







目的
使用深度学习框架Pytorch,实现手写数字的识别。
深度学习入门的经典例子。数据集采用MNIST自带的手写数据集。数据集里面的数据长啥样?emmmm
差不多这个样吧

模型构建
,,这种东西对于我们这样的初学者来说,当然不大可能是自己定义啦,,,只要看的懂别人的,会调参即可。
同时,,我自己的电脑GPU有点辣鸡,所以emmm,,,当然是借助于云平台啦。。
去淘宝租也好,,找各大平台白嫖也可。。。反正,,学生党嘛,,哈哈。扯远了。
模型用的腾讯云的智能钛机器学习的例子的模型。我就大概解读下。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5) # 对图片进行第一次卷积。由于图片是灰色的,所以第一个参数是1,从中提取10个特征集
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)# 第二次卷积,从10个特征中提取20个特征
self.conv2_drop = nn.Dropout2d()# 一种防止过拟和的操作。在训练的时候,随机砍掉一些神经元。完成之后再恢复。
self.fc1 = nn.Linear(320, 50)# 第一个全连接层,第一个数字是输入单元数,第二个是输出单元数
self.fc2 = nn.Linear(50, 10)# 第二个全连接层。(一共10种数字第二次输出就是10)
def forward(self, x):# 向前传播计算
x = F.relu(F.max_pool2d(self.conv1(x), 2))# 一次卷积,然后池化+非线性激活函数
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))# 第二次卷积+池化+非线性激活函数
x = x.view(-1, 320)# 把张量变成1维的
x = F.relu(self.fc1(x))# 第一次全连接,然后加激活函数
x = F.dropout(x, training=self.training)# 进行一次Dropout,防止过拟合
x = F.relu(self.fc2(x))# 第二次全连接+激活函数
return F.log_softmax(x)# 输出结果
嘿嘿,这个注释详细吧。。。
都是我自己的理解,有啥不对的地方欢迎大佬们指出。
代码编写
数据集加载。老传统了,一个训练,一个测试,过程就不详解了。。
