






这里对bert不做介绍,主要介绍代码运行环境和数据集变换。
这是之前我看的一篇道友写的,而很多地方都完善了:点击,进入通道
资源地址:
bert模型文件:https://github.com/google-research/bert
预训练模型:https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip
首先我的环境:
win10 64位系统 python3.7 TensorFlow=1.14.0(GPU版本)CUDA=10.0
其他可能版本影响不大的模板:pandas=1.0.5
电脑配置不够,可以适当减少参数大小,下面会具体说明。
开始let’go
.
1、数据预处理(pre_data.py)
文件数据结构:
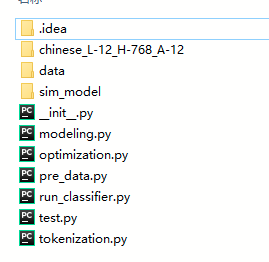
其他感觉运行用不到剔除了
# code 文件夹
# code/data 存放源数据与预处理数据
# code/data/nCoV_100k_train.labled.data 源数据
# code/chinese_L-12_H-768_A-12 存放预训练模型
# code/sim_model 存放各种结果
# code/init.py 空着就行
# code/pre_data.py 数据预处理文件,在code/data下会生成train.csv,dev.csv,test.csv
# code/modeling.py 模型文件
# code/optimization.py 训练优化器
# code/tokenization.py 训练端
# code/run_classifier.py main文件(连接其他文件类的枝干部分)
# code/test.py 测试结果的转换
第一步:准备数据,数据预处理,做好和训练模型数据接口工作
这一步非常重要,有处理错误会导致过程报错,然后反复调bug(用这个的个人经历,惨痛的教训)
我们写一个文件,要把数据处理成n*2的矩阵(n是样本数),两列:一列是中文数据内容,一列是label标签。
# code/pre_data.py
import pandas as pd
from sklearn.utils import shuffle
import re
def PREDATA():
file = pd.read_csv('../data/nCoV_100k_train.labled.data', encoding='utf-8')
file = file[file['情感倾向'].isin(['1', '-1', '0'])]
data = pd.DataFrame(zip(file['情感倾向'].astype(int), file['微博中文内容']))
# 数据量大,可以提取部分数据
# data = data.iloc[0:2500]
for i in range(data.shape[0]):
try:
if data['情感倾向'][i] == -1:
data['情感倾向'][i] = 2
if len(data['微博中文内容'][i]) < 10:
data['微博中文内容'][i] = '0'
else:
data['微博中文内容'][i] = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()??]", "", data['微博中文内容'][i])
except:
pass
data = data[~data['微博中文内容'].isin(['0'])]
data = shuffle(data)
num = data.shape[0]
data1 = data.iloc[:int(num * 0.8)]
data2 = data.iloc[int(num * 0.8) + 1:int(num * 0.9)]
data3 = data.iloc[int(num * 0.9) + 1:]
data1.to_csv('../data/train.csv', index=None, header=None, encoding='utf-8')
data2.to_csv('../data/test.csv', index=None, header=None, encoding='utf-8')
data3.to_csv('../data/dev.csv', index=None, header=None, encoding='utf-8')
PREDATA()
源数据演示

该过程首先数据清洗,去掉了label中不是[-1,0,1]的数据,并且去除了内容长度少于10的语料,而且对满足条件的进行了正则化处理。
最后处理完在data目录下生成train.csv,dev.csv,test.csv三个数据文件(数据量8:1:1)
三个文件为训练集,验证集,测试集,演示如下(三个csv文件格式相同,仅数据量不同):

