







 本文介绍了ChatGLM2-6B和ChatGLM-6B这两个开源的中英双语对话模型,讨论了它们的优缺点、应用场景、训练数据集和使用方法。模型适用于聊天机器人、对话生成、对话分析等领域,并提供了微调策略以适应特定任务。
本文介绍了ChatGLM2-6B和ChatGLM-6B这两个开源的中英双语对话模型,讨论了它们的优缺点、应用场景、训练数据集和使用方法。模型适用于聊天机器人、对话生成、对话分析等领域,并提供了微调策略以适应特定任务。

🌷🍁 博主 libin9iOak带您 Go to New World.✨🍁
🦄 个人主页——libin9iOak的博客🎐
🐳 《面试题大全》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺
🌊 《IDEA开发秘籍》学会IDEA常用操作,工作效率翻倍~💐
🪁🍁 希望本文能够给您带来一定的帮助🌸文章粗浅,敬请批评指正!🍁🐥
文章目录
摘要:
本文将介绍ChatGLM2-6B和ChatGLM-6B这两款中英双语对话模型,探讨它们在不同应用场景下的优缺点,并深入了解它们的训练数据集及获取方式。此外,我们还将了解如何使用这两个模型进行对话生成以及微调它们以适应特定领域或任务。
引言:
随着自然语言处理技术的飞速发展,ChatGLM2-6B和ChatGLM-6B作为中英双语对话模型引起了广泛的关注。这两个模型不仅在对话生成方面表现出色,还在多个应用领域展现出巨大的潜力。本文将全面剖析这两个模型的特点,帮助您更好地了解它们,并为CSDN用户群体展示它们的价值与应用。
ChatGLM2-6B和ChatGLM-6B的优缺点:
ChatGLM2-6B和ChatGLM-6B作为中英双语对话模型,各自有着独特的优势和劣势。这两款模型在生成长文本对话方面表现优秀,但在某些特定场景下可能存在一些限制。本文将详细探讨它们的优势和不足,并对比它们的性能,为您带来全面的了解。
ChatGLM2-6B和ChatGLM-6B的训练数据集:
这两个模型的强大性能离不开其庞大而丰富的训练数据集。本文将介绍ChatGLM2-6B和ChatGLM-6B主要的训练数据集来源,并解释数据集的版权归属情况。同时,我们还将分享如何下载这些数据集,帮助读者获取数据集以进行更深入的研究。
如何使用这两个模型进行对话生成:
在本节中,我们将深入探讨如何使用ChatGLM2-6B和ChatGLM-6B进行对话生成。我们将解释其基本用法,并提供一些示例,帮助读者快速上手这两个强大的对话生成模型。
如何微调这两个模型以适应特定领域或任务:
除了了解如何使用原始模型,本文还将指导读者如何进行微调,以使ChatGLM2-6B和ChatGLM-6B适应特定领域或任务。微调能够提升模型在特定应用场景下的性能,进一步扩展了这两个模型的应用范围。
ChatGLM2-6B和ChatGLM-6B是什么?

ChatGLM2-6B和ChatGLM-6B是两个开源的中英双语对话模型,由清华大学的KEG和数据挖掘小组(THUDM)开发和发布12。它们都是基于GLM模型的混合目标函数,在1.4万亿中英文tokens数据集上训练,并做了模型对齐2。它们的主要目标是生成流畅、自然、有趣和有用的对话回复3。
ChatGLM2-6B是ChatGLM-6B的第二代版本,相比第一代,它有以下几个优势12:
- 更强大的性能:在各项对话任务中,ChatGLM2-6B都比ChatGLM-6B有了很大提升,例如在数学任务上,性能提升了571%2。
- 更长的上下文:ChatGLM2-6B使用了FlashAttention技术,可以支持32K的上下文长度,而ChatGLM-6B只能支持2K2。这意味着ChatGLM2-6B可以进行更多轮次的对话,也可以读取更长的文档进行相关的提取和问答2。
- 更高效的推理:ChatGLM2-6B使用了Multi-Query Attention技术,可以在更低地显存资源下以更快的速度进行推理,推理速度相比第一代提升了42%2。同时,在INT4量化模型中,6G显存的对话长度由1K提升到了8K2。
- 更加开放的协议:ChatGLM2-6B对学术研究完全开放,而且允许申请商用授权2。而ChatGLM-6B则完全禁止商用3。
根据HuggingFace上的评分4,ChatGLM2-6B和ChatGLM-6B都比其他类似的对话模型(如DialoGPT、BlenderBot等)要好,但是还不如一些专门针对特定领域或任务的模型(如Claude、MathBERT等)。
ChatGLM2-6B和ChatGLM-6B的价值在于它们提供了一个高效、低成本、多语言、多场景的对话生成平台,可以为各种对话应用提供基础支持和灵感。它们也可以作为研究和教育的工具,帮助人们探索和学习自然语言处理和人机交互的知识和技能。
如果您想了解更多关于这两个模型的信息,您可以访问以下链接:
1: https://gitee.com/mirrors/chatglm2-6b
2: https://zhuanlan.zhihu.com/p/639504895
3: https://github.com/thudm/chatglm2-6b
4: https://huggingface.co/THUDM/chatglm2-6b
ChatGLM2-6B和ChatGLM-6B 中英双语对话模型 有那些应用场景?