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('/cos_public/mnist/', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('/cos_public/mnist/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
有一点要注意啊,,我这里的'/cos_public/mnist/'是数据在腾讯的智能钛平台上的路径。你们要么改成自己的。
使用SGD优化器
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
训练代码。
def train(epoch):
model.train()# 表示是训练,model会跟新参数
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:# 使用GPU
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()# 梯度清0
output = model(data)# 走一遍模型
loss = F.nll_loss(output, target)# 计算损失
loss.backward()# 反向传播
optimizer.step()# 跟新所有参数
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data))
测试代码,就是单纯的跑一遍模型,计算下损失,就不详细注释了。
def test(epoch):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).data
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
test_loss /= len(test_loader) # loss function already averages over batch size
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
代码的大部分我们都完成了。但是!!我们是要在腾讯云的平台上让别人帮我们跑模型的。。所以,,还要加点输入参数和最后模型的保存。。所以完整代码为:
from __future__ import print_function
import argparse
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
# Training settings(看到这一堆,莫慌!我直接照着腾讯云的拿过来的。就是些后面要用的参数定义。然后下面的逻辑部分我前面都注释了。)
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=10, metavar='N',
help='number of epochs to train (default: 10)')
parser.add_argument('--lr', type=float, default=0.01, metavar='LR',
help='learning rate (default: 0.01)')
parser.add_argument('--momentum', type=float, default=0.5, metavar='M',
help='SGD momentum (default: 0.5)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='enables CUDA training')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--export_dir', type=str,
help='path to export the train model (.pkl file)')
args = parser.parse_args()
args.cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
if args.cuda:
torch.cuda.manual_seed(args.seed)
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('/cos_public/mnist/', train=True, download=False,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('/cos_public/mnist/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=args.batch_size, shuffle=True, **kwargs)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = F.relu(self.fc2(x))
return F.log_softmax(x)
model = Net()
if args.cuda:
model.cuda()
optimizer = optim.SGD(model.parameters(), lr=args.lr, momentum=args.momentum)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data))
