






经典卷积神经网络
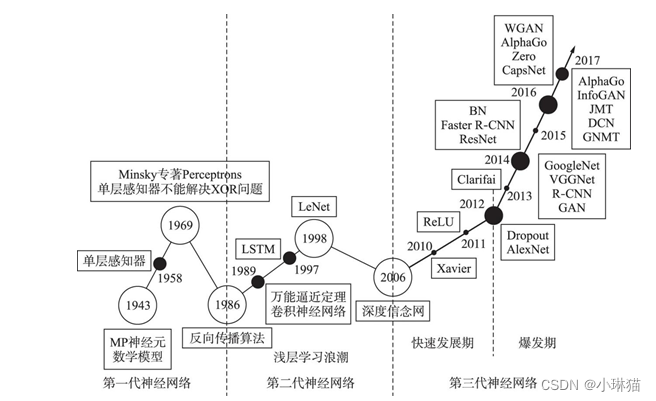
1.摘要
本篇博客主要对北京大学王汉生老师主编的《深度学习从入门到精通·微课版》一书中讲解的经典卷积神经网络模型进行总结,以便加深理解和记忆。
2.书本导读
《深度学习从入门到精通·微课版》是王老师针对于具有文科背景的商业统计学专业的硕士生编写的深度学习入门教材,从统计学专业熟悉的回归分析入手,全面介绍了深度学习的历史和现代实践,内容通俗易懂,易于上手,又配有基于Tensorflow的keras示例,是深度学习快速入门的绝佳课本。
我读此书的前置条件是读完了《Deep Learning》前十二章的内容,对深度学习的基础知识有了较为全面而基础的认识。但由于《Deep Learning》一书更多是对理论和思想原理的讨论,没有实例代码,也未对经典的网络模型进行介绍,因而选择此书进行补充和复习,前后用了5天左右的时间读完。
本篇博客仅对书中第3-6章的部分内容进行总结,对于深度学习的基础知识进行省略。
3.资源
keras==2.6.0
Keras_Preprocessing==1.1.2
matplotlib==3.6.2
numpy==1.19.2
pandas==1.3.0
Pillow==9.3.0
scikit_learn==1.1.3
tensorflow==2.11.0
tensorflow_gpu==2.6.0
4.线性回归
由于此书的受众背景是具有商业统计学的学生,对回归分析非常熟悉,因而主编从线性回归模型入手,解释了深度学习实际上是一种处理非结构化数据的高度复杂的非线性回归模型,与回归模型没有本质区别,但是在优化等方面非常不平凡。
1)线性回归模型
通过将3通道图像的3维张量拉伸为1维的向量,进行简单的线性回归,其拉伸后的每一个像素点都看成一个输入 x i x_i xi;Y是一个标识对该美食图像的喜爱程度,是一个单值的标量。
线性回归模型: Y = ∑ i w i d t h ∑ j h e i g h t ∑ k 3 X i j k A i j k + b + λ Y=\sum_i^{width} \sum_j^{height} \sum_k^3 X_{ijk}A_{ijk} + b + λ Y=∑iwidth∑jheight∑k3XijkAijk+b+λ
其中, X i j k X_{ijk} Xijk表示第k个通道第i行第j列的像素值, A i j k A_{ijk} Aijk是其方向对应的斜率,b为单值型的截距,λ是引入的随机噪声
2)案例:美食评分
从Flickr上收集用户上传的各种食物图像,经过人工筛选,筛选出196张图像用于案例分析。组织了5个人构成的研究小组,对每张图片进行打分,分数范围为1-5,最后每张图片取平均值,得到了每个食物的评分
评分表:FoodScore.csv,数据为图像的id映射到其评分
图像保存在data_foodscore文件夹
3)实现
"""
:description:This script uses linear regression model to fit flatten image to line
;debug-time:2022.11.24
"""
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
from keras.optimizers import adam_v2
from keras import Input, Model
from keras.layers import Flatten, Dense
from sklearn.model_selection import train_test_split
# 1.读入标注者对不同食物图像的评分,即Y数据
MasterFile = pd.read_csv('FoodScore.csv')
# 绘制直方图,可以看出评分大体服从正态分布
MasterFile.hist()
plt.show()
# 2.分离因变量Y
FileNames = MasterFile['ID']
N = len(FileNames)
Y = np.array(MasterFile['score']).reshape([N, 1])
# 3.处理图像数据
IMSIZE = 128
X = np.zeros([N, IMSIZE, IMSIZE, 3])
for i in range(N):
MyFile = FileNames[i]
im = Image.open(f'data_foodscore/{MyFile}.jpg')
im = im.resize([IMSIZE, IMSIZE])
im = np.array(im) / 255
X[i,] = im
# 处理后的数据展示:略
# 4.切分训练集与测试集
X0, X1, Y0, Y1 = train_test_split(X, Y, test_size=0.5, random_state=0) # random_state固定随机种子,以保证结果可重复
# 5.线性回归模型构建
# 输入层:
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
# 展平3维的x
x = Flatten()(x)
# Dense:全连接层
x = Dense(1)(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 6.模型编译
"""
issue1:change lr to learning_rate
issue2:https://zhuanlan.zhihu.com/p/471627821
issue3:
"""
model.compile(loss='mse', optimizer=adam_v2.Adam(learning_rate=0.001), metrics=['mse'])
# 7.模型拟合
model.fit(x=X0, y=Y0, validation_data=(X1, Y1), batch_size=100, epochs=100)
# 8.模型预测
MyPic = Image.open('MyPic.jpg')
MyPic = MyPic.resize((IMSIZE, IMSIZE))
MyPic = np.array(MyPic) / 255
MyPic = MyPic.reshape((1, IMSIZE, IMSIZE, 3))
result = model.predict(MyPic)
print(result)
5. 逻辑斯蒂回归
1)二分类
逻辑斯蒂回归Logistic Regression是一种广义的线性回归模型,用于处理二分类问题,其映射函数为:
P
(
Y
i
=
1
∣
X
i
,
β
)
=
e
X
i
T
β
1
+
e
X
i
T
β
P
(
Y
i
=
0
∣
X
i
,
β
)
=
1
−
P
(
Y
i
=
1
∣
X
i
,
β
)
=
1
−
e
X
i
T
β
1
=
e
X
i
T
β
1
+
e
X
i
T
β
P(Y_i=1|X_i,β) = \frac {e^{X_i^Tβ}} {1+e^{X_i^Tβ}} \\ P(Y_i=0|X_i,β) = 1- P(Y_i=1|X_i,β) = 1- \frac {e^{X_i^Tβ}} {1} = \frac {e^{X_i^Tβ}} {1+e^{X_i^Tβ}}
P(Yi=1∣Xi,β)=1+eXiTβeXiTβP(Yi=0∣Xi,β)=1−P(Yi=1∣Xi,β)=1−1eXiTβ=1+eXiTβeXiTβ
其中,
X
i
X_i
Xi是第i个样本,
Y
i
Y_i
Yi是其对应的标签值,β是回归系数
2)当二分类问题扩展为多分类问题时,逻辑回归就变成了Softmax回归,Softmax回归可以求出输入数据对应于每个分类的概率值,且概率值和为1,最后将输出概率值最大的分类作为预测分类,其映射函数为:
P
(
Y
i
=
j
∣
X
i
,
β
)
=
e
X
i
T
β
j
∑
k
=
1
k
e
X
i
T
β
K
P(Y_i=j|X_i,β) = \frac {e^{X_i^Tβ_j}} {\sum^k_{k=1} e^{X_i^Tβ_K}}
P(Yi=j∣Xi,β)=∑k=1keXiTβKeXiTβj
