







 本文提出了一种基于元学习的对抗性领域增强方法(MADA),旨在解决单领域泛化问题。该方法通过对抗性训练生成虚拟领域,提升单一训练域模型在未见过的目标域上的泛化能力。使用自动编码器(WAE)放松语义一致性约束,实现更广泛的领域覆盖。
本文提出了一种基于元学习的对抗性领域增强方法(MADA),旨在解决单领域泛化问题。该方法通过对抗性训练生成虚拟领域,提升单一训练域模型在未见过的目标域上的泛化能力。使用自动编码器(WAE)放松语义一致性约束,实现更广泛的领域覆盖。
介绍
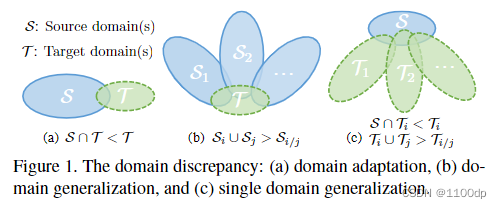
如图1所示:领域自适应通常希望目标域(未标记或已标记)的可用性。而领域泛化通常假设多个域用于训练。
single domain目标:从一个源域生成多个目标域的数据。训练数据和测试数据的分布不同,需要对数据进行泛化。
这篇文章的主要工作:
- 考虑一个模型能够在许多不可见域上表现良好,而只有一个域可供训练的场景。
- 提出一种基于元学习的对抗性领域增强的方法来解决单领域泛化问题。
- 通过对抗性训练生成“虚拟”领域,来提高单个领域的泛化能力。
- 使用自动编码器(WAE)来放松广泛使用的最坏情况约束。
自动编码器(WAE):重新提取特征,降低维度,最小化重构错误。还可以降低特征的维度。
元学习:找到一个好的初始化,它可以在几个梯度步骤内快速适应新任务。
对抗训练:用于提高模型对对抗性扰动或攻击的鲁棒性。
模型
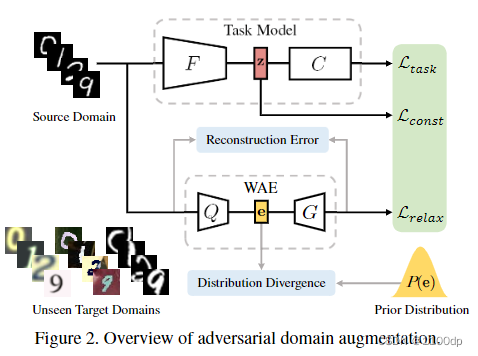
对抗域增强:由一个任务模型和自动编码器组成。如图2所示,任务模型由一个特征提取器F将输入空间映射到嵌入空间,还有一个分类器C用来从嵌入空间预测标签。

整体损失(目标函数
L
A
D
A
L_{ADA}
LADA) = 分类损失 - 语义一致性约束 + 大领域输出
采用迭代的方式在增广域S+中生成对抗样本x+,Lconst对对抗样本施加语义一致性约束。直观地说,Lconst 控制了由 Wasserstein 距离 测量的源域之外的泛化能力。然而,Lconst 产生有限的域传输,因为它严重限制了样本之间的语义距离及其扰动。因此,提出了 Lrelax 来放松语义一致性约束并创建大域传输。
作者期望增强域S+与源域S有很大不同,也就是希望最大化S+和S之间的域差异。但是,语义一致性约束 Lconst 将严重限制从 S 到 S+ 的域传输,对产生理想的 S+ 提出了新的挑战。为了解决这个问题,作者建议 Lrelax 来鼓励域外增强。
使用自动编码器来实现Lrelax
算法
技术障碍1:由于最坏情况公式中的语义一致性约束的矛盾,很难创建与源域不同的虚拟域。
技术障碍2:希望探索许多“虚构”域来保障足够的覆盖,这可能会导致巨大的计算开销。
解决方案:通过元学习组织对抗性领域增强,得到一个单域泛化的高效模型。

V:作为鉴别器来区分增强是否在源域之外,
利用元学习方案来训练单个模型。为了模拟源域 S 和目标域 T 之间的真实域转移,在每次学习迭代中,对源域 S 执行元训练并在所有增强域 S+ 上执行元测试。
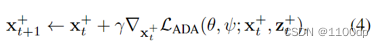
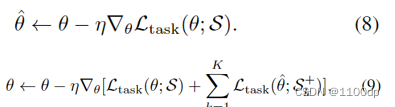
元训练:Ltask对来自源域S的样本进行计算,并且模型参数
θ
\theta
θ通过一个或多个梯度更新,
η
\eta
η为学习率。
元测试:计算每个增强域
S
k
+
S^+_k
Sk+上的损失。
元更新:通过组合损失计算的梯度来更新
θ
\theta
θ
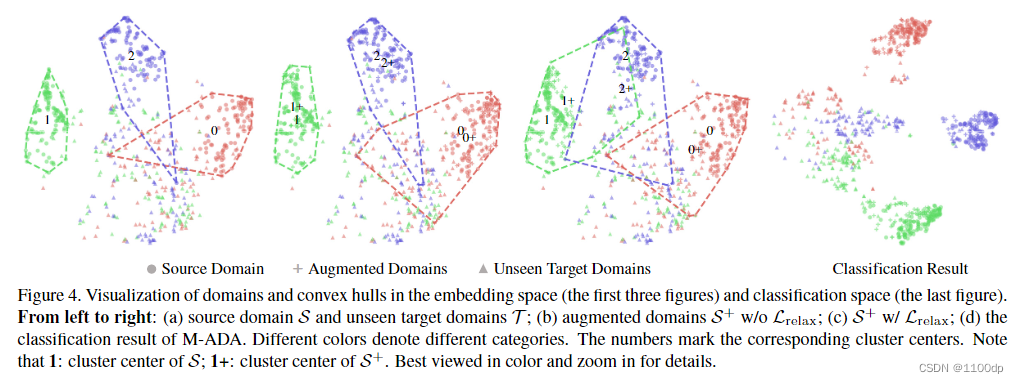
实验
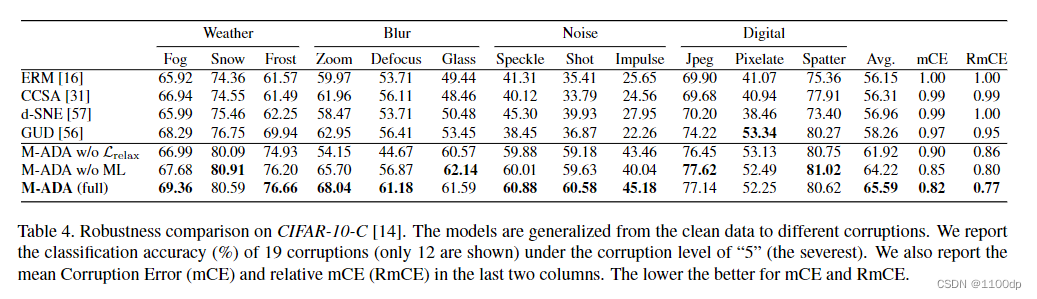
作者将自己的方法与小样本域适应的先进方法进行比较,发现MADA具有不错的效果。


















 1347
1347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











