







前面介绍了如何构建自己的ArcGIS工具箱,能够极大地减轻繁琐重复的工作,可查看:
【教程】如何自制一个ArcGIS工具箱(ArcPy和模型构建器的使用)
除了制作工具箱来实现自动处理重复性的工作,还可以使用ArcPy来快速批量地处理数据。相比于使用模型构建器,ArcPy在操作和处理数据上则更加灵活。对于一些工具的参数具有“二级参数”,比如下图中的焦点统计工具,如果选择邻域分析中的【权重】,则需要继续输入对应的核文件,但是在用模型构建器处理时,并不能将核文件这一参数作为输入,从而进行循环处理。这时就可以考虑采用ArcPy,从文件夹下批量获取核文件,然后循环处理就可以了。
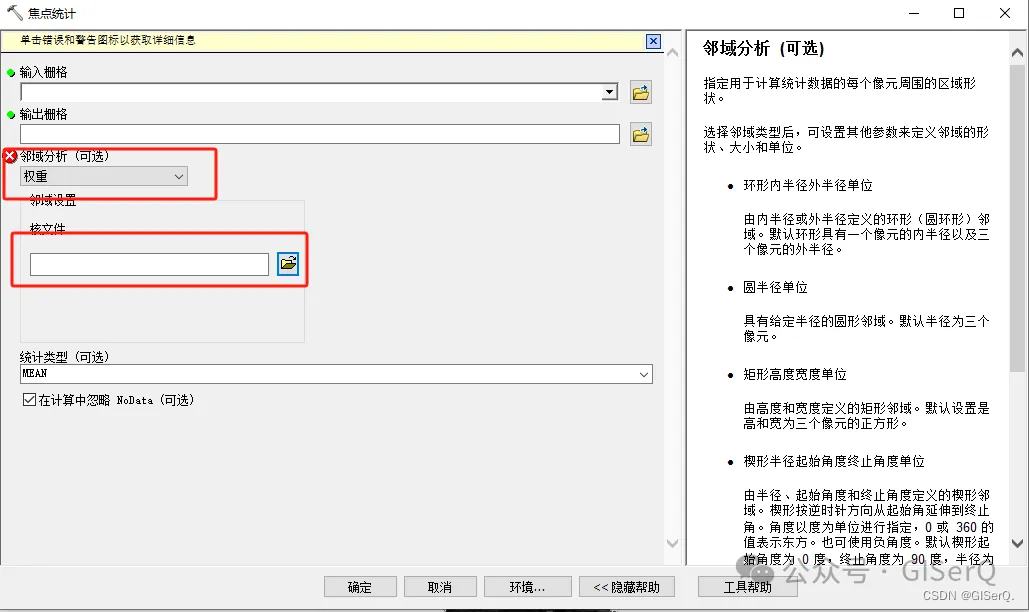
【焦点统计】的使用方法以及示例代码可以在【工具帮助】中找到:
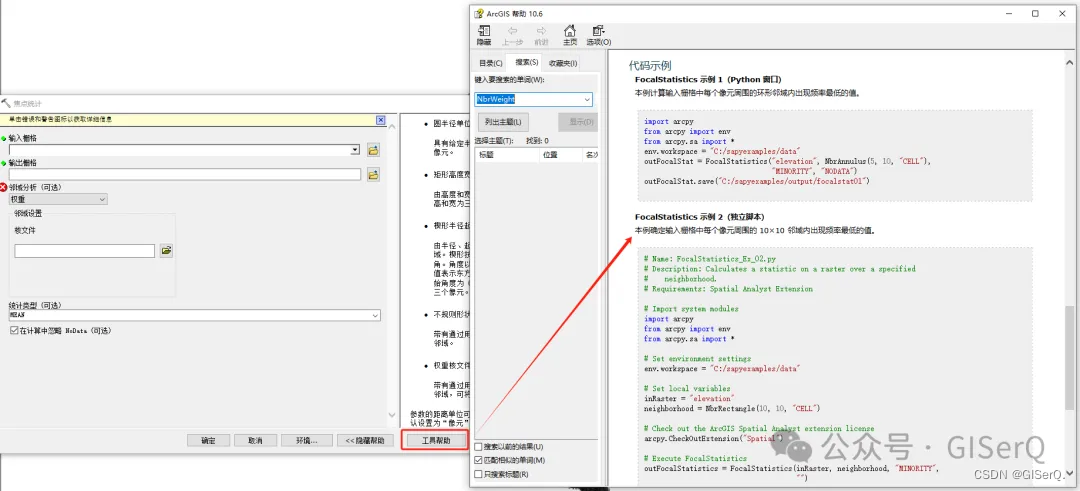
然后需要做的就是循环获取文件夹下的核文件进行处理,代码如下:
# coding=utf-8
import arcpy
from arcpy import env
from arcpy.sa import *
import os
import numpy as np
# 存放核文件的文件夹
arcpy.env.workspace = "D/weights"
arcpy.env.overwriteOutput = True
# 获取栅格数据
inRaster = r"D\DEM.tif"
# 获取文件夹下所有权重文件
weight_files = arcpy.ListFiles("*.txt")