3)案例:手写数字识别
数据集:MNIST数据集,来源于美国国家标准与技术研究所,由250个不同的人手写的数字构成,其中50%是高中生,50%来自人口普查局的工作人员。测试集也是同样比例的手写数字数据。该案例的目的是区分0-9这10个数字
数据描述:将单通道的28×28的图像平铺,则输入层为28×28个输入单元,再通过10个输出单元的输出层进行全连接,最后用以softmax获取各个分类的概率值。
4)实现
"""
:description:This script used logistic regression to solve logistic_regression
:debug-time:2022.11.28
"""
import keras.datasets.mnist as mnist
from keras.optimizers import adam_v2
import numpy as np
import matplotlib.pyplot as plt
from keras import Input, Model
from keras.layers import Dense, Activation
from tensorflow.keras.utils import to_categorical
if __name__ == '__main__':
# 1.导入MNIST数据:MNIST数据集被内置在Tensorflow的example中
# issue:https://blog.csdn.net/qq_43060552/article/details/103189040
# 输入参数整形
(X0, Y0), (X1, Y1) = mnist.load_data()
XX0 = []
XX1 = []
for i in range(len(X0)):
XX0.append(X0[i].flatten())
XX0 = np.asarray(XX0)
for i in range(len(X1)):
XX1.append(X1[i].flatten())
XX1 = np.asarray(XX1)
# 2.产生one-hot型因变量
# issue:https://blog.csdn.net/weixin_39754630/article/details/118097037
YY0 = to_categorical(Y0)
YY1 = to_categorical(Y1)
# 3.构建逻辑斯蒂回归模型
input_shape = (X0.shape[1] * X0.shape[2],)
input_layer = Input(input_shape)
# 输入层
x = input_layer
# 全连接层
x = Dense(10)(x)
# softmax激活函数
x = Activation('softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 使用似然函数做损失函数
model.compile(optimizer=adam_v2.Adam(0.01), loss='categorical_crossentropy', metrics=['accuracy'])
history = model.fit(XX0, YY0, validation_data=(XX1, YY1), batch_size=1000, epochs=50)
# 性能监控:https://cloud.tencent.com/developer/article/1034630
plt.plot(history.history['accuracy'])
plt.show()
# 查看模型各层
print(model.layers)
# 获得Dense层的多数估计结果
print(model.layers[1].get_weights())
# 查看参数矩阵维度
print(model.layers[1].get_weights()[0].shape)
# 参数可视化
fix, ax = plt.subplots(2, 5)
ax = ax.flatten()
weights = model.layers[1].get_weights()[0]
for i in range(10):
Im = weights[:, i].reshape((X0.shape[1], X0.shape[2]))
ax[i].imshow(Im, cmap='seismic')
ax[i].set_title("{}".format(i))
ax[i].set_xticks([])
ax[i].set_yticks([])
plt.show()
上述两种模型对于输入数据是图像的像素矩阵的情况,都采用将3维张量拉伸成1维向量,通过单层全连接进行线性回归,区别在于前者直接输出连续型的预测评分,后者通过了softmax激活函数得到了样本属于每个分类的概率值,属于分类问题。
实际上,对于输入数据是图像的像素矩阵的情况,简单地拉伸处理会破坏图像的结构,图像各像素点之间的局部和全局关系消失,每一向量的语义不明确,给模型的解读带来极大的挑战。因而需要其他方式的计算能够保留图像的结构。这计算方式则是卷积运算,后面的模型正式进入到CNN的范畴。
6.LeNet5
1)背景
LeNet5是由享誉神经网络之父的杨立坤于1988年提出的一种经典的卷积网络结构,是第一个成功应用于数字识别问题的卷积神经网络。在MNIST数据集上,有高达99.2%的正确率,极大地推动了CNN的发展,被认为是CNN的开山之作。
2)网络结构
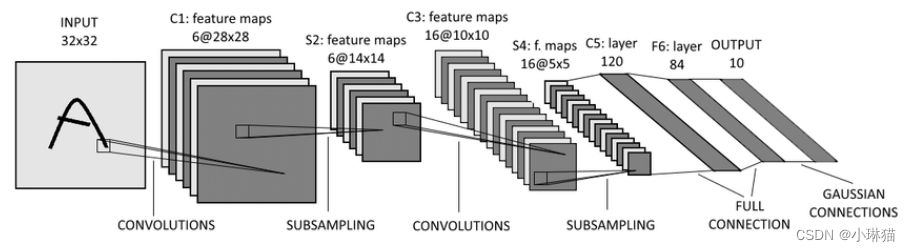
①卷积输入层:32×32的灰度图像
②卷积层1:6个5×5×1的卷积核进行valid卷积,卷积后的结果:宽28(32-5+1)、高(32-5+1)、深度6
③池化层1:6个2×2的矩阵进行valid最大池化,池化后的结果:14×14×6
④卷积层2:16个5×5×6的卷积核进行valid卷积,卷积后的结果:10×10×16
⑤池化层2:16个2×2的矩阵进行valid最大池化,池化后的结果:5×5×16
⑥全连接输入层:将卷积池化输出的张量拉伸为1维向量,作为全连接层的输入,5×5×16=400
⑥全连接隐藏层1:120个隐藏单元
⑦全连接隐藏层2:84个单元
⑧输出层:10个输出单元
3)代码实现:手写数字识别
"""
:description:This script is used to study LeNet-5
"""
from keras import Input, Model
from keras.datasets import mnist
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
from keras.utils import np_utils
from matplotlib import pyplot as plt
if __name__ == '__main__':
# 1.导入数据
(X0, Y0), (X1, Y1) = mnist.load_data()
# 2.数据预处理
# 将输入数据增加一个维度:28 * 28变为28 * 28 * 1
X0 = X0.reshape(X0.shape[0], 28, 28, 1) / 255
X1 = X1.reshape(X1.shape[0], 28, 28, 1) / 255
# 将输出数据变为one-hot形式
Y0 = np_utils.to_categorical(Y0)
Y1 = np_utils.to_categorical(Y1)
# 3.构建LeNet-5网络
# 输入层:28*28*1
input_layer = Input([28, 28, 1])
x = input_layer
# 卷积层1:5*5*6
x = Conv2D(6, [5, 5], padding="same", activation='relu')(x)
# 最大池化层1:池化矩阵规模:2*2,步长:2、2
x = MaxPooling2D(pool_size=[2, 2], strides=[2, 2])(x)