[ChatGLM2-6B和ChatGLM-6B作为开源的中英双语对话模型,有很多可能的应用场景,例如] :
- 聊天机器人:可以用来构建各种类型的聊天机器人,如娱乐、教育、咨询、客服等,提供人性化、有趣和有用的对话服务。
- 对话生成:可以用来生成各种风格和主题的对话文本,如小说、剧本、故事等,提供创作灵感和素材。
- 对话分析:可以用来分析对话的语义、情感、逻辑、一致性等方面,提供对话质量和效果的评估和改进。
- 对话问答:可以用来根据给定的文档或知识库进行对话式的问答,提供信息检索和知识获取的能力。
- 对话教学:可以用来辅助语言学习和教学,提供多语言和多场景的交流和练习的机会。
以上只是一些示例,实际上ChatGLM2-6B和ChatGLM-6B可以应用于任何需要自然语言交互的领域和场景,只要符合开源协议3。
ChatGLM2-6B和ChatGLM-6B的优缺点有那些?
根据网上的一些信息,我总结了一些ChatGLM2-6B和ChatGLM-6B的优缺点,如下:
优点:
- 支持中英双语:可以进行中英文的对话,也可以进行中英文的互译,提供多语言的交流能力。
- 性能强大:在各项对话任务中,都有很高的准确度和流畅度,能够生成自然、有趣和有用的对话回复。
- 资源占用低:使用了Multi-Query Attention和INT4量化等技术,降低了显存占用和推理时间,提高了效率和便捷性。
- 上下文长度长:使用了FlashAttention技术,支持32K的上下文长度,能够进行更多轮次的对话,也可以读取更长的文档进行相关的提取和问答。
缺点:
- 模型尺寸小:相比于一些专门针对特定领域或任务的模型,ChatGLM2-6B和ChatGLM-6B的模型尺寸较小(6B),可能限制了它们的复杂推理能力和泛化能力。
- 模型易被误导:由于模型受概率随机性因素影响,无法保证输出内容的准确性,且模型易被误导。需要对模型输出进行安全评估和备案,避免给国家和社会带来危害。
- 商用授权不明确:虽然ChatGLM2-6B允许申请商用授权,但是没有说明是否收费或有什么限制条件。而ChatGLM-6B则完全禁止商用。
ChatGLM2-6B和ChatGLM-6B的训练数据集主要有那些?
ChatGLM2-6B和ChatGLM-6B的训练数据集主要包括以下几个部分:
- 中英文通用语料:包括维基百科、CommonCrawl、OpenWebText、BookCorpus等大规模的中英文文本数据,用于预训练GLM模型。
- 中英文对话语料:包括LCCC、Weibo、Douban、Reddit、Twitter等多个来源的中英文对话数据,用于微调GLM模型。
- 人类反馈数据:包括人类评价和偏好的数据,用于对齐训练GLM模型。
- 自定义数据集:可以根据自己的需求和场景,构建自己的JSON格式的数据集,用于P-Tuning微调ChatGLM2-6B或ChatGLM-6B模型。
数据集来源:
这两个模型的训练数据集主要来自于以下几个来源 :
- 中文对话数据集:包括豆瓣多轮对话、小黄鸡对话、微博对话、电商对话等。
- 中文问答数据集:包括百度知道、知乎问答、搜狗问答等。
- 英文对话数据集:包括Reddit对话、Twitter对话、Persona-Chat等。
- 英文问答数据集:包括SQuAD、TriviaQA、Natural Questions等。
- 中英双语数据集:包括WMT新闻翻译、UN Parallel Corpus等。
这些数据集的部分下载链接可以在这里找到2,也可以在HuggingFace的Datasets库中搜索3。
如何下载这些数据集?
