









1、C++ 使用ZLIB库实现目录压缩与解压
在软件开发和数据处理中,对数据进行高效的压缩和解压缩是一项重要的任务。这不仅有助于减小数据在网络传输和存储中的占用空间,还能提高系统的性能和响应速度。本文将介绍如何使用 zlib 库进行数据的压缩和解压缩,以及如何保存和读取压缩后的文件。 zlib 是一个开源的数据压缩库,旨在提供高效、轻量级的压缩和解压缩算法。其核心压缩算法基于 DEFLATE,这是一种无损数据压缩算法,通常能够提供相当高的压缩比。zlib 库广泛应用于多个领域,包括网络通信、文件压缩、数据库系统等。
1、保存文件
使用 CreateFile 打开文件,通过 WriteFile 向文件中写出数据,最后调用 CloseHandle 关闭句柄,实现文件的保存。
// ConsoleApplication1.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#define ZLIB_WINAPI
#include <string>
#include <iostream>
#include <vector>
#include <Shlwapi.h>
#include <zip.h>
#include <unzip.h>
#include <zlib.h>
using namespace std;
#pragma comment(lib, "Shlwapi.lib")
#pragma comment(lib, "zlibstat.lib")
BOOL SaveToFile(wchar_t *pszFileName, BYTE *pData, DWORD dwDataSize)
{
wchar_t szSaveName[MAX_PATH] = { 0 };
lstrcpy(szSaveName, pszFileName);
HANDLE hFile = CreateFile(szSaveName, GENERIC_READ | GENERIC_WRITE,
FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_ARCHIVE, NULL);
if (INVALID_HANDLE_VALUE == hFile)
{
return FALSE;
}
DWORD dwRet = 0;
WriteFile(hFile, pData, dwDataSize, &dwRet, NULL);
CloseHandle(hFile);
return TRUE;
}
int _tmain(int argc, _TCHAR* argv[])
{
char szBuffer[1024] = { 0 };
strcpy_s(szBuffer,sizeof("test__123123"), "test__123123");
SaveToFile(L"F:\\vs2013_code\\ConsoleApplication2\\Debug\\1.txt", (BYTE *)szBuffer, sizeof(szBuffer));
system("pause");
return 0;
}
-
这段代码是一个简单的C++控制台应用程序,它定义了一个函数 SaveToFile 来将数据保存到文件,并在 main 函数中测试这个功能。下面是这段代码的中文解释:
- 头文件包含部分:
- 这里包含了程序所需的头文件。
- stdafx.h 是预编译头文件,用于加速编译过程。ZLIB_WINAPI 宏定义表明我们将在Windows API模式下使用zlib库。其他包含的文件提供了字符串操作、输入输出流、向量容器和文件路径操作的功能。zip.h、unzip.h和zlib.h是zlib库的一部分,用于压缩和解压缩文件。
- 这里包含了程序所需的头文件。
- 库链接指令:
- #pragma comment(lib, “Shlwapi.lib”)
- #pragma comment(lib, “zlibstat.lib”)
- 这些行指示链接器链接到 Shlwapi.lib(Shell轻量级实用工具库)和 zlibstat.lib(zlib静态库)。
- SaveToFile 函数:
- SaveToFile 函数接受一个文件名、一个指向数据的指针和数据的大小,然后创建一个文件并将数据写入该文件。
- _tmain 函数:
- _tmain 是程序的入口点。在这里,它创建了一个字符数组szBuffer,使用strcpy_s函数将字符串 “test 123123” 复制到szBuffer中,然后调用SaveToFile函数将这个缓冲区保存到硬盘上的一个文件中。
- 头文件包含部分:
-
SaveToFile 函数的具体操作:
- 定义一个宽字符数组szSaveName用于存放将要保存的文件的路径。
- 使用lstrcpy函数将传入的文件路径pszFileName复制到szSaveName。