# 卷积层2:5*5*16
x = Conv2D(15, [5, 5], padding='valid', activation='relu')(x)
# 最大池化层2:池化矩阵规模:2*2,步长:2、2
x = MaxPooling2D(pool_size=[2, 2], strides=[2, 2])(x)
# 展平输出作为全连接输入
x = Flatten()(x)
# 隐藏层1:120
x = Dense(120, activation='relu')(x)
# 隐藏层2:84
x = Dense(84, activation='relu')(x)
# 输出层:10
x = Dense(10, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 4.模型编译与训练
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
# issue:此处注意书中的一处错误,validation_data的()写成了[]
history = model.fit(X0, Y0, epochs=10, batch_size=200, validation_data=(X1, Y1))
plt.plot(history.history['accuracy'])
plt.show()
7.AlexNet
1)背景
AlexNet是2012年ImageNet竞赛(处理1000分类)冠军Hinton和他的学生Alex Krizhevsky设计的,该模型Top5预测的错误率为18.9%,是ImageNet竞赛中第一个使用卷积神经网络的参赛者
2)网络结构

①卷积输入层:227×227×3 彩色图像矩阵
②卷积层1:96个11×11(×3)的卷积核,步长为4×4,valid卷积,卷积结果为:55((227 - 11) /4 + 1) × 55 × 96
③池化层1:最大池化,3×3,步长为2×2,池化结果为:27((55 -3)/2 + 1) × 27 ×96
④卷积层2:256个5×5(×96)的卷积核,步长为2,same卷积,卷积结果为:27 × 27 × 256
⑤池化层2:最大池化,3×3,步长为2×2,池化结果为:13((27 - 3)/2 +1) × 13 × 256
⑥卷积层3:384个3×3(×256)的卷积核,same卷积,卷积结果为:13 × 13 × 384
⑦卷积层4:384个3×3(×384)的卷积核,same卷积,卷积结果为:13 × 13 × 384
⑧卷积层5:256个3×3(×384)的卷积核,same卷积,卷积结果为:13 × 13 × 256
⑨池化层3:最大池化,3×3,步长为2×2,池化结果为:6((13 -3)/2 +1) × 6 × 256
⑩全连接层
全连接输入层:将上述结果铺平作为全连接层的输入,6 × 6 × 256 = 9,216
全连接隐藏层1:4096个隐藏单元
Dropout(0.5)
全连接隐藏层2:4096个隐藏单元
Dropout(0.5)
输出层:1000个输出单元
3)创新点
①成功使用了ReLU作激活函数,验证其在较深网络中超过Sigmoid函数
②在全连接层应用Dropout随机忽略一部分神经元,避免过拟合
③使用重叠的最大池化(步长小于卷积核)
④提出局部响应归一化层Local Response Normalization LRN,对当前输出作平滑处理,后逐渐被BN代替
⑤使用CUDA作GPU加速
⑥采用数据集增强技术,随机从256×256的图像中截取224×224大小的区域(以及水平翻转)增加样本数量
4)代码实现:中文字体识别——楷书和行书
数据集目录:ChineseStyle
"""
:description:This script is used to learn AlexNet
"""
from keras import Input, Model
from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout
from keras.preprocessing.image import ImageDataGenerator
from matplotlib import pyplot as plt
from keras.optimizers import adam_v2
if __name__ == '__main__':
# 1.数据导入
"""
传统数据导入的方式是一次性将数据导入到内存进行运算,但如果数据集过大,可能导致导入时时间过程或内存不够,
这时则可以分批将数据集导入进行运算,数据生成器提供了良好的接口,同时也需要保证数据在的保存目录满足一定要求。
"""
IMSIZE = 227
# 训练数据生成器
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory('ChineseStyle/train',
target_size=(IMSIZE, IMSIZE),
batch_size=200,
class_mode='categorical')
# 验证数据生成器
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory('ChineseStyle/test',
target_size=(IMSIZE, IMSIZE),
batch_size=200,
class_mode='categorical')
# 输出图像
fig, ax = plt.subplots(2, 5)
fig.set_figheight(7)
fig.set_figwidth(15)
ax = ax.flatten()
# 每执行一次next输出一个图像
X, Y = next(train_generator)
for i in range(10):
ax[i].imshow(X[i, :, :])
plt.show()
# 2.AlexNet模型搭建
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
x = Conv2D(96, [11, 11], strides=[4, 4], activation='relu')(x)
x = MaxPooling2D([3, 3], strides=[2, 2])(x)
x = Conv2D(256, [5, 5], padding="same", activation='relu')(x)
x = MaxPooling2D([3, 3], strides=[2, 2])(x)
x = Conv2D(384, [3, 3], padding="same", activation='relu')(x)
x = Conv2D(384, [3, 3], padding="same", activation='relu')(x)
x = Conv2D(256, [3, 3], padding="same", activation='relu')(x)
x = MaxPooling2D([3, 3], strides=[2, 2])(x)
x = Flatten()(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(4096, activation='relu')(x)
x = Dropout(0.5)(x)
x = Dense(2, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 3.模型编译并训练
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, epochs=20, validation_data=validation_generator)
plt.plot(history.history['accuracy'])
plt.show()
8.VGG
1)背景
VGG是牛津大学视觉组和DeepMind共同研发的一种CNN模型,在2014年ILSVRC比赛上获得了分类项目的第2名和定位项目的第1名。
2)网络结构
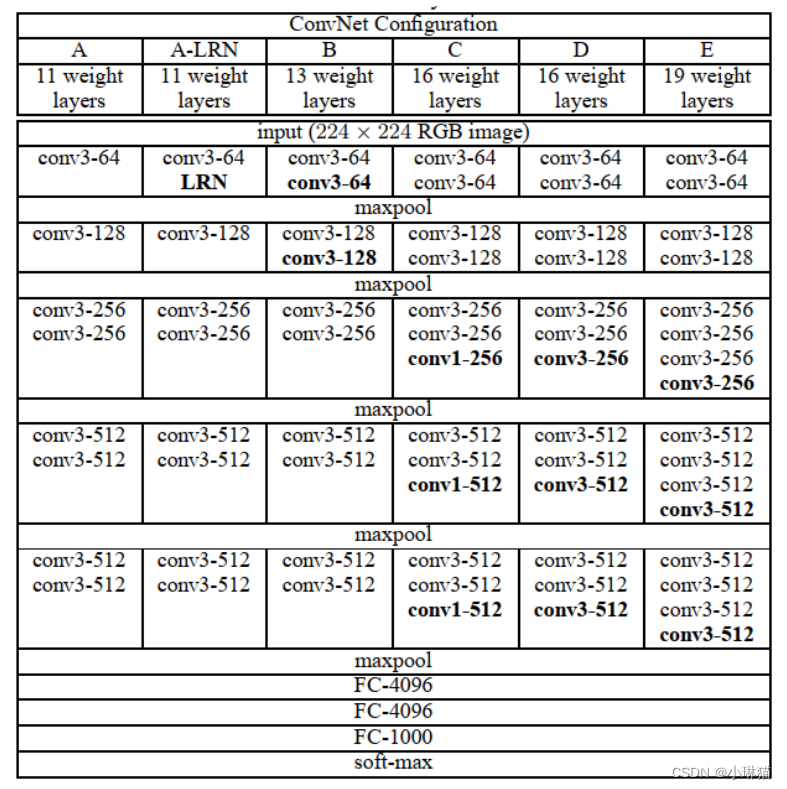
VGG使用小卷积核和增加卷积神经网络的深度来提升分类识别效果,共有6种网络结构,其中广为流传的是VGG16和VGG19,两者没有本质区别只是网络深度不同。