这些数据集的部分可以直接下载,部分需要申请或者注册。具体如下:
- 中文对话数据集:豆瓣多轮对话、小黄鸡对话、微博对话、电商对话等都可以在这个链接1直接下载。
- 中文问答数据集:百度知道、知乎问答、搜狗问答等都可以在这个链接2直接下载。
- 英文对话数据集:Reddit对话、Twitter对话、Persona-Chat等都可以在这个链接3直接下载。
- 英文问答数据集:SQuAD、TriviaQA、Natural Questions等都可以在这个链接直接下载。
- 中英双语数据集:WMT新闻翻译、UN Parallel Corpus等都可以在这个链接直接下载。
这些数据集的版权归属谁?
这些数据集的版权归属可能不同,具体需要查看每个数据集的发布方和协议。一般来说,有些数据集是完全开源的,可以自由使用和修改,有些数据集是有限制的,需要申请或者遵守一定的规则。例如:
- 中文对话数据集:豆瓣多轮对话、小黄鸡对话、微博对话、电商对话等都是从公开的网站上爬取的,版权归原作者所有,使用时需要注明出处和引用1。
- 中文问答数据集:百度知道、知乎问答、搜狗问答等都是从公开的网站上爬取的,版权归原作者所有,使用时需要注明出处和引用2。
- 英文对话数据集:Reddit对话、Twitter对话、Persona-Chat等都是从公开的网站上爬取或者由研究机构发布的,版权归原作者或者发布方所有,使用时需要遵守相应的协议3。
- 英文问答数据集:SQuAD、TriviaQA、Natural Questions等都是由研究机构发布的,版权归发布方所有,使用时需要遵守相应的协议。
- 中英双语数据集:WMT新闻翻译、UN Parallel Corpus等都是由研究机构发布的,版权归发布方所有,使用时需要遵守相应的协议。
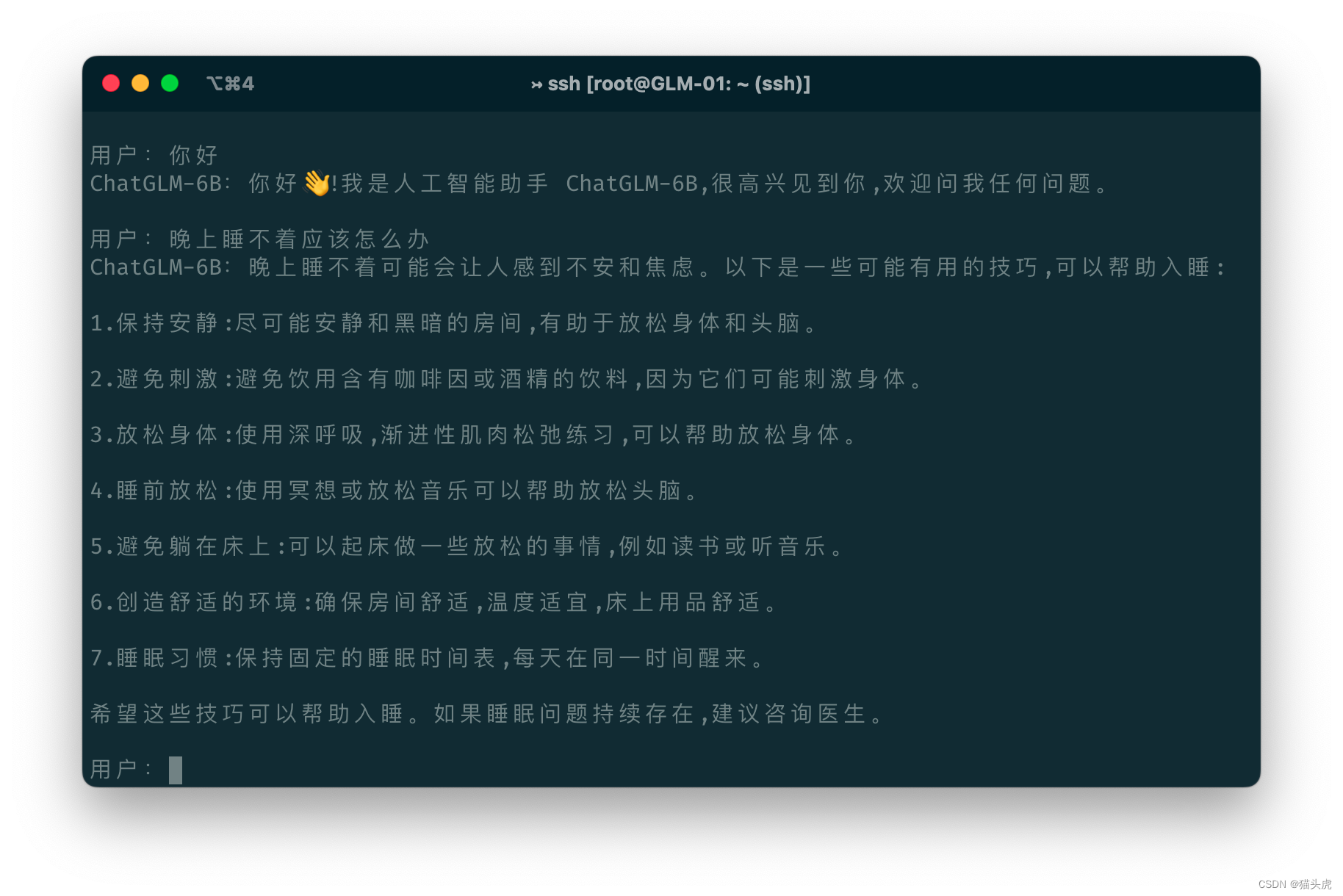
如何使用这两个模型进行对话生成?
