







1. 目标网址
目标网站:猿人学web第13题
2. 抓包分析
浏览器打开无痕模式,看第一页数据包:
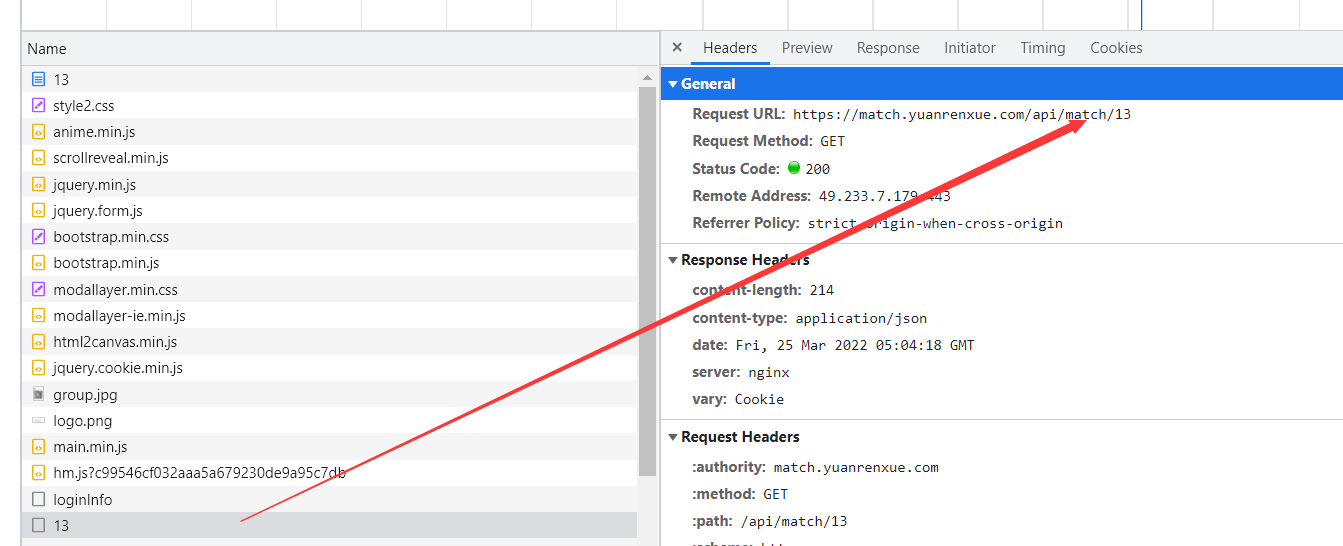
两个名叫13的包,第二个有数据,是请求了一个api接口,第一个推断应该是加载了cookie。
点一下第二页:
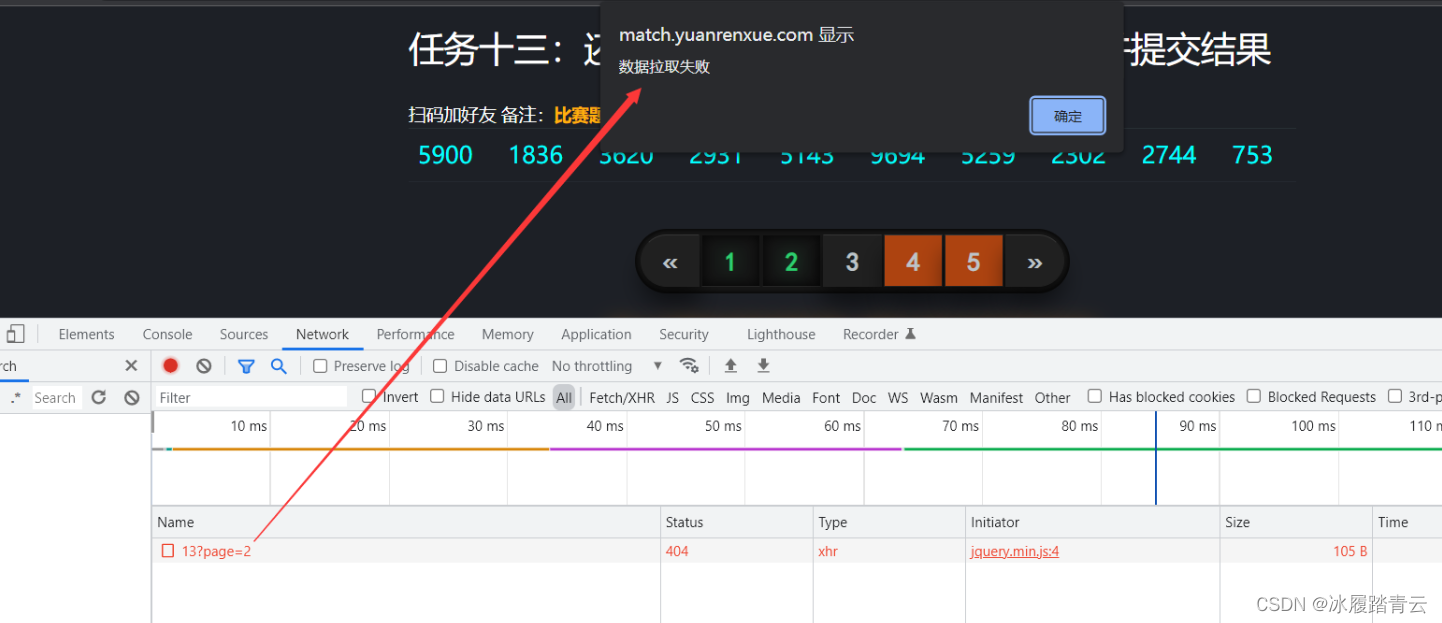
发现抓不到这个包,说明有cookie验证。
我们不用无痕窗口看一下第二页:
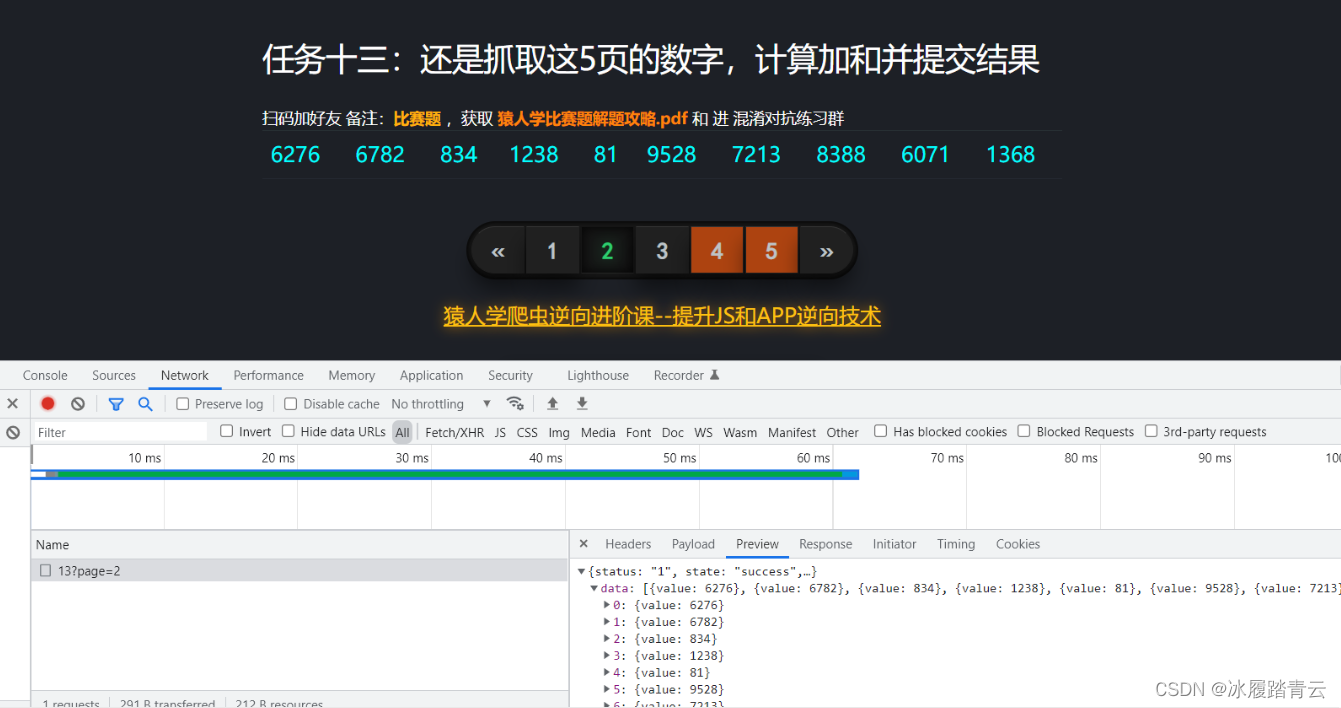
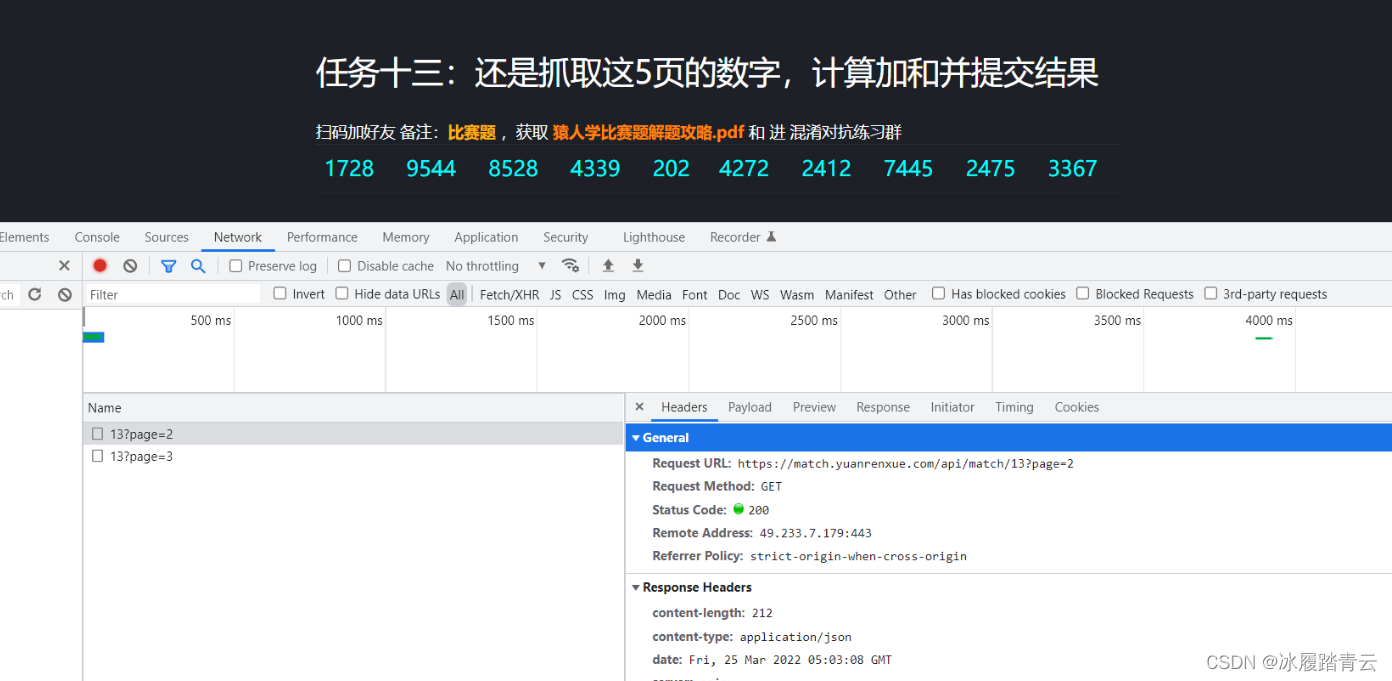
发现是可以看的,所以接下来我们的解决思路就有了,我们先直接对这个网站发请求:
import requests
session = requests.Session()
headers = {
"User-Agent": "yuanrenxue.project",
}
url = "http://match.yuanrenxue.com/match/13"
r = session.get(url)
print(r.text)
结果:
<script>document.cookie=('y')+('u')+('a')+('n')+('r')+('e')+('n')+('x')+('u')+('e')+('_')+('c')+('o')+('o')+('k')+('i')+('e')+('=')+('1')+('6')+('4')+('8')+('1')+('8')+('5')+('0')+('8')+('2')+('|')+('9')+('I')+('B')+('q')+('4')+('J')+('X')+('j')+('u')+('e')+('