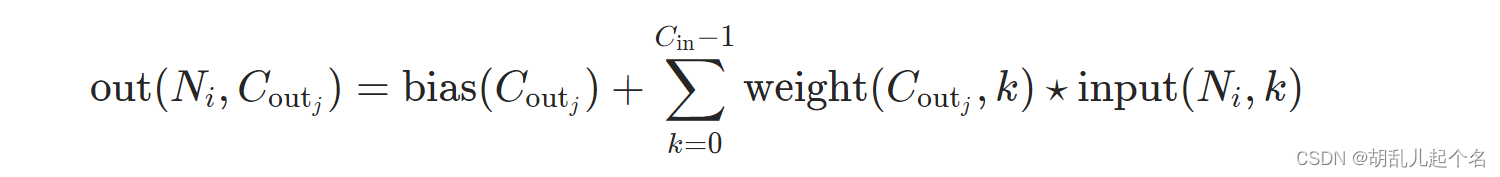
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
"""
参数说明:
in_channels:输入的通道数,即输入特征图的深度。
out_channels:输出的通道数,即卷积核的数量,也是输出特征图的深度。
kernel_size:卷积核的大小,可以是一个整数或一个元组/列表。
stride:卷积核的步幅大小,默认为 1。
padding:在输入的两侧添加填充的大小,默认为 0。
dilation:卷积核元素之间的间距,默认为 1。
groups:将输入和输出连接的组数,默认为 1。
bias:是否在卷积中使用偏置项,默认为 True。
"""
二维卷积层的输入形状为 (batch_size, in_channels, height, width),其中 batch_size 是批次大小,height 和 width 分别是输入图像的高度和宽度。输出形状为 (batch_size, out_channels, output_height, output_width),其中 output_height 和 output_width 是输出特征图的高度和宽度,取决于输入图像的大小、卷积核大小、填充和步幅等参数。
import torch
import torch.nn as nn
# 创建一个二维卷积层
conv_layer = nn.Conv2d(in_channels=3, out_channels=10, kernel_size=3, stride=1, padding=1)
# 输入数据
input_data = torch.randn(32, 3, 64, 64) # 输入数据形状为 (batch_size, in_channels, height, width)
# 前向传播
output = conv_layer(input_data)
print("输出形状:", output.shape) # 输出形状为 (32, 10, 64, 64)
输出形状: torch.Size([32, 10, 64, 64])


3.torch.nn.ConvTranspose1d()
一维转置卷积层可以用于将特征图的尺寸扩大,通常用于上采样操作。转置卷积的计算方式与普通卷积相反,可以将较小的特征图映射到较大的输出特征图。因此,转置卷积层通常用于生成更高分辨率的特征图。
torch.nn.ConvTranspose1d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
"""
参数说明:
in_channels:输入的通道数。
out_channels:输出的通道数。
kernel_size:卷积核的大小。
stride:步幅大小,默认为 1。
padding:输入的零填充大小,默认为 0。
output_padding:输出的零填充大小,默认为 0。
groups:输入和输出的通道之间的连接数,默认为 1。
bias:是否使用偏置参数,默认为 True。
dilation:卷积核的扩张大小,默认为 1。
"""
import torch.nn as nn
# 定义一维转置卷积层
conv_transpose = nn.ConvTranspose1d(in_channels=3, out_channels=5, kernel_size=3, stride=2, padding=1)
# 创建随机输入数据
input = torch.randn(1, 3, 10) # 输入大小为 (batch_size, in_channels, input_length)
# 应用转置卷积层
output = conv_transpose(input)
print("Output shape:", output.shape)
Output shape: torch.Size([1, 5, 19])
3.torch.nn.ConvTranspose2d()
torch.nn.ConvTranspose2d 是 PyTorch 中用于定义二维转置卷积层的类。二维转置卷积层也称为反卷积层或上采样层,用于将输入特征图的尺寸扩大。
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size, stride=1, padding=0, output_padding=0, groups=1, bias=True, dilation=1)
"""
参数说明:
in_channels:输入的通道数。对于输入的二维特征图,通道数就是特征图的深度。
out_channels:输出的通道数。表示转置卷积层中卷积核的数量,也是输出特征图的深度。
kernel_size:卷积核的大小。可以是一个整数,表示正方形卷积核的边长,或者是一个元组 (h, w),表示卷积核的高度和宽度。
stride:步幅大小。可以是一个整数,表示在输入特征图上水平和垂直滑动卷积核的步幅,或者是一个元组 (h, w),表示水平和垂直方向的步幅。
padding:输入的零填充大小。控制输入特征图四周添加零填充的数量,默认为 0。
output_padding:输出的零填充大小。控制输出特征图四周添加零填充的数量,默认为 0。
groups:输入和输出的通道之间的连接数。默认为 1,表示每个输入通道都与输出通道相连。
bias:是否使用偏置参数。控制是否在卷积计算中使用偏置,默认为 True。
dilation:卷积核的扩张大小。可以是一个整数,表示卷积核中的元素之间的间隔,或者是一个元组 (h, w),表示水平和垂直方向的扩张大小。
"""
import torch
import torch.nn as nn
# 定义二维转置卷积层
conv_transpose = nn.ConvTranspose2d(in_channels=3, out_channels=5, kernel_size=3, stride=2, padding=1)
# 创建随机输入数据
input = torch.randn(1, 3, 10, 10) # 输入大小为 (batch_size, in_channels, height, width)
# 应用转置卷积层
output = conv_transpose(input)
print("Output shape:", output.shape)
Output shape: torch.Size([1, 5, 19, 19])
公式
H_out=(H_in−1)×stride[0]−2×padding[0]+dilation[0]×(kernel_size[0]−1)+
output_padding[0]+1















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