无论是哪种VGG,都包含5组卷积操作,每组卷积操作包含一定数量的卷积层,可以看作是5个阶段的特征提取。每组卷积后都进行一个2×2的最大池化。模型最后是3个全连接层,这3个全连接层在这几种VGG网络中是完全相同的。
尽管这6个VGG网络的深度在逐渐加深但参数个数没有明显的增加,原因是最后的全连接层的参数占据了绝大多数的数量。
3)VGG16
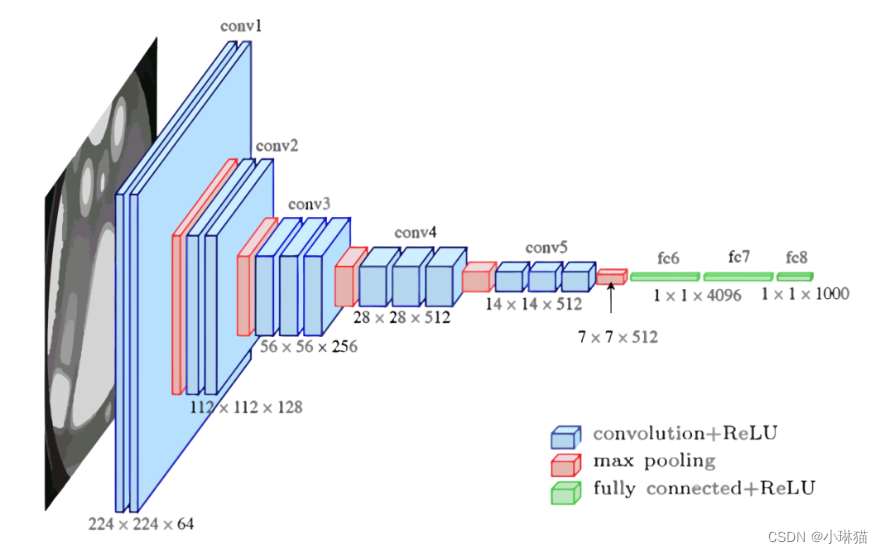
输入层:224 × 224 × 3
①卷积层1(2次):64个3×3的卷积核,步长为1×1,same卷积,卷积结果为:224×224×64
②池化层1:2×2的最大池化,步长为2×2,池化结果为:112((224-2)/2+1)× 112 × 64
③卷积层2(2次):128个3×3的卷积核,步长为1×1,same卷积,卷积结果为:112×112×128
④池化层2:2×2的最大池化,步长为2×2,池化结果为:56((112-2)/2+1)× 56 × 128
⑤卷积层3(3次):256个3×3的卷积核,步长为1×1,same卷积,卷积结果为:56×56×256
⑥池化层3:2×2的最大池化,步长为2×2,池化结果为:28((56-2)/2+1)× 28 × 256
⑦卷积层4(3次):512个3×3的卷积核,步长为1×1,same卷积,卷积结果为:28×28×512
⑧池化层4:2×2的最大池化,步长为2×2,池化结果为:14((28-2)/2+1)× 14 × 256
⑨卷积层5(3次):512个3×3的卷积核,步长为1×1,same卷积,卷积结果为:14×14×512
⑩池化层5:2×2的最大池化,步长为2×2,池化结果为:7((14-2)/2+1)× 7 × 512
输出层:Flatten,Dense(4096),Dense(4096),Dense(1000)
4)代码实现:加利福尼亚理工学院鸟类数据库分类
加利福尼亚理工学院鸟类数据库是2011年的数据,共有11788张图像,总共将鸟分出200个类别
数据集目录:data_vgg
"""
:description:This script is used to learn VGG16
"""
from keras import Input, Model
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, Dense, BatchNormalization
from keras_preprocessing.image import ImageDataGenerator
from keras.optimizers import adam_v2
import matplotlib.pyplot as plt
if __name__ == '__main__':
IMSIZE = 224
# 1.导入数据
# issue:https://blog.csdn.net/qq_42803874/article/details/115028029
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_vgg/train',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_vgg/test',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
fig, ax = plt.subplots(2, 5)
fig.set_figheight(6)
fig.set_figwidth(15)
ax = ax.flatten()
X, Y = next(train_generator)
for i in range(10):
ax[i].imshow(X[i, :, :])
plt.show()
# 2.构建模型
input_shape = (IMSIZE, IMSIZE, 3)
input_layer = Input(input_shape)
x = input_layer
# BN:batch normalization 将每层网络的任意神经元的输入值的分布变为标准正态分布,以尽可能在训练中使网络的每一层输入都保持相同分布
x = BatchNormalization(axis=3)(x)
x = Conv2D(64, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(64, [3, 3], padding='same', activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = BatchNormalization(axis=3)(x)
x = Conv2D(128, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(128, [3, 3], padding='same', activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = BatchNormalization(axis=3)(x)
x = Conv2D(256, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(256, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(256, [3, 3], padding='same', activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = BatchNormalization(axis=3)(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = BatchNormalization(axis=3)(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = Conv2D(512, [3, 3], padding='same', activation='relu')(x)
x = MaxPooling2D((2, 2))(x)
x = GlobalAveragePooling2D()(x)
x = Dense(200)(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 3.编译运行
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, validation_data=validation_generator, epochs=20)
plt.plot(history.history['accuracy'])
plt.show()
9.Inception
1)背景
Inception由Google提出,因而也被称为GoogLeNet,共有4个版本从V1到V4.
2)Inception V1基础模块

相比于AlexNet、VGG等通过增加模型深度来获得更好训练效果的网络结构,Inception则通过增加网络的宽度来提高训练效果。在Inception V1的基础上,Google又不断改善网络结构,来提高训练性能。
Inception V1的贡献主要有两个:
①在多个不同尺寸的卷积核上同时进行卷积再聚合,直观通俗地解释是,叠加不同尺寸的卷积核可以从细节上提取更丰富的特征。
②使用1×1的卷积来降维(减少模型参数)
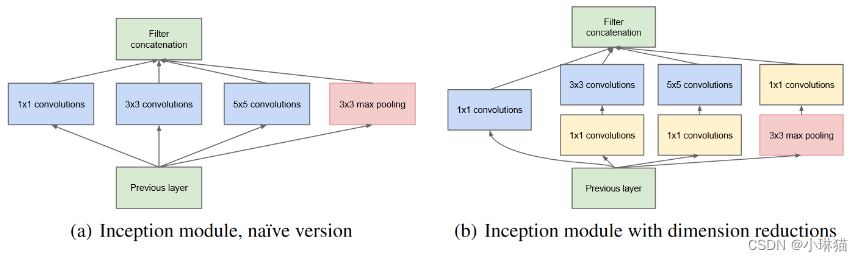
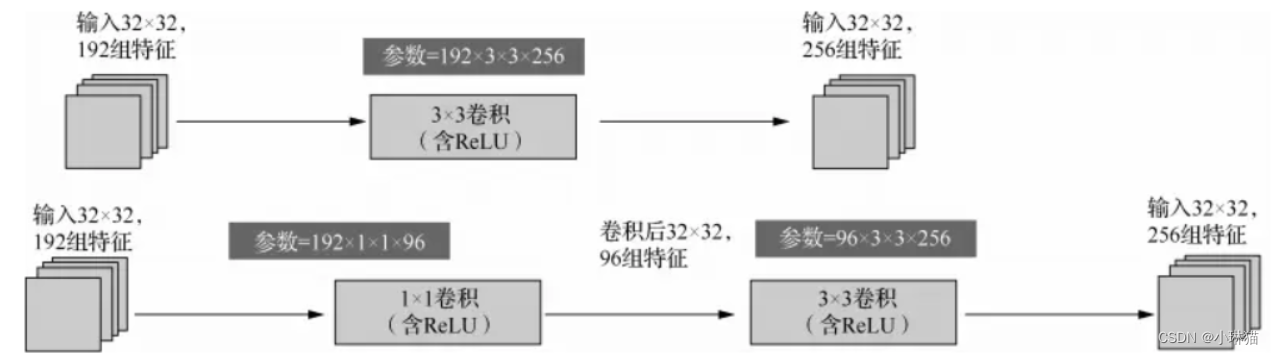
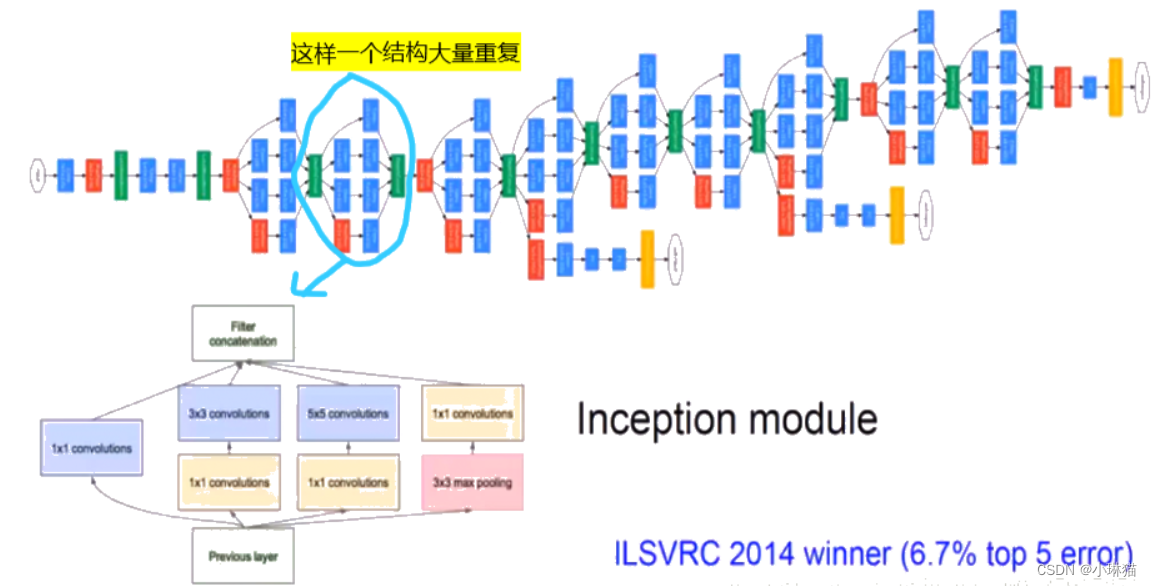
3)Inception V1的网络结构
网络结构比较庞大,共有22层
输入层是224×224×3的图像矩阵,随后经过两个普通的卷积池化层,重复Inception V1的基础模块,最后再经过全局平均池化核全连接层得到输出
4)代码实现:花的分类
数据集目录:data_flower
"""