i')+('R')+('B')+('Q')+('V')+('C')+('T')+('x')+('j')+('E')+('m')+('u')+('C')+('G')+('r')+('K')+('m')+('E')+('A')+('W')+('8')+('r')+('B')+('q')+('H')+('x')+('w')+('b')+('l')+('b')+('m')+('p')+('r')+('p')+('Y')+('y')+('X')+('m')+('2')+('e')+('z')+('6')+('K')+('L')+('g')+('T')+('s')+('b')+('E')+('N')+('J')+('j')+('E')+('M')+('D')+('z')+('L')+('I')+('7')+('V')+('5')+('Y')+('5')+('V')+('A')+('J')+('M')+('4')+('f')+('D')+('4')+('Q')+('G')+('2')+('9')+('M')+('C')+('u')+('8')+('B')+('P')+('c')+('1')+('1')+('7')+('c')+('d')+('w')+('v')+('m')+('V')+('D')+('v')+('W')+';path=/';location.href=location.pathname+location.search</script>
发现响应里面是分开凑的cookie,我们看一下第一页第一个包的cookie:
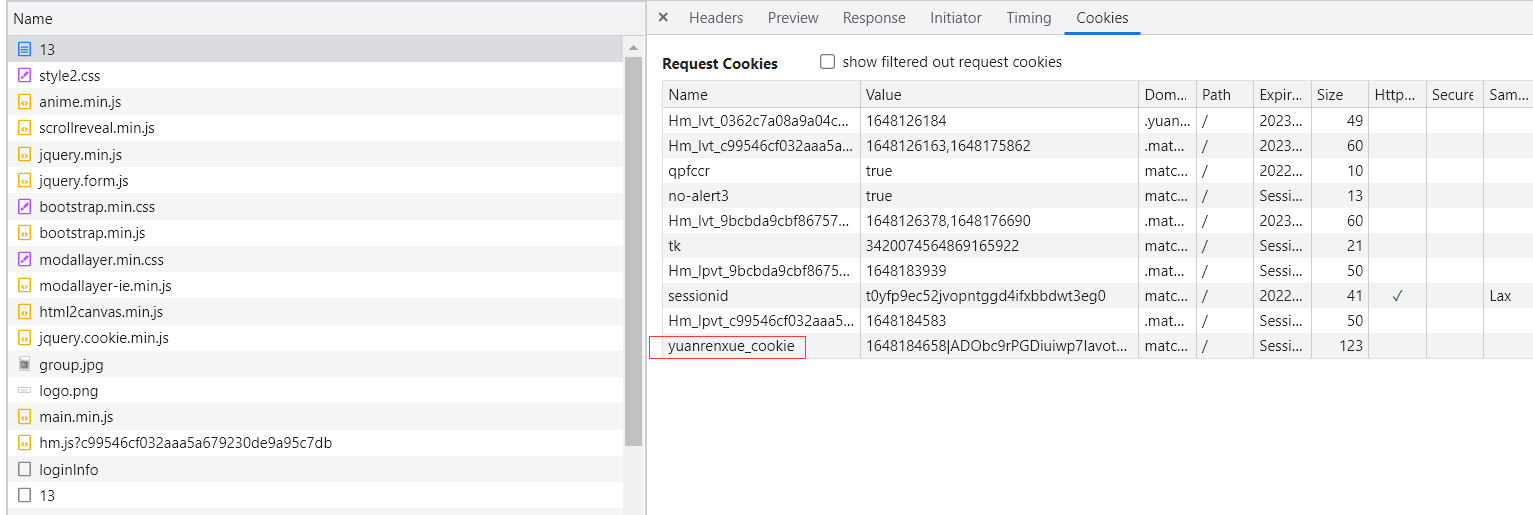
是有这个yuanrenxue_cookie的,接下来我们就只需要把cookie拼接完整,
然后拿到这个cookie,再用它保持会话状态去向其他页发请求应该就可以了。
