







PageRank是Google专有的算法,用于衡量特定网页相对于搜索引擎索引中的其他网页而言的重要程度
图片来自网络,这里就根据这个图片的情况来实现PageRank算法

这个图上有四个顶点,A,B,C,D,每个顶点对应一个网页。每个顶点都有若干条边,边的方向可能是指向别的顶点(当前网页的出链),也可能是别的顶点指向自己(当前网页的入链)
PageRank算法会统计每个网页的入链数量,数量越多则网页越重要,那么在搜索网页的时候,重要的网页应该排在前面,更容易被搜索网页的人看到。
但这样会有一个漏洞,那就是知道这个原理的人,可以设置一大堆没有用的网页,这些网页的用处就是有一个链接都指向同一个网页,被指向的这个网页的入链数量就会大幅增加。为了避免这种情况,因此从统计每个网页的入链数量,改为给每个链接设置一个权重,统计每个入链的权重,然后统计权重之和作为这个顶点的权重,也就是这个网页的重要程度
比如一开始顶点A有两个出链,分别指向了顶点B,D,四个顶点的初始权重都为1,顶点A有两条出链,则 1/2,每条出链的权重为0.5,像这样每个顶点的出链都计算一下。然后针对每一个顶点,统计入链的权重之和,比如顶点B,一共有三条入链,来自A的入链权重为0.5,来自C的入链权重为0.5,来自D的入链权重为0.5,因此顶点B的权重之和为1.5。这里将每个顶点的权重之和称为PR值。
就这样一直计算下去,会发现每个顶点的权重趋向于一个稳定的值,因为要不断的重复计算,所以Spark的代码中会出现while循环,循环的条件,就是设定一个差值指标(0.0001)。当所有网页的当前PR值,和上一次计算的PR值,两个PR值的差值的平均值,小于差值指标,则收敛,即说明每个顶点的权重已经与一个稳定的值非常接近。
将上面的转换成一个数据集
A-B,D
B-C
C-A,B
D-B,C
然后是具体实现的代码
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object demo20pageRank {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf()
conf.setAppName("demo20pageRank")
conf.setMaster("local")
val sc: SparkContext = new SparkContext(conf)
val point: RDD[String] = sc.textFile("Spark/data/pagePoint.txt")
//构成(A,(B,D))的格式,(B,D)是顶点A的出链List
val pointRDD: RDD[(String, List[String])] = point.map(line => {
val splits: Array[String] = line.split("-")
val p: String = splits(0)
val pList: List[String] = splits(1).split(",").toList
(p, pList)
})
//给上面的(A,(B,D))加上权重,初始为1,构成(A,(B,D),1)的形式
var point_weight: RDD[(String, List[String], Double)] = pointRDD.map {
case (p, pList) =>
(p, pList, 1)
}
//规定差值指标为0.0001
val diff_index:Double = 0.0001
//初始化变量d,含义是网页PR差值平均值
var d:Double = 1.0
while(d > diff_index){
point_weight.foreach(println)
//将权重平均的分给List里面的每个出链
//先计算平均后的权重,用当前顶点的权重除以当前顶点的出链数
//然后将上面的权重放在List的每条出链对应的顶点后面,构成Map集合,比如(B,0.5),(D,0.5)
//利用flatMap展开形成一个个的Map集合
val new_weight: RDD[(String, Double)] = point_weight.flatMap {
case (p:String, pList:List[String], weight:Double) =>
val w: Double = weight / pList.length.toDouble
val point_weightMap: Map[String, Double] = pList.map(p => (p, w)).toMap
point_weightMap
}
//对上面的一对Map集合按照key值合并,权重相加,形成(顶点,新的权重)的形式,比如(B,1.5)
//然后拿顶点与一开始的pointRDD关联,重新获取每个顶点的出链List
//结果类似(A,List(B, D),0.5),这样又重新构成了一开始的point_weight
val new_point_weight: RDD[(String, List[String], Double)] = new_weight.reduceByKey(_ + _)
.join(pointRDD)
.map {
case (p: String, (weight: Double, pList: List[String])) =>
(p, pList, weight)
}
//分别构建当前与之前的(顶点,权重)的k-v格式RDD,用来计算每个顶点当前权重和上一次权重的差值
//当所有顶点的差值的平均值小于差值指标(0.0001)的时候,收敛,即终止while循环
val current_weight: RDD[(String, Double)] = new_point_weight.map(line => (line._1, line._3))
val last_weight: RDD[(String, Double)] = point_weight.map(line => (line._1, line._3))
val cur_last_RDD: RDD[(String, (Double, Double))] = current_weight.join(last_weight)
d = cur_last_RDD.map {
case (point: String, (cur_w: Double, last_w: Double)) =>