:description:This script is used to learn inception v1
"""
from keras import Input, Model
from keras.layers import Conv2D, BatchNormalization, MaxPooling2D, concatenate, Dropout, Flatten, Dense
from keras.optimizers import adam_v2
from keras_preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
if __name__ == '__main__':
IMSIZE = 224
# 1.导入数据
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_flower/train/',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_flower/test/',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
# 2.搭建模型
# 2.1输入层
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
# 2.2卷积池化层1
x = Conv2D(64, (7, 7), strides=(1, 1), padding='same', activation='relu')(x)
x = BatchNormalization(axis=3)(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# 2.2卷积池化层2
x = Conv2D(192, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
x = BatchNormalization(axis=3)(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# 2.3 9组Inception v1 基础模块
for i in range(9):
# 分之1×1
brach1x1 = Conv2D(64, (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
brach1x1 = BatchNormalization(axis=3)(brach1x1)
# 分支3×3
brach3x3 = Conv2D(96, (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
brach3x3 = BatchNormalization(axis=3)(brach3x3)
brach3x3 = Conv2D(128, (3, 3), strides=(1, 1), padding='same', activation='relu')(x)
brach3x3 = BatchNormalization(axis=3)(brach3x3)
# 分支5×5
brach5x5 = Conv2D(16, (1, 1), strides=(1, 1), padding='same', activation='relu')(x)
brach5x5 = BatchNormalization(axis=3)(brach5x5)
brach5x5 = Conv2D(32, (5, 5), strides=(1, 1), padding='same', activation='relu')(x)
brach5x5 = BatchNormalization(axis=3)(brach5x5)
# 整体卷积池化
branch_pool = MaxPooling2D(pool_size=(3, 3), strides=(1, 1), padding='same')(x)
branch_pool = Conv2D(32, (1, 1), strides=(1, 1), padding='same', activation='relu')(branch_pool)
branch_pool = BatchNormalization(axis=3)(branch_pool)
# 分支聚合
x = concatenate([brach1x1, brach3x3, brach5x5, branch_pool], axis=3)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# 2.4全连接层
x = Dropout(0.4)(x)
x = Flatten()(x)
x = Dense(17, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
# 3.模型编译并训练
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, validation_data=validation_generator, epochs=20)
plt.plot(history.history['accuracy'])
plt.show()
5)迁移学习 Inception V3
迁移学习Transfer Learning是指将某个领域或任务上学习到的知识或模式应用到不同但相关的领域问题上,如将ImageNet1000分类训练出的模型应用到简单的猫狗分类,这样就可以快速实现应用,达到较好的模型效果,且省去训练成本。
在模型迁移的过程中注意输入和输出问题,即目标任务的输入应调整与原模型输入一致,目标任务的输出也需要进行调整
示例:猫狗分类
数据集目录:CatDog
"""
:description:This script is used to learn Transfer Learning with Inception v3
"""
from keras import Model
from keras.applications.inception_v3 import preprocess_input, InceptionV3
from keras.layers import GlobalAveragePooling2D, Dense
from keras.optimizers import adam_v2
import matplotlib.pyplot as plt
from keras_preprocessing.image import ImageDataGenerator
if __name__ == '__main__':
IMSIZE = 299
train_generator = ImageDataGenerator(preprocessing_function=preprocess_input,
shear_range=0.5,
rotation_range=30,
zoom_range=0.2,
width_shift_range=0.2,
height_shift_range=0.2).flow_from_directory(
'CatDog/train',
target_size=(IMSIZE, IMSIZE),
batch_size=100,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(preprocessing_function=preprocess_input).flow_from_directory(
'CatDog/validation',
target_size=(IMSIZE, IMSIZE),
batch_size=100,
class_mode='categorical'
)
# 创建InceptionV3的基模型,输入数据的宽度是imagenet示例的宽度,不包含最顶层的分类层
base_model = InceptionV3(weights='imagenet', include_top=False)
# 不仅迁移模型结构,将训练好的模型权重也迁移过来
for layer in base_model.layers:
layer.trainable = False
# 输入层
input_layer = base_model.input
# base输出层
x = base_model.output
# 全局平均池化
x = GlobalAveragePooling2D()(x)
# 全连接
x = Dense(2, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, validation_data=validation_generator, epochs=1)
plt.plot(history.history['accuracy'])
plt.show()
10.ResNet
1)背景
残差神经网络ResNet(Residual Neral Network)是由微软研究院何凯明等人提出的,该算法获得了2015年大规模视觉识别挑战赛等多项竞赛的冠军,是CNN的一个里程碑,影响深远。
2)思想来源
以往的思想是模型的训练效果会随着网络的加深而增强,理论上也正是如此。实践中却会出现深度网络的退化问题,随着网络的加深模型的训练效果不进反退。ResNet就是在此问题下提出的,以解决深度网络难以训练的问题(信息丢失、梯度爆炸/消失、深层难以线性变换)
3)残差学习和残差学习模块
①残差学习
残差学习将输入值绕过卷积层,直接传导到后面的层中,此时F(x)本质上是输出和输入之间的差值,即残差。
残差学习相比与原始特征直接学习更容易,这是因为,从直观上说残差较小需要学习的内容少,从梯度反向传播上说,这种短路机制可以无损地传播梯度。
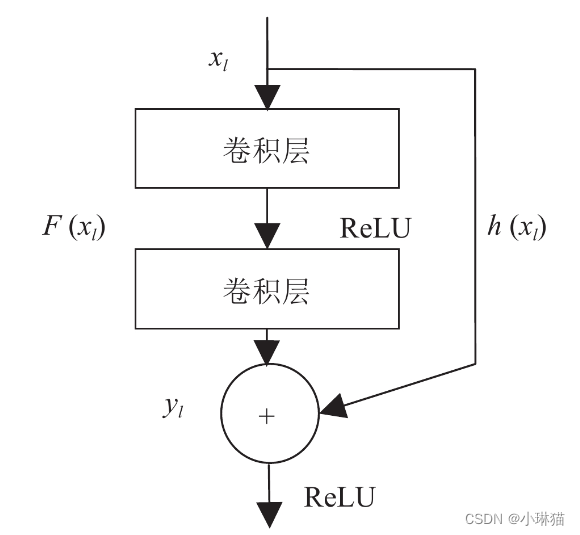
②常见的残差学习结构
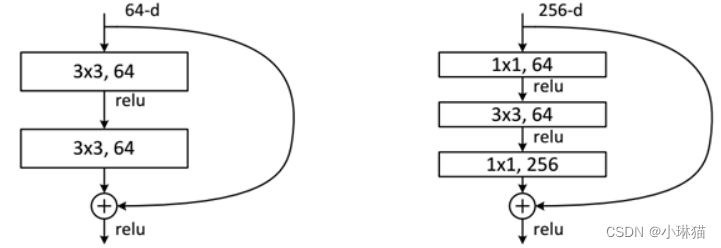
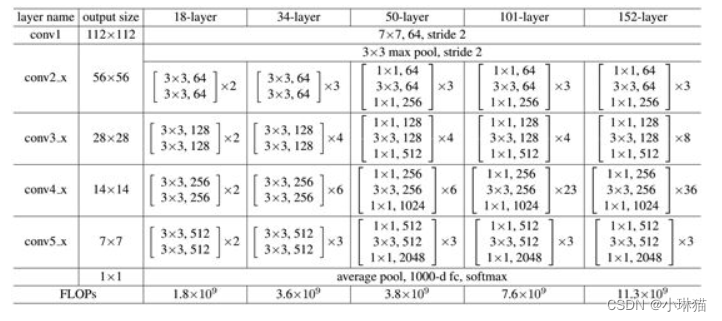
③不同深度ResNet的网络结构
4)代码实现:花的三分类问题
数据集目录:data_res
"""
:description:This script is used to learn ResNet
"""
from keras import Input, Model
from keras.layers import Conv2D, BatchNormalization, MaxPooling2D, add, Activation, Flatten, Dense
from keras_preprocessing.image import ImageDataGenerator
from keras.optimizers import adam_v2
import matplotlib.pyplot as plt
if __name__ == '__main__':
NB_CLASS = 3
IMSIZE = 224
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_res/train',
target_size=(IMSIZE, IMSIZE),
batch_size=1,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_res/test',
target_size=(IMSIZE, IMSIZE),
batch_size=1,
class_mode='categorical'
)
input_layer = Input(shape=(IMSIZE, IMSIZE, NB_CLASS))
x = input_layer
# 普通卷积层
x = Conv2D(64, (7, 7), padding='same', strides=(2, 2), activation='relu')(x)
x = BatchNormalization()(x)
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
# 记录此时的输出用于绕过残差卷积层,直接传递到输出
x0 = x
# 残差卷积层1
for i in range(3):
x = Conv2D(64, (1, 1), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(64, (3, 3), padding='same', strides=(1, 1), activation=None)(x)
x = BatchNormalization()(x)
# 注意残差卷积层最后一个卷积的激活函数为None,最后一层的输入加上之前保持的输入一起输出
x = Conv2D(256, (1, 1), padding='same', strides=(1, 1), activation=None)(x)
x = BatchNormalization()(x)
# 将x0整合为与x相同规模,以进行相加
x0 = Conv2D(256, (1, 1), padding='same', strides=(1, 1), activation='relu')(x0)
x0 = BatchNormalization()(x0)
# 输出与输入叠加,一同传入激活函数输出
x = add([x, x0])
x = Activation('relu')(x)
x0 = x
# 残差卷积层2
for i in range(4):
x = Conv2D(128, (1, 1), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(128, (3, 3), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
# 注意残差卷积层最后一个卷积的激活函数为None,最后一层的输入加上之前保持的输入一起输出
x = Conv2D(512, (1, 1), padding='same', strides=(1, 1), activation=None)(x)
x = BatchNormalization()(x)
# 将x0整合为与x相同规模,以进行相加
x0 = Conv2D(512, (1, 1), padding='same', strides=(1, 1), activation='relu')(x0)
x0 = BatchNormalization()(x0)
# 输出与输入叠加,一同传入激活函数输出
x = add([x, x0])
x = Activation('relu')(x)
x0 = x
# 残差卷积层3
for i in range(6):
x = Conv2D(256, (1, 1), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(256, (3, 3), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
# 注意残差卷积层最后一个卷积的激活函数为None,最后一层的输入加上之前保持的输入一起输出
x = Conv2D(1024, (1, 1), padding='same', strides=(1, 1), activation=None)(x)
x = BatchNormalization()(x)
# 将x0整合为与x相同规模,以进行相加
x0 = Conv2D(1024, (1, 1), padding='same', strides=(1, 1), activation='relu')(x0)
x0 = BatchNormalization()(x0)
# 输出与输入叠加,一同传入激活函数输出
x = add([x, x0])
x = Activation('relu')(x)
x0 = x
# 残差卷积层4
for i in range(3):
x = Conv2D(512, (1, 1), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
x = Conv2D(512, (3, 3), padding='same', strides=(1, 1), activation='relu')(x)
x = BatchNormalization()(x)