3. 编码测试
注意:第四页和第五页的数据必须要用账号登录,把cookie放到程序里才可以拿到,并且sessionid必须在浏览器一直是登录状态才有效,一旦退出登录,sessionid会失效
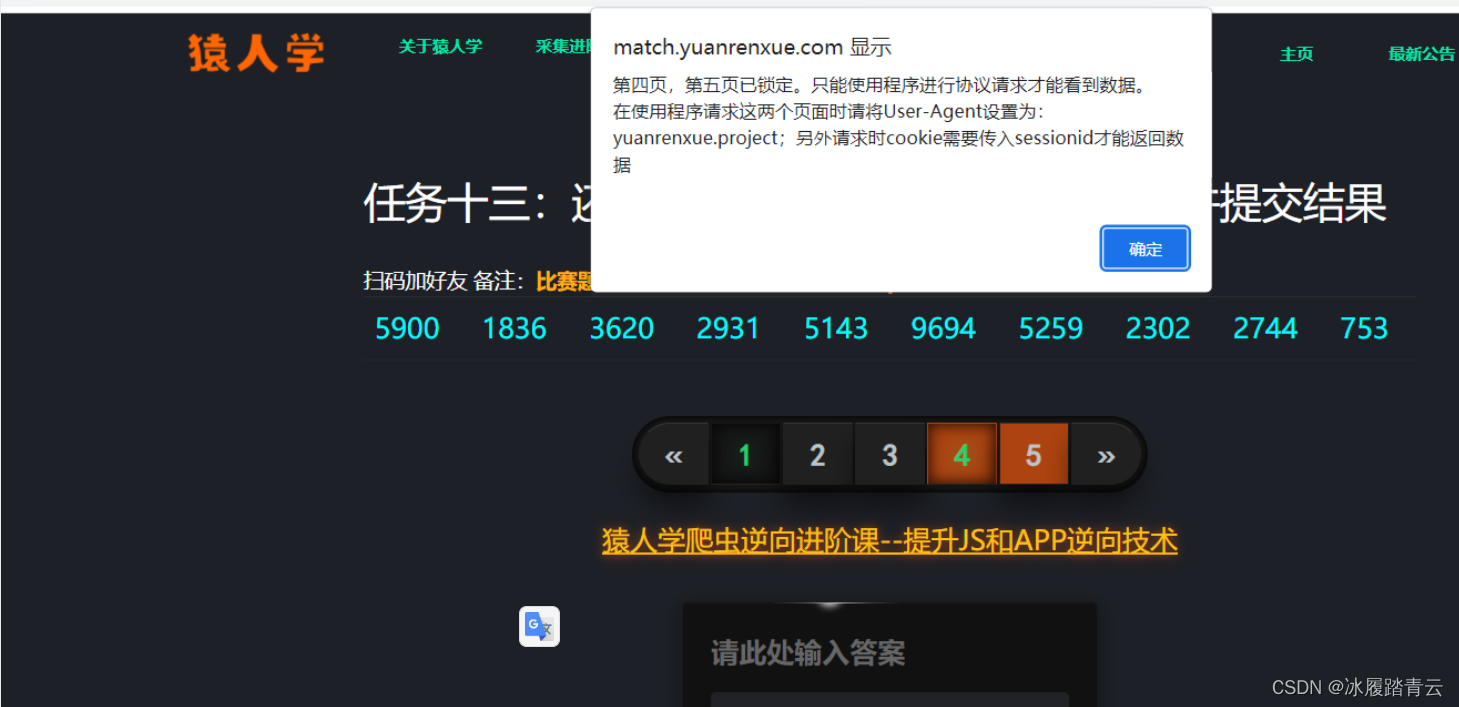
这里先拿前三页:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 冰履踏青云
# @File : 13.py
import requests
import re
import jsonpath
def get_data(page):
session = requests.Session()
headers = {
"User-Agent": "yuanrenxue.project",
}
url = "http://match.yuanrenxue.com/match/13"
r = session.get(url)
# print(r.text)
results = re.findall("'([a-zA-Z0-9=|_])'",r.text)
# print(results)
cookie = ''.join(results)
# print(cookie)
key, value = cookie.split('=')
session.cookies.set(key, value)
api_url = 'https://match.yuanrenxue.com/api/match/13?page={}'.format(str(page))
res = session.get(api_url,headers=headers)
# print(res.json())
values_list = jsonpath.jsonpath(res.json(),"$..value")