# 批量计算
for weight_file in weight_files:
# 获取权重文件路径和名称
weight_path = os.path.join(arcpy.env.workspace, weight_file)
weight_name = os.path.splitext(weight_file)[0]
arcpy.CheckOutExtension("Spatial")
outFocalStatistics = FocalStatistics(inRaster, NbrWeight(weight_path), "MEAN", "")
# 写出结果
out_path = os.path.join("D/weights", weight_name+".tif")
outFocalStatistics.save(out_path)
这样就可以实现了批量处理,ArcGIS每个工具箱的参数都可以在帮助文档中找到详细的说明和示例,即使是编程初初学者也可以看懂,快速实现批处理的功能。
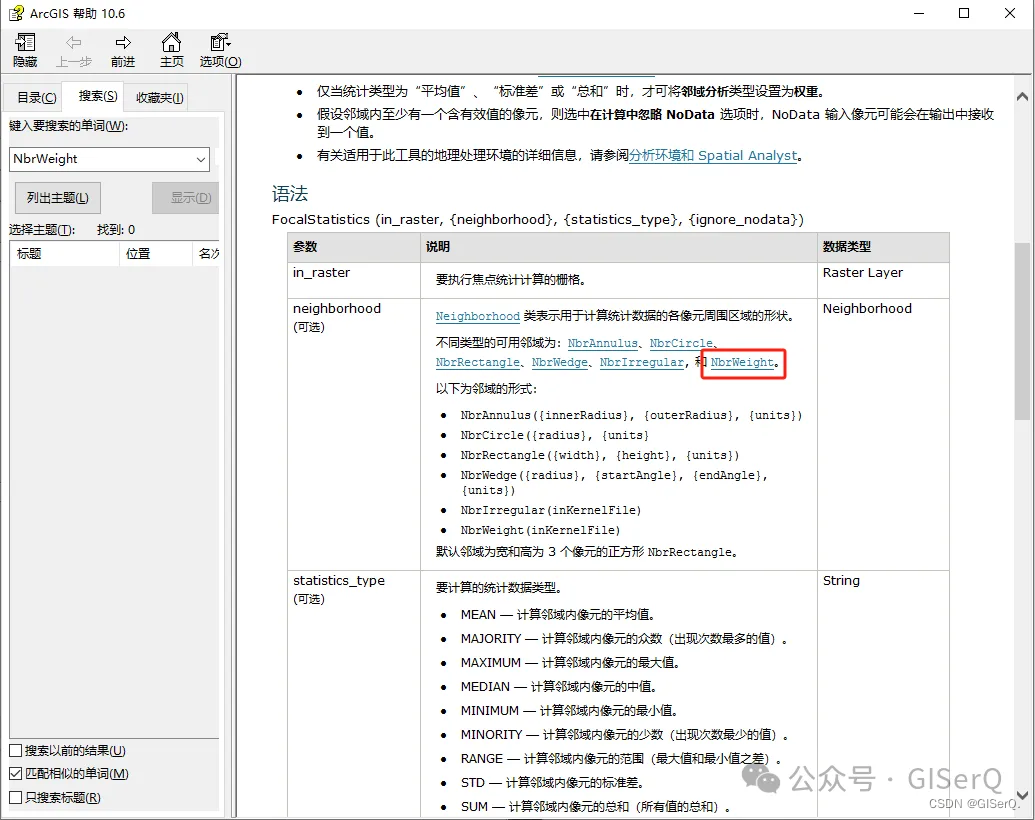
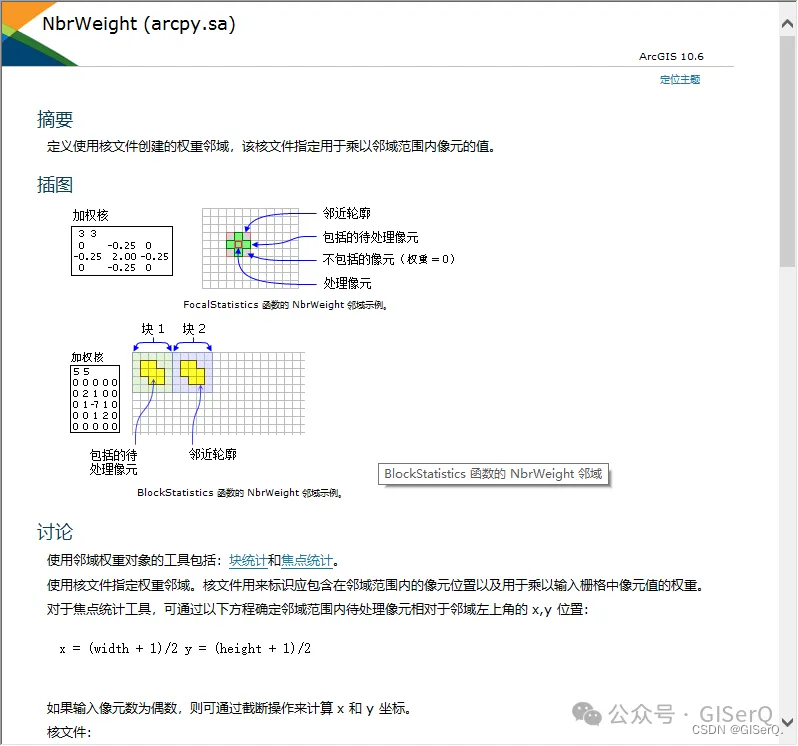
比如点击其中一个参数,就会跳转到对这个参数的详细解释,并且附有使用示例,十分清楚:

















 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