# 注意残差卷积层最后一个卷积的激活函数为None,最后一层的输入加上之前保持的输入一起输出
x = Conv2D(2048, (1, 1), padding='same', strides=(1, 1), activation=None)(x)
x = BatchNormalization()(x)
# 将x0整合为与x相同规模,以进行相加
x0 = Conv2D(2048, (1, 1), padding='same', strides=(1, 1), activation='relu')(x0)
x0 = BatchNormalization()(x0)
# 输出与输入叠加,一同传入激活函数输出
x = add([x, x0])
x = Activation('relu')(x)
x0 = x
# 全连接层
x = Flatten()(x)
x = Dense(NB_CLASS, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, validation_data=validation_generator, epochs=20)
plt.plot(history.history['accuracy'])
plt.show()
11.DenseNet
1)背景
DenseNet的论文获得了2017国际视觉与模式识别会议最佳论文,该模型借鉴了ResNet的思想并作出了创新,结构不复杂但非常有效
2)Dense Block组件
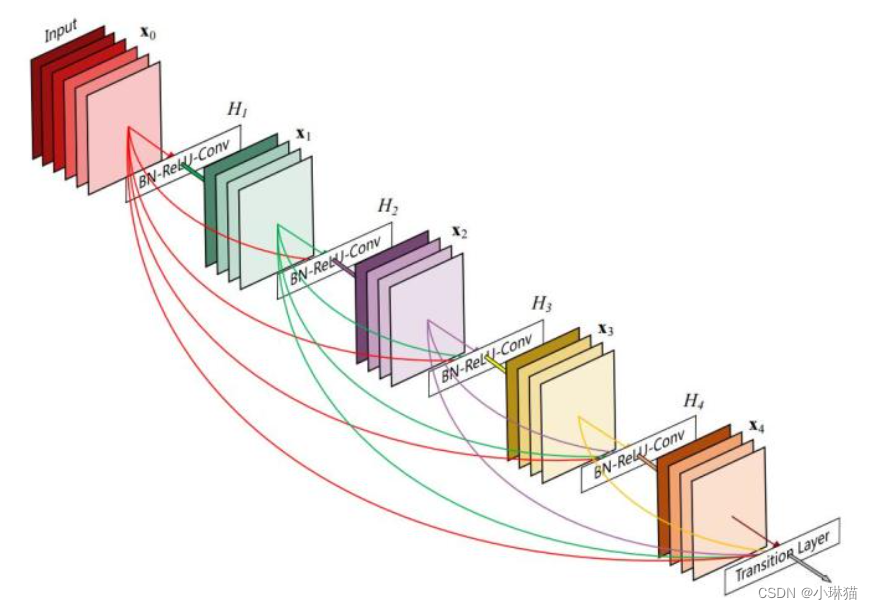
DenseNet在网络中大量重复使用了具有紧密连接性质的Dense Block组件,在一个Dense Block中任何两层都有直接连接,即网络中每一层的输入都是前面所有层输出的并集,而这一层学到的特征也会被传递到后面的所有层作为输入。这种紧密连接仅存在于同一个Dense Block中,不同Dense Blcok之间没有这种紧密连接
3)紧密连接带来的好处
①缓解梯度消失问题
②加强了特征的传播,鼓励特征的重复利用
③极大地减少了参数的个数
④具有正则化效果,即在较少的训练集上,也可以减少过拟合的现象
4)DenseNet的网络结构

在Dense Blcoks前有一个普通的卷积池化层;每个Dense Block中有几个Dense Layer,每个Dense Block后都有一个Ttrainsition Block,它包括一个卷积层和一个池化层;Dense Blcoks后是Classification Block,由一个全局池化层和一个全连接层组成
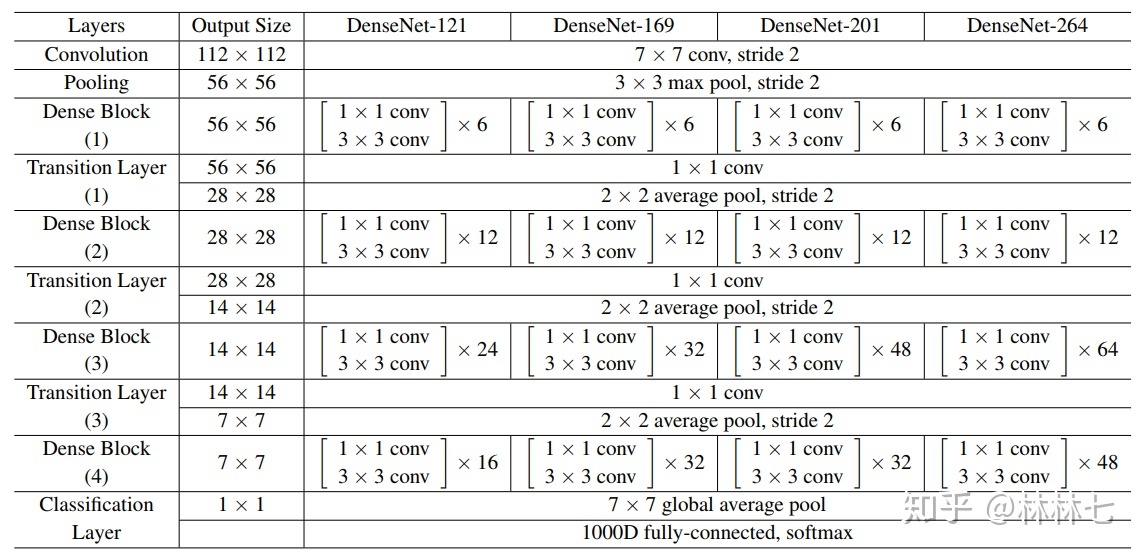
5)代码实现(简单构建):男女性别区分
数据集目录:data_des
"""
:description:This script is used to learn DenseNet with a simple demo
"""
from keras import Input, Model
from keras.layers import BatchNormalization, Conv2D, Concatenate, AveragePooling2D, GlobalAveragePooling2D, Dense
from keras_preprocessing.image import ImageDataGenerator
from keras.optimizers import adam_v2
import matplotlib.pyplot as plt
if __name__ == '__main__':
IMSIZE = 128
train_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_des/train',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
validation_generator = ImageDataGenerator(rescale=1. / 255).flow_from_directory(
'data_des/test',
target_size=(IMSIZE, IMSIZE),
batch_size=20,
class_mode='categorical'
)
# 参数设置
# 每一个Dense Block中的Dense Layer数
nb_layers = 3
# 每一层增长的卷积核数
growth_rate = 32
# 输入层
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
# 普通卷积层
x = BatchNormalization()(x)
x = Conv2D(growth_rate * 2, (3, 3), padding='same', activation='relu')(x)
# Dense Block + Transition Block
for i in range(3):
# Dense Block
feature_list = [x]
for j in range(nb_layers):
x = BatchNormalization()(x)
x = Conv2D(growth_rate, (3, 3), padding='same', activation='relu')(x)
feature_list.append(x)
if j < (nb_layers - 1):
x = Concatenate()(feature_list)
# Transition Block
x = BatchNormalization()(x)
x = Conv2D(growth_rate, (1, 1), padding='same', activation='relu')(x)
x = AveragePooling2D((2, 2), strides=(2, 2))(x)
# 最后一个Dense Block不需要Transition Block
feature_list = [x]
for j in range(nb_layers):
x = BatchNormalization()(x)
x = Conv2D(growth_rate, (3, 3), padding='same', activation='relu')(x)
feature_list.append(x)
if j < (nb_layers - 1):
x = Concatenate()(feature_list)
# 全局池化
x = GlobalAveragePooling2D()(x)
# 全连接
x = Dense(2, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator, validation_data=validation_generator, epochs=20)
plt.plot(history.history['accuracy'])
plt.show()
12.MobileNet
1)背景
MobileNet是2017年提出的一项比较新的研究成果,提出的动机是构建一个高效的网络架构,在实际应用中能够快速完成任务。MobileNet广泛应用于自动驾驶里的物体识别,照相时的人脸识别,物品的精准分类以及地标识别等领域
2)深度可分离卷积
深度可分离卷积Depthwise Separable Convolution将标准的卷积分为两个步骤:
①深度卷积Depthwise Convolution
②逐点卷积Pointwise Convolution(1×1卷积)
通过将标准的卷积分解为这两个步骤,可以大幅度降低参数数量和计算量,如下例:
输入:6×6×3 5个步长为1的卷积核:4×4 输出:3×3×5
标准卷积:3((6-4)/1+1) × 3 × 5 所需参数:3×4×4×5=240
深度可分离卷积:
①深度卷积:6×6×3 3个4×4的卷积核分别卷积3个通道 结果:3((6-4)/1+1)×3×3 所需参数:4×4×3=36
②逐点卷积:3×3×3 5个1×1步长为1的卷积核 结果:3((3-1)/1+1)×3×5 所需参数:1×1×3×5=15
总参数:36 + 15 = 63