def test(epoch):
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.nll_loss(output, target).data
pred = output.data.max(1)[1] # get the index of the max log-probability
correct += pred.eq(target.data).cpu().sum()
test_loss = test_loss
test_loss /= len(test_loader) # loss function already averages over batch size
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, args.epochs + 1):
train(epoch)
test(epoch)
torch.save(model.state_dict(), args.export_dir) #最后一步。保存模型。。腾讯云官方不会给我们保存的,,,所以代码中要自己写清楚。
最后一步要注意,我把模型保存到了args.export_dir中,也就是输入参数中的最后一项。。那一项写你要保存的腾讯云的路径即可。
训练
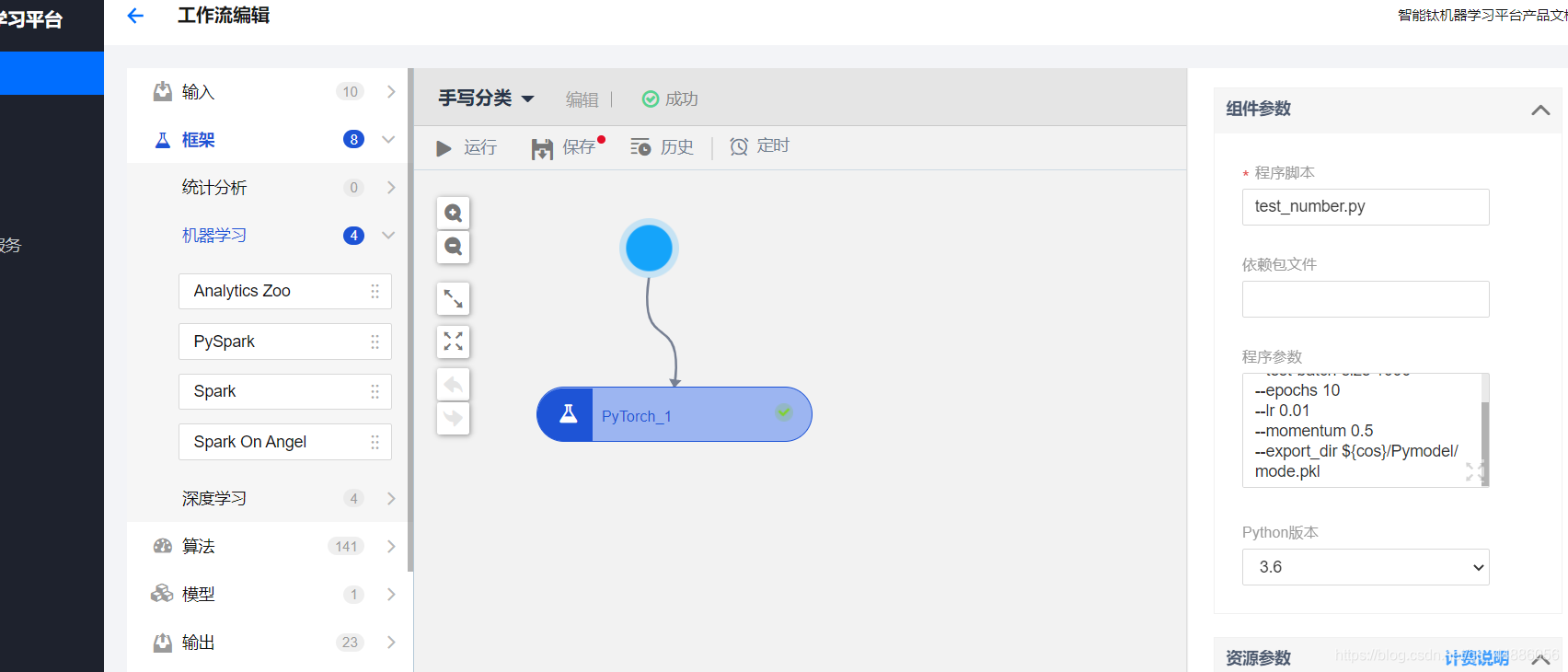
上传代码。参数我写的这个
--batch-size 64
--test-batch-size 1000
--epochs 10
--lr 0.01
--momentum 0.5
--export_dir ${cos}/Pymodel/mode.pkl
最后一项就是模型保存的地方。
点击运行就开始了。训练好了之后,
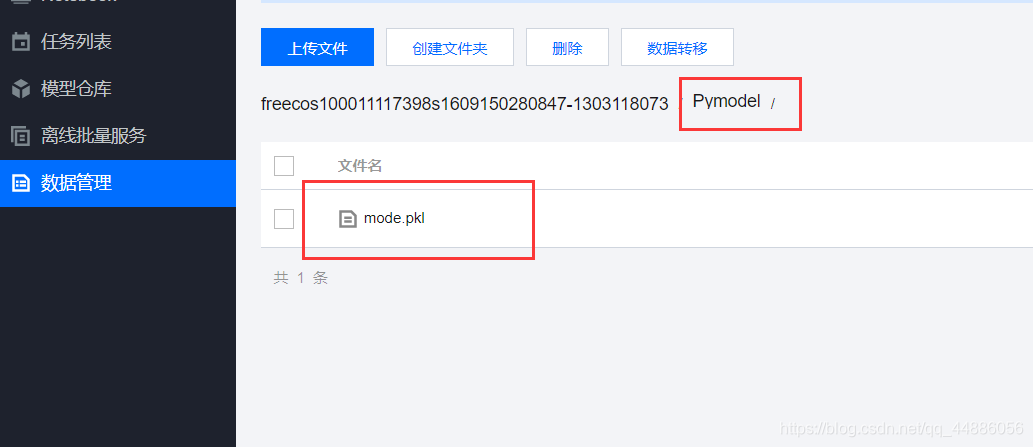
模型就在这儿了,下下来即可
模型测试
使用下面的代码进行下测试:
class Net(nn.Module): # 模型定义,就不用说了吧,前面一样
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = F.relu(self.fc2(x))
return F.log_softmax(x,dim=1)
img = Image.open("./9.png") # 打开要测试的图片
plt.imshow(img) # 显示下看看
