







一、字典
#字典
employee = {"10001":"zhang", "10214":"lee", "10099":"mail"} #定义字典,字典的键和键值成对出现
employee["10023"] = "ma" #利用键,添加元素
print("No.10001 is ",employee["10001"]) #字典用hash算法,将键值对应到某个整数下,查找的时候可以直接定位到需要查找的元素
#查找的时候是有键到值,不能直接查找值
if '10099' in employee:
print("found 10099")
#dict()函数,把列表的值是元组的列表转换为字典
test = [('name',' zhang'),('idcard','513001'),('sex','male')]
dict(test)
#关键字参数转换为字典
test1 = dict(name = 'zhang',id =513001,sex ='male')
print(test1)
运行结果:

字典的嵌套和遍历
#字典嵌套
info1 = dict(name = 'zhang',id =513001,sex ='male')
info2 = dict(name = 'lee',id =54121,sex ='male')
info3 = dict(name = 'ma',id =45121,sex ='female')
company = {10001:info1,1002:info2,1003:info3} #company是嵌套字典
print(company[1002]['name']) #用键进行查找,键是可hash类型
#字符串格式化输出
sText = "Mary has {} lambs,they are {x},{y} and \
{}.".format(3,"happy",x="cot", y= "nauty") # x,y 是关键词,str.format()函数
print(sText)
#字典的成员函数
info1Copy = info1.copy()
info1Get = info1.get("age", 0) #dict.get()相当于通过[键]进行查找,但是它不报错,找不到就给出默认值0
info1pop = info1.pop("sex") #弹出(删除)键值
print("------------------")
for x in info2 : #遍历键
print(x)
for x in info2.values() : #遍历值
print(x)
for x in info2.items() : #遍历项,一对一对地遍历
print(x)
运行结果:

二、函数
def fct(x):
"求函数的平方值"#函数文档编写,直接在函数后面写字符串即可
return x*2
temp1 = fct #函数本身也可以进行名字绑定
print(temp1(2))
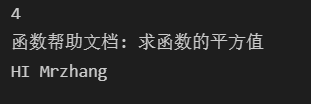
print("函数帮助文档:",fct.__doc__) #打印函数的文档介绍
#在VScode下方的终端可以输入python,进入终端,help()查看函数文档,exit()退出终端
#默认值参数,有默认值就按照默认值
def greeting (name,gender = "male"):
s = "Mr" if gender == "male" else "Miss"
name = s + name
print("HI",name)
greeting("zhang")
#函数传字典的时候,修改是会影响实参的,相当于c语言里面传的数组名(即地址)
运行结果:
函数的参数传递(任意个数函数参数传递)
#函数传字典的时候,修改是会影响实参的,相当于c语言里面传的数组名(即地址)
#传递列表的时候,也会修改实参的值
def ListParameter (ListPrm) :
ListPrm[1] = 2
List = [1,20,5]
ListParameter(List)
print(List)
#关键字参数,可以指定形参的名字,不用按照先后顺序传递参数,可读性更高
#eg. function(id = 1212, gender = "male")
#任意参数个数的函数
def myPrint(titile, *contents): #*号吸收所有剩余的参数,元组形式
print(titile,":")
print(type(contents))
print(contents)
myPrint("PC Lange", "C","c++","python")
def myPrint2(titile, **contents): #**吸收关键字参数,字典形式
print(titile,":")
print(type(contents), contents)
for k,v in contents.items(): #遍历字典
print(k,v,"\t")
myPrint2("PC Lange", one="C",two ="c++",three= "python")
运行结果:

参数分配
#参数分配
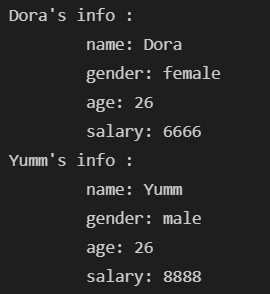
def myPrint3(title,name,gender,age,salary):
print(title,":")
print("\tname:",name)
print("\tgender:",gender)
print("\tage:",age)
print("\tsalary:",salary)
dora = ("Dora's info","Dora","female", 26,6666)
myPrint3(*dora) #*号将序列拆开,传递给函数
Yumm = dict(name = "Yumm",gender = "male",age = 26,salary =8888)
myPrint3("Yumm's info",**Yumm) #**号将字典中的元素传递给函数,键值给形参,形参名对应键名称
运行结果:
#返回多个值,逗号即可
#全局作用域,局部作用域
x = 1
s = "funtion"
scope = vars() #变量存储在看不见的字典中的
#返回变量的情况,scope()为迭代类型'scope': {...},
#可以得到当前的运行文件,'f:/Python_Study/20220123/1.py'
#print(scope)
"""
显示结果:
{'__name__': '__main__', '__doc__': None, '__package__': None,
'__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x00F2BF40>,
'__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>,
'__file__': 'f:/Python_Study/20220123/1.py', '__cached__': None, 'x': 1, 's': 'funtion', 'scope': {...}}
"""
def func() :
global x #在函数内部申明一个全局变量,修改它也会修改外部的变量值,尽量不用
#函数中用到没有出现的变量,默认会寻找函数外的全局变量
x = 13
print("one", end = "," ) #print()函数的结尾默认是换行符,可以指定结尾符号
print("two",end = "," )
print("three")
print("abcdef\r123") #\r回到行首,123替代了abc
多个.py文件存函数
#把函数存在模块中
#用多个.py文件,比如test.py存入一个函数testFun(),用import test导入文件
#或者用from test import testFun
# 如果test.py存入了一个文件夹里file-->file2-->test.py,则用form file.file2 import testFun
三、类
类的定义和继承
from enum import Enum #加入枚举类型
class Gender(Enum): #继承
male = 0
female =1
class person:
"This a help word"#帮助文档
def __init__(self,idNo = "NONE", name = "NONE") : #构造函数
print("person's constraction function is called!")
self.idNO =idNo
self.sName = name
self.gender = Gender.male
self.weight = 0
def speak(self):
print("I am:",self.sName,"Nice to meet you!")
def eat(self,food):
assert type(food) == type(1)
self.weight+=food
print("person's eat() is called")
dora = person("1221","dora")
dora.iHeight = 172 #给dora加入一个身高的变量
#继承
class Employee(person):
def __init__(self,emplNo, idNo, name):
super(Employee,self).__init__(idNo, name) #执行超类的初始化函数,用Employee的超类,多重继承也可以用其他超类的构造函数
print("Employee's constraction function is called!")
self.sEmployeeNo = emplNo
self.sJobTitle = ""
self.sDepartment = ""
def speak(self):
super().speak() #用super().调用超类的函数
print("I am an employee!")
mail = Employee("1111","Id112","mail")
mail.eat(20) #子类可以直接用父类的函数,多重继承就依次往超类(父类)里面去找函数
#函数
print(issubclass(Employee,person)) #超类判断
print(Employee.__base__) #查找超类,返回元组,可以是多个元素
print(mail.__class__) #打印实例的类型
运行结果

多重继承
#多重继承
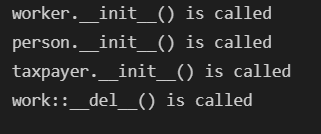
class person :
def __init__(self) -> None:
print("person.__init__() is called")
def __del__(self):
print("person::__del__() is called ")
class taxpayer :
def __init__(self) -> None:
print("taxpayer.__init__() is called")
def __del__(self):
print("taxpayer::__del__() is called ")
class worker(person, taxpayer) :
def __init__(self) -> None: #要分别写构造函数,并且将self传给构造函数
print("worker.__init__() is called")
person.__init__(self)
taxpayer.__init__(self)
def __del__(self): #析构函数的执行时间是有解释器决定的,所以一般不用析构函数进行逻辑设计
print("work::__del__() is called ")
mail = worker()
mail = 1
运行结果:
property()
#用property(fget,fset)来维护数据的一致性,如对长方形的长进行了修改,应该对面积也进行修改
class rect :
def __init__(self,Width, Height):
self.iWidth = Width
self.iHeight = Height
self.area = self.iWidth * self.iHeight
def setSize(self,size) :#size预期是元组(a,b)
self.iWidth, self.iHeight = size #元组的解包
self.area = self.iWidth * self.iHeight
def getSize(self):
return self.iHeight,self.iWidth,self.area
size =property(getSize,setSize)
r0 = rect(20,10)
r0.iWidth = 15
print(r0.getSize()) #此时得到的尺寸不一致
r0.size = (15,10) #property是属性,可以根据实际情况判断用fget还是fset
print(r0.size) #此时得到的尺寸一致
四、格式化字符串
#字符串格式化输出
avgScore = 78.12345 #(shift+Alt+up or down)是复制
ClassNo = 4
sText = "The average score of class{No} is {score:.2f}".format(No = ClassNo, score = avgScore)
sText2 = f"The average score of class{ClassNo} is {avgScore:.2f}"
print(sText, sText2)
Pi = 3.14159265358979
sText = f"pi={Pi:e}" #科学计数法
print(sText)
sText = f"pi={Pi:.2f}" #二位小数
print(sText)
sText = f"pi={Pi:10.2f}" #二位小数,且输出占十个位子
print(sText)
P = 9222314558
sText = f"p={P:d}" #十进制
print(sText)
sText = f"p={P:b}" #二进制
print(sText)
sText = f"p={P:o}" #八进制
print(sText)
print(f"p={P:,}") #用,作为分节符
#str.center()函数,居中作用
print("mail".center(30)) #
print("mail".center(30,"*"))
#str.find()查找函数.返回第一个包含字符串的下标,没找到就是-1
#str.count()计数某个字符的个数
s = "Hamlet said,to be or not to be ?"
print(s.find("to",0,len(s)))
print(s.count("to"))
#str.join(list) 用str连接list里面的内容
dir = ["home", "pi","doc", "Python"]
print("/".join(dir))
print("C:"+"\\".join(dir))
#str.replace()函数,不改变原来的字符串
newStr = s.replace("Hamlet","Mail Lee")
print(newStr)
print(s)
#str.split()拆分成列表
print("1+2+3+4+5".split("+"))















 583
583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