- 调用CreateFile函数创建或覆盖文件szSaveName。
-
在这段代码中,调用CreateFile函数创建或覆盖文件szSaveName的行为体现在CreateFile函数的dwCreationDisposition参数上。在这个例子中,这个参数被设置为CREATE_ALWAYS。
-
CREATE_ALWAYS是CreateFile函数的一个选项,它指示操作系统,无论目标文件是否存在,都创建一个新文件。如果文件已经存在,使用CREATE_ALWAYS会导致现有文件被覆盖。这意味着,如果szSaveName指定的文件已经存在于磁盘上,它将被新文件替换,从而体现了"覆盖"的行为。
-
简而言之,通过使用CREATE_ALWAYS作为dwCreationDisposition的参数值,CreateFile函数在这段代码中不仅可以用来创建一个新文件,也可以用来覆盖一个已经存在的文件。如果操作成功,旧的文件内容会被丢弃,并开始写入新的内容;如果操作失败,例如由于权限问题或路径问题,函数将返回INVALID_HANDLE_VALUE。
-
如果目的是追加内容到一个已存在的文件,而不是覆盖它,你可以使用CreateFile函数的另一个参数选项
OPEN_EXISTING或OPEN_ALWAYS,配合文件指针移动函数SetFilePointer和写入函数WriteFile来实现。OPEN_EXISTING: 打开文件仅当它存在。如果文件不存在,CreateFile将失败。OPEN_ALWAYS: 打开文件如果它存在,如果不存在则创建一个新文件。这与CREATE_ALWAYS不同,因为CREATE_ALWAYS会覆盖已存在的文件,而OPEN_ALWAYS在文件已存在时不会覆盖现有内容。
为了追加内容,可以这样做:- 使用
CreateFile函数打开(或创建)文件,dwCreationDisposition参数使用OPEN_ALWAYS。
调用SetFilePointer函数将文件指针移动到文件末尾。SetFilePointer的dwMoveMethod参数设置为FILE_END,lDistanceToMove设置为0,这样文件指针就会定位到文件的末尾,准备追加内容。
使用WriteFile函数写入新内容,写入的内容将添加到文件的末尾,而不是覆盖原有内容。- 以下是示例代码,展示如何修改SaveToFile函数以追加内容到文件而不是覆盖:
-
BOOL AppendToFile(wchar_t *pszFileName, BYTE *pData, DWORD dwDataSize) { wchar_t szSaveName[MAX_PATH] = { 0 }; lstrcpy(szSaveName, pszFileName); // 使用OPEN_ALWAYS选项打开或创建文件 HANDLE hFile = CreateFile(szSaveName, GENERIC_WRITE, FILE_SHARE_READ, NULL, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL, NULL); if (INVALID_HANDLE_VALUE == hFile) { return FALSE; } // 将文件指针移动到文件末尾 SetFilePointer(hFile, 0, NULL, FILE_END); DWORD dwRet = 0; WriteFile(hFile, pData, dwDataSize, &dwRet, NULL); CloseHandle(hFile); return TRUE; }
-
如果文件创建成功,使用WriteFile函数将传入的数据pData写入文件。
-
关闭文件句柄并返回操作结果。
-
-
-
_tmain 函数的具体操作:
- 定义一个缓冲区szBuffer并使用strcpy_s安全复制函数初始化这个缓冲区。
- 调用SaveToFile函数,将szBuffer中的数据保存到F:\vs2013_code\ConsoleApplication2\Debug\1.txt。
- 程序暂停等待用户操作,之后退出。
整个程序的目的是演示如何安全地将数据写入到文件中,并在主函数中测试这个功能。程序将字符串 “test 123123” 保存到指定的文本文件中。
2、文件压缩
compress 是 zlib 库提供的用于数据压缩的函数,通过该函数可以将数据进行压缩。下面是一个示例,演示了如何使用 zlib 库进行文件压缩。
它的原型如下:
int compress(Bytef* dest, uLongf* destLen, const Bytef* source, uLong sourceLen);
- dest:指向存放压缩后数据的缓冲区的指针。
- destLen:传入时为压缩缓冲区的大小,传出时为实际压缩后数据的大小。
- source:指向待压缩数据的缓冲区的指针。
- sourceLen:待压缩数据的大小。