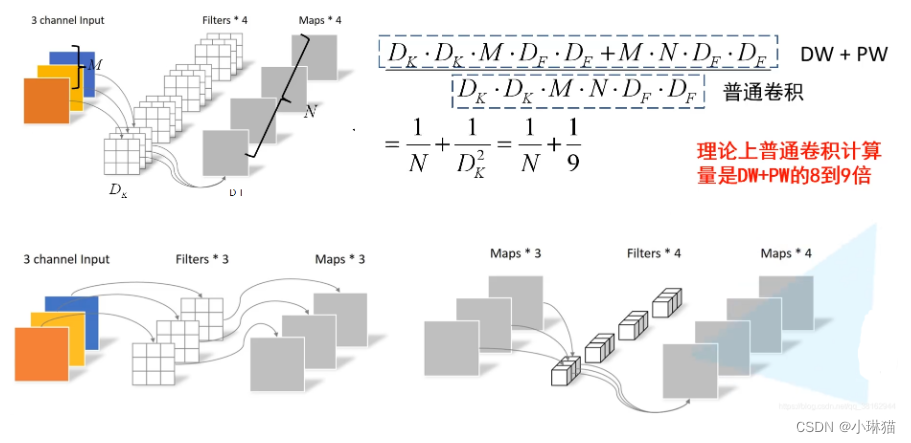
3)两个超参数
①宽度因子α:α∈[0,1],用于控制输入和输出的通道数,即将输入通道M变为αM,将输出通道从N变为αN。由原论文实验得,α越小,相当于保留的通道数越少,准确率随之降低,但参数数量也大大减小。
②分辨率因子ρ:用于控制输入图像的分辨率。由原论文实验得,输入的分辨率越低,预测的精度也越低,但下降的值不大。
4)网络结构
①输入层
②标准卷积层
③多个深度可分离卷积层:dw均可采用3×3步长为1或2的卷积核;所有深度可分离卷积层的输出通道等于输入通道数
④全连接层
5)代码实现(简单构建):Stanford对狗进行10分类
数据集目录:data_mob
"""
:description:This script is used to learn MobileNet
"""
import random
from keras import Input, Model
from keras.layers import ZeroPadding2D, DepthwiseConv2D, BatchNormalization, Conv2D, GlobalAveragePooling2D, Dense, ReLU
from keras_preprocessing.image import ImageDataGenerator
from keras.optimizers import adam_v2
import matplotlib.pyplot as plt
def depth_wise_conv_block(inputs, point_wise_conv_filter, alpha, strides, block_id):
"""
:description:深度可分离卷积函数
;param:inputs:输入图像
:param:point_wise_conv_filter:深度可分离卷积层输出的通道数
:param:alpha:宽度因子,W' = αW
:param:strides:步长,深度卷积步长可以是1或2,逐点卷积步长只能为1
:param:block_id:DepthWise Blcok 's id
"""
# 计算输出通道数
point_wise_conv_filter = int(point_wise_conv_filter * alpha)
# 若步长为1,则输入不变,否则在像素矩阵的右侧和下侧进行0填充
if strides == (1, 1):
x = inputs
else:
x = ZeroPadding2D(((0, 1), (0, 1)), name='conv_pad_%d' % block_id)(inputs)
# 深度卷积,卷积核大小为3×3,若步长为1,则用same卷积,输出尺寸不变;若步长为2,则用valid卷积,112×112会变成56×56
x = DepthwiseConv2D((3, 3),
padding='same' if strides == (1, 1) else 'valid',
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(x)
# BN和Relu
x = BatchNormalization(axis=-1, name='conv_dw_%d_bn' % block_id)(x)
x = ReLU(6., name='conv_dw_%d_relu' % block_id)(x)
# 逐点卷积,卷积核大小为1×1,步长为1,采用same卷积
x = Conv2D(point_wise_conv_filter,
(1, 1),
padding='same',
strides=(1, 1),
use_bias=False,
name='conv_pw_%d' % block_id)(x)
# BN和Relu
x = BatchNormalization(axis=-1, name='conv_pw_%d_bn' % block_id)(x)
x = ReLU(6., name='conv_pw_%d_relu' % block_id)(x)
return x
if __name__ == '__main__':
random.seed(20221201)
IMSIZE = 112
alpha = 1
depth_multiplier = 1
datagen = ImageDataGenerator(rescale=1. / 255,
shear_range=0.5,
rotation_range=30,
zoom_range=2,
width_shift_range=0.2,
height_shift_range=0.2,
horizontal_flip=True,
validation_split=0.4)
train_generator = datagen.flow_from_directory(
'data_mob/',
target_size=(IMSIZE, IMSIZE),
batch_size=150,
class_mode='categorical',
subset='training'
)
validation_generator = datagen.flow_from_directory(
'data_mob/',
target_size=(IMSIZE, IMSIZE),
batch_size=150,
class_mode='categorical',
subset='validation'
)
# 输入层
input_layer = Input([IMSIZE, IMSIZE, 3])
x = input_layer
# 标准卷积层
x = ZeroPadding2D(padding=((0, 1), (0, 1)), name='conv1_pad')(x)
x = Conv2D(32, (3, 3), padding='valid', use_bias=False, strides=(2, 2), name='conv1')(x)
x = BatchNormalization(axis=-1, name='conv1_bn')(x)
x = ReLU(6., name='conv1_relu')(x)
# 部分深度卷积层
x = depth_wise_conv_block(x, 64, alpha, strides=(1, 1), block_id=1)
x = depth_wise_conv_block(x, 128, alpha, strides=(2, 2), block_id=2)
x = depth_wise_conv_block(x, 256, alpha, strides=(2, 2), block_id=3)
x = depth_wise_conv_block(x, 512, alpha, strides=(2, 2), block_id=4)
x = depth_wise_conv_block(x, 1024, alpha, strides=(2, 2), block_id=5)
# 全局平均池化层
x = GlobalAveragePooling2D()(x)
# 全连接层
x = Dense(10, activation='softmax')(x)
output_layer = x
model = Model(input_layer, output_layer)
model.summary()
model.compile(loss='categorical_crossentropy',
optimizer=adam_v2.Adam(learning_rate=0.001),
metrics=['accuracy'])
history = model.fit(train_generator,
validation_data=validation_generator,
epochs=20)
plt.plot(history.history['accuracy'])
plt.show()















 376
376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