PS1:正则化部分个人处理的,处理不好,大家可以自己发挥,数据处理好了,模型也会更准确。
PS2:为什么1,-1,0中-1变成了2,emm我忘记当时为什么这么做了,保持-1不变也没事,不影响。
PS3:切记train.csv等文件 没有index,没有header
2、训练验证测试(run_classifier.py)
modeling.py是模型文件,optimization.py是训练优化器,tokenization.py是训练端
这三个文件不用修改,主要是run_classifier.py
你需要根据情况,调整参数
参数说明如下:
# 使用GPU情况
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# 利用flags设置参数(名称,默认值,描述)
flags = tf.flags
FLAGS = flags.FLAGS
# 数据集存放目录 : "data_dir"
flags.DEFINE_string(
"data_dir", os.path.join(os.getcwd(), 'data'),
"The input data dir. Should contain the .tsv files (or other data files) "
"for the task.")
# 模型配置文件存放目录 : "bert_config_file"
flags.DEFINE_string(
"bert_config_file", os.path.join(os.path.join(os.getcwd(), 'chinese_L-12_H-768_A-12'), 'bert_config.json'),
"The config json file corresponding to the pre-trained BERT model. "
"This specifies the model architecture.")
# 训练任务名字 : "task_name"
flags.DEFINE_string("task_name", 'sim', "The name of the task to train.")
# 模型字典存放目录 : "vocab_file"
flags.DEFINE_string("vocab_file", os.path.join(os.path.join(os.getcwd(), 'chinese_L-12_H-768_A-12'), 'vocab.txt'),
"The vocabulary file that the BERT model was trained on.")
# 结果存放目录 : "output_dir"
flags.DEFINE_string(
"output_dir", os.path.join(os.getcwd(), 'sim_model'),
"The output directory where the model checkpoints will be written.")
# 其他参数
flags.DEFINE_string(
"init_checkpoint", None,
"Initial checkpoint (usually from a pre-trained BERT model).")
#
flags.DEFINE_bool(
"do_lower_case", True,
"Whether to lower case the input text. Should be True for uncased "
"models and False for cased models.")
# 最大总输入序列长度 : 模型输入的最长字符长度(1个汉字算一个)
flags.DEFINE_integer(
"max_seq_length", 64,
"The maximum total input sequence length after WordPiece tokenization. "
"Sequences longer than this will be truncated, and sequences shorter "
"than this will be padded.")
# 是否训练
flags.DEFINE_bool("do_train", False, "Whether to run training.")
# 是否验证(通常训练与验证一起进行)
flags.DEFINE_bool("do_eval", False, "Whether to run eval on the dev set.")
# 是否测试
flags.DEFINE_bool("do_predict", True, "Whether to run the model in inference mode on the test set.")
# 查看GPU内存,如果是为16GB,这里最大填写16(以下分别是三个过程的batch-size)
flags.DEFINE_integer("train_batch_size", 16, "Total batch size for training.")
flags.DEFINE_integer("eval_batch_size", 8, "Total batch size for eval.")
flags.DEFINE_integer("predict_batch_size", 8, "Total batch size for predict.")
# 学习率(可以自己调整,我的数据跑[1e-6,2e-5]之间1e-5的accuracy在局部峰值)
flags.DEFINE_float("learning_rate", 1e-5, "The initial learning rate for Adam.")
# epoch训练次数
flags.DEFINE_float("num_train_epochs", 100.0,
"Total number of training epochs to perform.")
# 慢热学习比例 : 例 设置0.1 则0.1 * epoch = 10 每10个epoch调整一次lr(类似动态学习率法)
flags.DEFINE_float(
"warmup_proportion", 0.1,
"Proportion of training to perform linear learning rate warmup for. "
"E.g., 0.1 = 10% of training.")
# 每多少步保存一下ckpt,防止中断前功尽弃
flags.DEFINE_integer("save_checkpoints_steps", 1000,
"How often to save the model checkpoint.")
# # 每个评估单元调用中要执行多少步骤
flags.DEFINE_integer("iterations_per_loop", 1000,
"How many steps to make in each estimator call.")
# TPG使用情况
flags.DEFINE_bool("use_tpu", False, "Whether to use TPU or GPU/CPU.")
tf.flags.DEFINE_string("master", None, "[Optional] TensorFlow master URL.")
flags.DEFINE_integer(
"num_tpu_cores", 8,
"Only used if `use_tpu` is True. Total number of TPU cores to use.")
另外数据接口做了修改,修改版的run_classifier.py
链接:https://pan.baidu.com/s/1MYYGyF48eTcp1XzM4K5srA
提取码:mh32
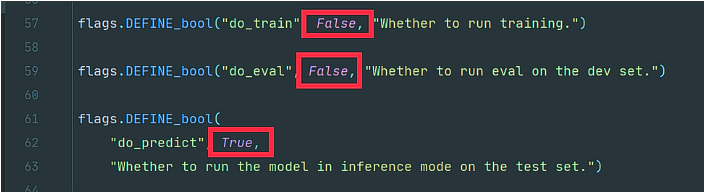
均调整为True,即可完成训练,验证,测试过程(测试可单独进行)
训练结果的指标存放在code/sim_model/eval_results.txt中,
测试结果存放在code/sim_model/test_results.tsv中,存放每一个类别概率:

PS1:如果运行报错内存不够train_batch_size,max_seq_length参数大小可以减小。
PS2:文件目录如果用os 那就不要出现data/tarin.py这种带‘/’的(会出问题)
*3、测试结果转换(test.py)
该步骤可省略,如果你对结果不满意,可转换成这样的类别文件:
 这样就简单明了了
这样就简单明了了
# code/test.py
import os
import pandas as pd
if __name__ == '__main__':
path = "sim_model/"
pd_all = pd.read_csv(os.path.join(path, "test_results.tsv"), sep='\t', header=None)
data = pd.DataFrame(columns=['polarity'])
print(data)
print(pd_all.shape)
for index in pd_all.index:
neutral_score = pd_all.loc[index].values[0]
positive_score = pd_all.loc[index].values[1]
negative_score = pd_all.loc[index].values[2]
if max(neutral_score, positive_score, negative_score) == neutral_score:
data.loc[index + 1] = ["0,neutral"]
elif max(neutral_score, positive_score, negative_score) == positive_score:
data.loc[index + 1] = ["1,positive"]
else:
data.loc[index + 1] = ["2,negative"]
data.to_csv(os.path.join(path, "pre_sample.tsv"), sep='\t')
print(data)
这个文件最后保存在code/sim_model/pre_sample.tsv
完整文件发在交流群
















 9987
9987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









