







一、数据接口分析
主页地址:猿人学第十三题
1、抓包
通过抓包可以发现数据接口是api/match/13
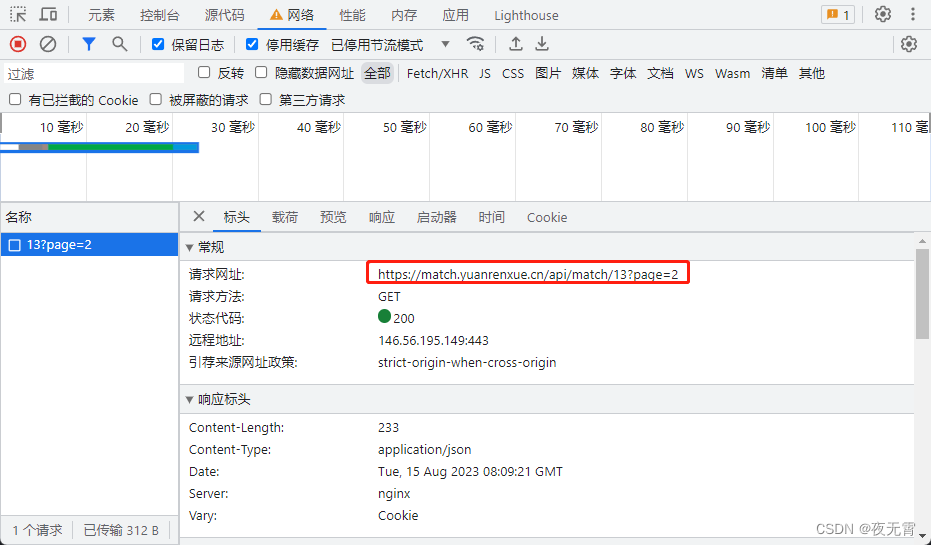
2、判断是否有加密参数
- 请求参数是否加密?
无 - 请求头是否加密?
无 - 响应是否加密?
无 - cookie是否加密?
在“cookie”模块中可以发现有一个yuanrenxue_cookie的加密cookie

二、加密位置定位
通过查找发现js代码中并没有找到对yuanrenxue_cookie的赋值操作,所以观察抓包。
删除该cookie后,重新刷新页面,发现浏览器请求页面发了两次包,而且第一个包的响应数据,浏览器无法加载
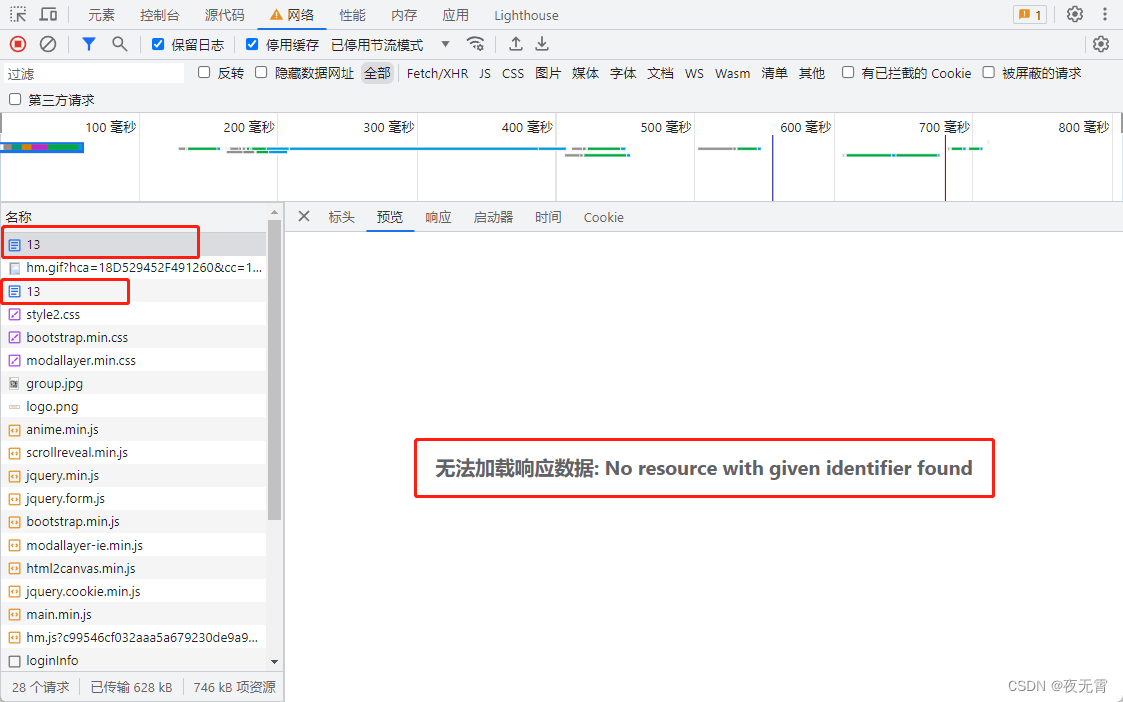
此时,可以尝试使用python发一个请求给这个地址,观察一下返回的响应数据。通过打印的响应的数据可以发现,第一个包响应的数据就是设置cookie的js代码,并且就只是简单的字符拼接起来。

源代码:
"""
Email:912917367@qq.com
Date: 2023/8/2 9:57
"""
import re
import requests
headers = {
"authority": "match.yuanrenxue.cn",
"referer": "https://match.yuanrenxue.cn/match/13",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
}
cookies = {
"sessionid": "25yk747fkvd7oiq7oxa6wcagntbj5iso",
}
url = "https://match.yuanrenxue.cn/match/13"
response = requests.get(url, headers=headers, cookies=cookies)
re_str = r"\('(.+?)'\)"
cookie = ''.join(re.findall(re_str, response.text))
cookie_value = cookie.split('=')[1]
cookies['yuanrenxue_cookie'] = cookie_value
url = 'https://match.yuanrenxue.cn/api/match/13'
num = 0
for page in range(1, 6):
params = {
'page': str(page)
}
if page >= 4:
headers['user-agent'] = 'yuanrenxue.project'
response = requests.get(url, params=params, cookies=cookies, headers=headers)
data = response.json()['data']
for item in data:
num += item['value']
print(num)















 1798
1798











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