compress 函数的作用是将 source 指向的数据进行压缩,并将结果存放在 dest 指向的缓冲区中。destLen 传入时应该是 dest 缓冲区的大小,函数执行后,destLen 会更新为实际压缩后数据的大小。
函数返回值为压缩的执行状态,可能的返回值包括:
- Z_OK:压缩成功。
- Z_MEM_ERROR:内存分配失败。
- Z_BUF_ERROR:压缩输出缓冲区不足。
这个函数实际上是使用 DEFLATE 算法进行压缩,DEFLATE 是一种通用的压缩算法,也是 zlib 库的核心算法之一。压缩后的数据可以使用` uncompress 函数进行解压缩。
总体而言,compress函数提供了一种简单的方式,可以在应用程序中对数据进行压缩,适用于需要减小数据体积的场景,比如网络传输或数据存储。
// 单个文件限制大小为 100M
#define MAX_SRC_FILE_SIZE (100*1024*1024)
/**
* @brief 压缩指定文件的数据
*
* @param pszCompressFileName 待压缩文件的路径
* @param ppCompressData 保存压缩后数据的指针
* @param pdwCompressDataSize 传入时为压缩缓冲区的大小,传出时为实际压缩后数据的大小
* @return 压缩是否成功,成功返回 TRUE,否则返回 FALSE
*/
BOOL CompressData(wchar_t*pszCompressFileName, BYTE **ppCompressData, DWORD *pdwCompressDataSize)
{
HANDLE hFile = CreateFile(pszCompressFileName, GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_ARCHIVE, NULL);
// 检查文件句柄是否有效
if (INVALID_HANDLE_VALUE == hFile)
{
return FALSE;
}
// 获取文件大小
DWORD dwFileSize = GetFileSize(hFile, NULL);
// 检查文件大小是否超过限制
if (MAX_SRC_FILE_SIZE < dwFileSize)
{
CloseHandle(hFile);
return FALSE;
}
DWORD dwDestDataSize = dwFileSize;
// 分配源数据和目标数据的内存
BYTE *pSrcData = new BYTE[dwFileSize];
if (NULL == pSrcData)
{
CloseHandle(hFile);
return FALSE;
}
BYTE *pDestData = new BYTE[dwDestDataSize];
if (NULL == pDestData)
{
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
DWORD dwRet = 0;
// 读取源数据
ReadFile(hFile, pSrcData, dwFileSize, &dwRet, NULL);
// 检查读取是否成功
if ((0 >= dwRet) || (dwRet != dwFileSize))
{
delete[] pDestData;
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
int iRet = 0;
// 压缩数据
do
{
iRet = compress(pDestData, &dwDestDataSize, pSrcData, dwFileSize);
// 压缩成功,退出循环
if (0 == iRet)
{
break;
}
// 输出缓冲区不足,增加缓冲区大小并重试
else if (-5 == iRet)
{
delete[] pDestData;
pDestData = NULL;
dwDestDataSize = dwDestDataSize + (100 * 1024);
pDestData = new BYTE[dwDestDataSize];
// 分配新的目标数据内存
if (NULL == pDestData)
{
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
}
// 压缩失败,释放内存并返回失败
else
{
delete[] pDestData;
pDestData = NULL;
delete[] pSrcData;
pSrcData = NULL;
CloseHandle(hFile);
return FALSE;
}
} while (TRUE);
// 保存压缩后数据的指针和实际大小
*ppCompressData = pDestData;
*pdwCompressDataSize = dwDestDataSize;