val diff_weight: Double = cur_w - last_w
Math.abs(diff_weight)
}.sum / cur_last_RDD.count()
//因为point_weight和new_point_weight的结构一样,所以可以将new_point_weight的内容赋给point_weight
//在while循环里面,又会对赋值后的新的point_weight重新计算权重
point_weight = new_point_weight
}
}
}
while循环,每次都重新计算一次当前网页的每个出链的PR值
比如重新计算A的出链PR值为0.25,就是(A,(B,D),0.25)
让0.25和(B,D)重新构成(B,0.25)的形式,这是A的出链,还有C和D的出链,三条出链指向B,也就是B有三条入链,(B,0.25),(B,0.75),(B,0.25)这样汇合在一起就是(B,1.25),然后再加上对应的List
也就是(B,( C ),1.25),再对这个重新计算PR值,不断循环,直到不满足循环条件,循环结束
这里的核心代码可以分为几段
第一段,将图构建出来,将每个顶点和出链指向的顶点List集合关联起来,比如(A,(B,D))
//构成(A,(B,D))的格式,(B,D)是顶点A的出链List
val pointRDD: RDD[(String, List[String])] = point.map(line => {
val splits: Array[String] = line.split("-")
val p: String = splits(0)
val pList: List[String] = splits(1).split(",").toList
(p, pList)
})
第二段,给每个顶点设置一个初始的PR值
//给上面的(A,(B,D))加上权重,初始为1,构成(A,(B,D),1)的形式
var point_weight: RDD[(String, List[String], Double)] = pointRDD.map {
case (p, pList) =>
(p, pList, 1)
}
以上两段都是在while循环外面,第一段不会被改变,pointRDD,用来和后面的RDD进行join,让每个顶点能够获取自己对应的出链顶点List。第二段在while循环里面会被改变,point_weight会被后面重新计算后的PR值所替代
第三段
重新计算每个顶点的PR值,结果会有多个,(B,0.5),(B,0.5),(B,0.5)
val new_weight: RDD[(String, Double)] = point_weight.flatMap {
case (p:String, pList:List[String], weight:Double) =>
val w: Double = weight / pList.length.toDouble
val point_weightMap: Map[String, Double] = pList.map(p => (p, w)).toMap
point_weightMap
}
第四段
将(B,0.5),(B,0.5),(B,0.5)经过reduceByKey后变成(B,1.5),在跟pointRDD进行join操作
重新构建成(p, pList, weight)的形式,然后再对这个结果重新计算PR值,也就是weight权重值
val new_point_weight: RDD[(String, List[String], Double)] = new_weight.reduceByKey(_ + _)
.join(pointRDD)
.map {
case (p: String, (weight: Double, pList: List[String])) =>
(p, pList, weight)
}
第五段
这整个都是在计算全部网页的PR值差值的平均值,结果为 d
val current_weight: RDD[(String, Double)] = new_point_weight.map(line => (line._1, line._3))
val last_weight: RDD[(String, Double)] = point_weight.map(line => (line._1, line._3))
val cur_last_RDD: RDD[(String, (Double, Double))] = current_weight.join(last_weight)
d = cur_last_RDD.map {
case (point: String, (cur_w: Double, last_w: Double)) =>
val diff_weight: Double = cur_w - last_w
Math.abs(diff_weight)
}.sum / cur_last_RDD.count()
最后的结果为
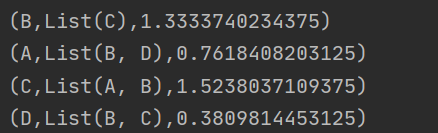
但这样依旧是不完善的,因为还有一种情况,那就是孤立网页。在图上,每个网页都是入链,也都有出链,但假如有一个网页,只有入链,没有出链。那么每次计算的时候,权重值通过入链进去这个网页后,却没有出链流向其他的网页。这样每次重新计算网页的PR值的时候,这个网页都会重新获得一次PR值,但之前获取的PR值却没有给别的网页,导致整体的PR值一直在减少
为了解决这种情况,需要对每个网页的PR值套用一个阻尼系数的公式
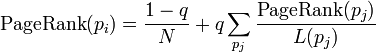
一般 q 的值取 0.85,每次计算完网页的PR值后,再按照上面的公式重新计算一遍网页的PR值
N是网页的数量,可以用 pointRDD.count() 获得
这样做先让每个网页的权重减低,再加上一个固定的值,避免了计算到最后,由于孤立网页“吞噬”PR值,导致每个网页的PR值过低的情况。这样做并不能避免孤立网页“吞噬”PR值,但是可以减轻这种情况,最终每个网页的PR值不至于过低,还能够正常使用
















 3946
3946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