# [N, C, H, W]
train_transform = transforms.Compose([ # 我们训练数据的时候,怎么操作了,现在就要把我们要测试的数据也转化成训练的时候的样子。
transforms.Grayscale(),
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
img = train_transform(img)# 进行转化
# expand batch dimension
img = torch.unsqueeze(img, dim=0)# 维度转化
# create model
model = Net() # 定义模型
# load model weights
model_weight_path = "./mode.pkl" # 加载我们训练好的权重
model.load_state_dict(torch.load(model_weight_path))
# 定义数组,方便输出显示的数字
index_to_class = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
model.eval()
with torch.no_grad(): # 测试,所以不计算梯度
# predict class
y = model(Variable(img)) # 走一遍模型
# print(y.size())
output = torch.squeeze(y) # 维度转化
# print(output)
predict = torch.softmax(output, dim=0) # 拿到的数据进行映射
# print(predict)
predict_cla = torch.argmax(predict).numpy() # 获取映射后最大的的值
# print(predict_cla)
print(index_to_class[predict_cla], predict[predict_cla].numpy()) # 输出最大可能的值,和它的概率
plt.show() # 图片展示
关于手写图片嘛,,直接打开电脑自带的图画(注意,训练的时候背景是黑的,所以我们也要这样,然后大小是45x45(训练的数据是45x45的)。)。
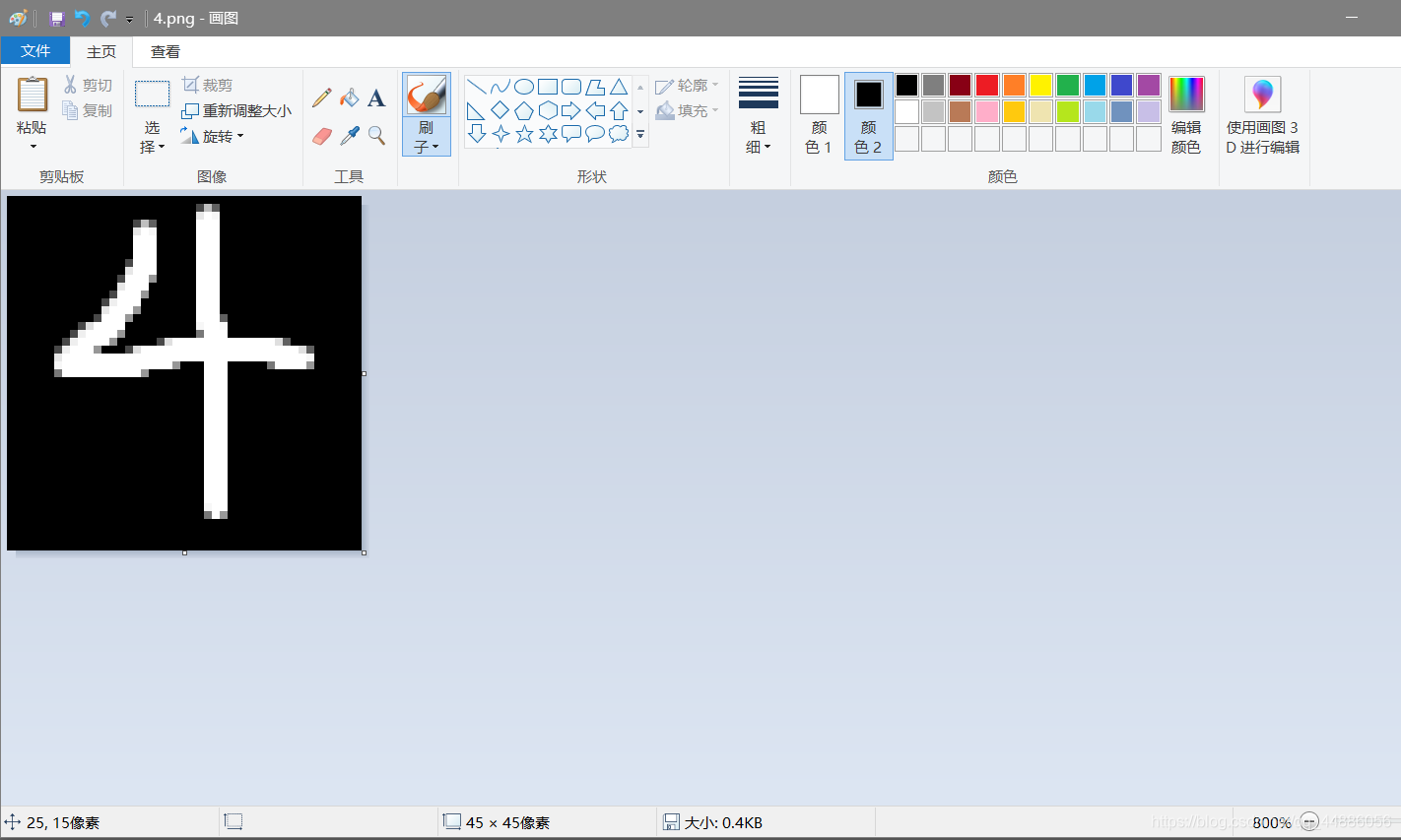
然后跑起来试试叭
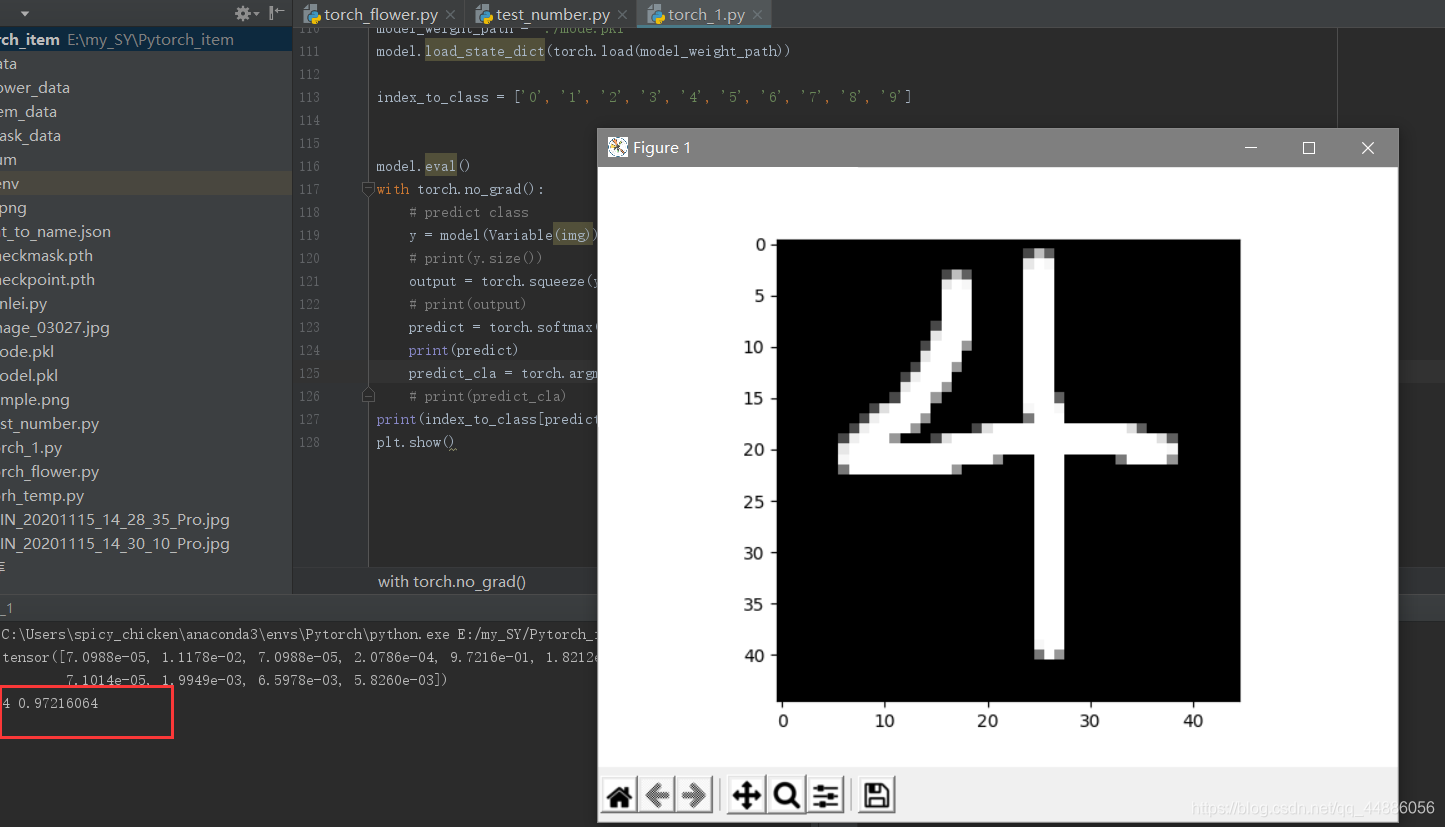
嘿嘿,,识别出结果是4,几率是97%。














 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