// 释放源数据内存
delete[] pSrcData;
// 关闭文件句柄
CloseHandle(hFile);
// 返回压缩成功
return TRUE;
}
3、文件解压缩
uncompress 函数是 zlib 库提供的用于数据解压缩的函数,通过该函数可以将压缩后的数据解压缩还原。下面是一个示例,演示了如何使用 zlib 库进行文件解压缩。
它的原型如下:
int uncompress(Bytef* dest, uLongf* destLen, const Bytef* source, uLong sourceLen);
- dest:指向存放解压缩后数据的缓冲区的指针。
- destLen:传入时为解压缩缓冲区的大小,传出时为实际解压缩后数据的大小。
- source:指向待解压缩数据的缓冲区的指针。
- sourceLen:待解压缩数据的大小。
uncompress 函数的作用是将 source 指向的数据进行解压缩,并将结果存放在 dest 指向的缓冲区中。destLen 传入时应该是 dest 缓冲区的大小,函数执行后,destLen 会更新为实际解压缩后数据的大小。
函数返回值为解压缩的执行状态,可能的返回值包括:
- Z_OK:解压缩成功。
- Z_MEM_ERROR:内存分配失败。
- Z_BUF_ERROR:解压缩输出缓冲区不足。
- Z_DATA_ERROR:输入数据错误或损坏。
uncompress 函数实际上是使用DEFLATE算法进行解压缩,与 compress 函数相对应。这两个函数共同构成了 zlib 库中的基本数据压缩和解压缩功能。
在实际应用中,可以使用这两个函数来处理需要压缩和解压缩的数据,例如在网络通信中减小数据传输量或在存储数据时减小占用空间。
/**
* @brief 解压指定文件的数据
*
* @param pszUncompressFileName 待解压文件的路径
* @param ppUncompressData 保存解压后数据的指针
* @param pdwUncompressDataSize 传入时为解压缓冲区的大小,传出时为实际解压后数据的大小
* @return 解压是否成功,成功返回 TRUE,否则返回 FALSE
*/
BOOL UncompressData(wchar_t*pszUncompressFileName, BYTE **ppUncompressData, DWORD *pdwUncompressDataSize)
{
HANDLE hFile = CreateFile(pszUncompressFileName, GENERIC_READ,
FILE_SHARE_READ | FILE_SHARE_WRITE, NULL, OPEN_EXISTING,
FILE_ATTRIBUTE_ARCHIVE, NULL);
// 检查文件句柄是否有效
if (INVALID_HANDLE_VALUE == hFile)
{
return FALSE;
}
// 获取文件大小
DWORD dwFileSize = GetFileSize(hFile, NULL);
// 设置目标数据缓冲区大小
DWORD dwDestDataSize = MAX_SRC_FILE_SIZE;
// 分配源数据和目标数据的内存
BYTE *pSrcData = new BYTE[dwFileSize];
if (NULL == pSrcData)
{
CloseHandle(hFile);
return FALSE;
}
BYTE *pDestData = new BYTE[dwDestDataSize];
if (NULL == pDestData)
{
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
DWORD dwRet = 0;
// 读取源数据
ReadFile(hFile, pSrcData, dwFileSize, &dwRet, NULL);
// 检查读取是否成功
if ((0 >= dwRet) || (dwRet != dwFileSize))
{
delete[] pDestData;
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
int iRet = 0;
// 解压缩数据
do
{
iRet = uncompress(pDestData, &dwDestDataSize, pSrcData, dwFileSize);
// 解压缩成功,退出循环
if (0 == iRet)
{
break;
}
// 输出缓冲区不足,增加缓冲区大小并重试
else if (-5 == iRet)
{
delete[] pDestData;
pDestData = NULL;
dwDestDataSize = dwDestDataSize + (100 * 1024);