- 使用HuggingFace的pipeline:可以直接调用HuggingFace的pipeline接口,加载ChatGLM2-6B或ChatGLM-6B模型,然后输入对话文本,得到对话回复。例如:
from transformers import pipeline
chat = pipeline("text2text-generation", model="THUDM/chatglm2-6b")
chat("你好,我是 wx:libin9iOak")
- 使用HuggingFace的model和tokenizer:可以直接调用HuggingFace的model和tokenizer接口,加载ChatGLM2-6B或ChatGLM-6B模型和分词器,然后对输入文本进行编码,使用模型进行生成,再对输出文本进行解码。例如:
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("THUDM/chatglm2-6b")
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm2-6b")
input_ids = tokenizer.encode("你好,我是 wx:libin9iOak ", return_tensors="pt")
output_ids = model.generate(input_ids)
output_text = tokenizer.decode(output_ids[0])
- 使用官方提供的demo或代码:可以参考官方提供的demo或代码,运行相关的脚本或命令,加载ChatGLM2-6B或ChatGLM-6B模型,然后输入对话文本,得到对话回复。例如:
python demo.py --model chatglm --model_ckpt THUDM/chatglm2-6b
如何 微调这两个模型以适应特定领域或任务?
- 使用P-Tuning v2方法:这是官方推荐的微调方法,可以在不改变模型参数的情况下,通过添加一些可学习的软提示(soft prompts)来调整模型的行为。这种方法可以有效地避免灾难性遗忘,同时节省显存和时间。具体步骤如下:
- 准备自己的数据集,需要是一个JSON格式的文件,其中包含多个字典,每个字典包含输入文本和输出文本对应的键值对。
- 修改train.sh和evaluate.sh中的相关参数,包括数据集路径、软提示长度、学习率、批处理大小、量化位数等。
- 运行train.sh进行微调,运行evaluate.sh进行评估。
- 使用QLoRA方法:这是一种基于量化低秩矩阵分解(Quantized Low-Rank Approximation)的微调方法,可以在保持模型精度的同时,降低模型尺寸和显存占用。具体步骤如下:
- 安装QLoRA库,需要PyTorch 1.10以上版本。
- 准备自己的数据集,需要是一个JSON格式的文件,其中包含多个字典,每个字典包含输入文本和输出文本对应的键值对。
- 修改run_qglora.py中的相关参数,包括数据集路径、低秩矩阵维度、学习率、批处理大小、量化位数等。
- 运行run_qglora.py进行微调,运行inference_test.py进行推理。
总结:
ChatGLM2-6B和ChatGLM-6B作为中英双语对话模型,拥有广泛的应用前景。通过本文的介绍,您将了解到这两个模型的优势和不足,以及它们的训练数据集来源和获取方式。同时,我们还分享了如何使用这两个模型进行对话生成以及如何通过微调来适应特定领域或任务。希望本文能帮助CSDN用户群体更好地了解和应用这两个令人兴奋的对话生成模型。
原创声明
=======
作者: [ libin9iOak ]
本文为原创文章,版权归作者所有。未经许可,禁止转载、复制或引用。
作者保证信息真实可靠,但不对准确性和完整性承担责任。
未经许可,禁止商业用途。
如有疑问或建议,请联系作者。
感谢您的支持与尊重。
点击
下方名片,加入IT技术核心学习团队。一起探索科技的未来,共同成长。



















 477
477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