return values_list
if __name__ == '__main__':
res_list = []
for i in range(1, 4):
values_list = get_data(i)
res_list.extend(values_list)
print(res_list,len(res_list))
print('前三页所有数字之和为:',sum(res_list))
结果:

我再登录一下,把cookie复制一下,把五页全部拿完:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Author : 冰履踏青云
# @File : 13.py
import requests
import re
import jsonpath
def get_data(page):
session = requests.Session()
# 每次请求cookie都加上sessionid
requests.utils.add_dict_to_cookiejar(session.cookies, {"sessionid": "t0yfp9ec52jvopntggd4ifxbbdwt3eg0"})
headers = {
"User-Agent": "yuanrenxue.project",
}
url = "http://match.yuanrenxue.com/match/13"
r = session.get(url)
# print(r.text)
results = re.findall("'([a-zA-Z0-9=|_])'",r.text)
# print(results)
cookie = ''.join(results)
print(cookie)
key, value = cookie.split('=')
session.cookies.set(key, value)
cookie = {"cookie":"sessionid=t0yfp9ec52jvopntggd4ifxbbdwt3eg0"}
api_url = 'https://match.yuanrenxue.com/api/match/13?page={}'.format(str(page))
res = session.get(api_url,headers=headers)
# print(res.json())
values_list = jsonpath.jsonpath(res.json(),"$..value")
return values_list
if __name__ == '__main__':
res_list = []
for i in range(1, 6):
values_list = get_data(i)
# print(values_list)
res_list.extend(values_list)
print(res_list,len(res_list))
print('所有数字之和为:',sum(res_list))
结果:

这里代码只需要换上你自己登录之后的sessionid就可以了,这个sessionid每次登录都不一样,退出登录就会失效,所以运行程序时浏览器要保持登录状态。
文章到此结束,但愿本文能对你有一点点帮助,欢迎三连,点个赞,收个藏啥的,有问题的尽管砸来,我有故事你有酒,好好交流不分手!下次见!

















 6204
6204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