pDestData = new BYTE[dwDestDataSize];
// 分配新的目标数据内存
if (NULL == pDestData)
{
delete[] pSrcData;
CloseHandle(hFile);
return FALSE;
}
}
// 解压缩失败,释放内存并返回失败
else
{
delete[] pDestData;
pDestData = NULL;
delete[] pSrcData;
pSrcData = NULL;
CloseHandle(hFile);
return FALSE;
}
} while (TRUE);
// 保存解压后数据的指针和实际大小
*ppUncompressData = pDestData;
*pdwUncompressDataSize = dwDestDataSize;
// 释放源数据内存
delete[] pSrcData;
// 关闭文件句柄
CloseHandle(hFile);
// 返回解压成功
return TRUE;
}
4、演示示例
下面是一个包含文件压缩和解压缩的完整示例,展示了如何将文件进行压缩保存,然后解压还原。
调用CompressData压缩文件,返回结果pCompressData存放文件内存字节,结果dwCompressDataSize存放长度,并调用SaveToFile保存到本地。
int main(int argc, char* argv[])
{
BOOL bRet = FALSE;
BYTE *pCompressData = NULL;
DWORD dwCompressDataSize = 0;
// 压缩文件
bRet = CompressData(L"F:\\vs2013_code\\ConsoleApplication2\\Debug\\1.txt", &pCompressData, &dwCompressDataSize);
if (TRUE == bRet)
{
std::cout << "已压缩" << std::endl;
}
// 保存压缩数据为文件
bRet = SaveToFile(L"F:\\vs2013_code\\ConsoleApplication2\\Debug\\1.zlib", pCompressData, dwCompressDataSize);
if (TRUE == bRet)
{
std::cout << "已保存到文件" << std::endl;
}
// 释放内存
delete[]pCompressData;
pCompressData = NULL;
system("pause");
return 0;
}
调用UncompressData解压缩文件,返回结果pUncompressData存放文件内存字节,结果dwUncompressDataSize存放长度,并调用SaveToFile保存到本地。
int main(int argc, char* argv[])
{
BOOL bRet = FALSE;
BYTE *pUncompressData = NULL;
DWORD dwUncompressDataSize = 0;
// 解压文件
bRet = UncompressData("F:\\vs2013_code\\ConsoleApplication2\\Debug\\1.zlib", &pUncompressData, &dwUncompressDataSize);
if (TRUE == bRet)
{
std::cout << "已解压" << std::endl;
}
// 保存解压数据为文件
bRet = SaveToFile("F:\\vs2013_code\\ConsoleApplication2\\Debug\\1.txt", pUncompressData, dwUncompressDataSize);
if (TRUE == bRet)
{
std::cout << "已保存到文件" << std::endl;
}
// 释放内存
delete[]pUncompressData;
pUncompressData = NULL;
system("pause");
return 0;
}
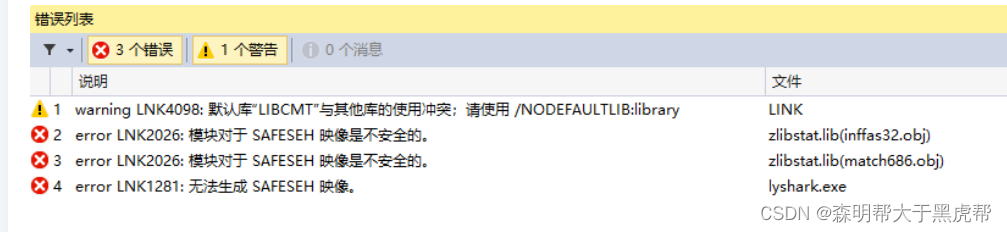
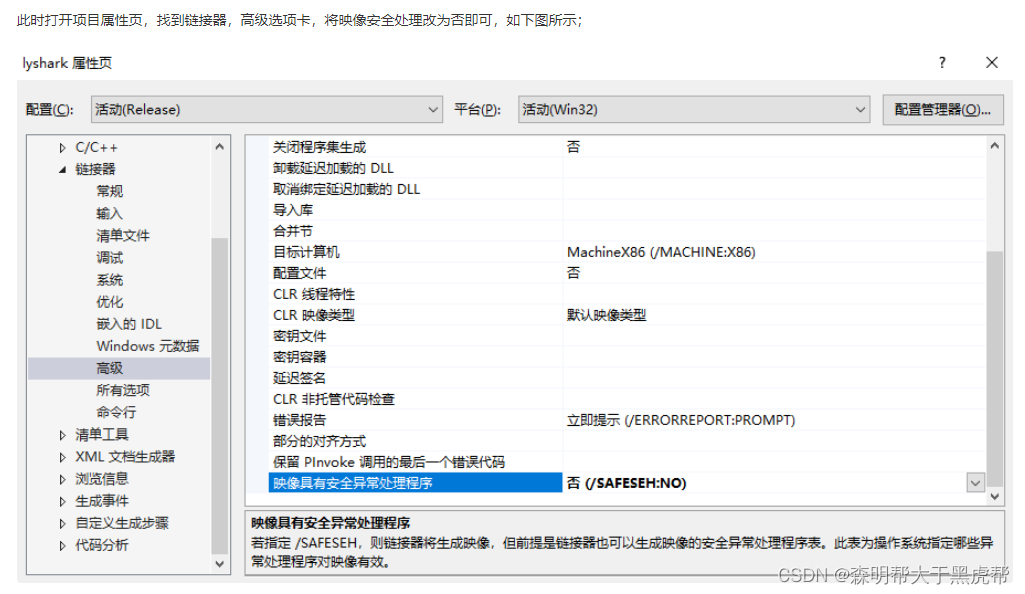
编译时可能会提示无法生成SAFESEH影响的报错信息,如下图所示;
5、结论
通过使用 zlib 库,我们可以方便地在应用程序中实现数据的压缩和解压缩功能。这对于需要减小数据传输量或在存储数据时减小占用空间的场景非常有用。在实际应用中,可以根据需要调整缓冲区大小和处理流程,以适应不同的数据处理需求。
















 101
101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











