







激活函数小结
摘要
本篇博客对一些激活函数进行总结,以便加深理解和记忆
激活函数分类
-
饱和激活函数:sigmoid、tanh…
-
非饱和激活函数:ReLU、LeakyRelu、ELU、PReLU、RReLU…
-
饱和的概念:设激活函数f(x),当x趋近于正负无穷时,f(x)趋近于0
-
非饱和激活函数的优点
- 非饱和激活函数能解决深层网络带来的梯度消失问题
- 非饱和激活函数有助于加快收敛速度
- 非饱和激活函数能解决深层网络带来的梯度消失问题
sigmoid
- 公式: f ( x ) = 1 1 + e − x f(x)= \frac 1 {1+e^{-x}} f(x)=1+e−x1
- 导数公式: f ′ ( x ) = f ( x ) ( 1 − f ( x ) ) f'(x)=f(x)(1-f(x)) f′(x)=f(x)(1−f(x))
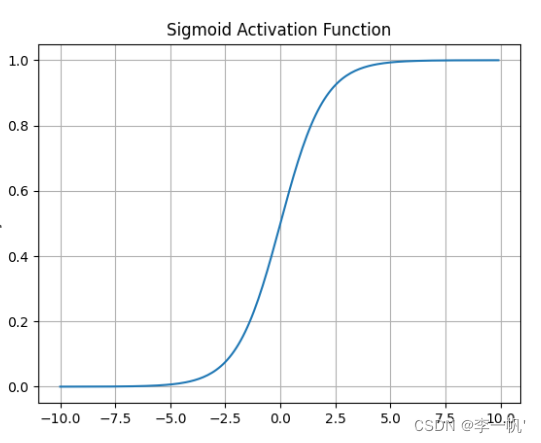
- 何时使用
- 将模型的值压缩到[0,1]范围内的概率值,适用于二分类或置信度
- 梯度平滑,便于求导
- 缺点
- 容易造成梯度消失。我们从导函数图像中了解到sigmoid的导数都是小于0.25的,那么在进行反向传播的时候,梯度相乘结果会慢慢的趋向于0。这样几乎就没有梯度信号通过神经元传递到前面层的梯度更新中,因此这时前面层的权值几乎没有更新,这就叫梯度消失。除此之外,为了防止饱和,必须对于权重矩阵的初始化特别留意。如果初始化权重过大,可能很多神经元得到一个比较小的梯度,致使神经元不能很好的更新权重提前饱和,神经网络就几乎不学习
- 函数输出不是以 0 为中心的,梯度可能就会向特定方向移动,从而降低权重更新的效率
- 执行指数运算,计算机运行得较慢,比较消耗计算资源
Sigmoid函数在历史上曾非常常用,但是现在它已经不太受欢迎,实际中很少使用
Tanh
- 公式: f ( x ) = e x − e − x e x + e − x ( = 2 s i g m o i d ( 2 x ) − 1 ) f(x) = \frac {e^x - e^{-x}} {e^x + e^{-x}} \;\;\;(=2sigmoid(2x)-1) f(x)=ex+e−xex−e−x(=2sigmoid(2x)−1)
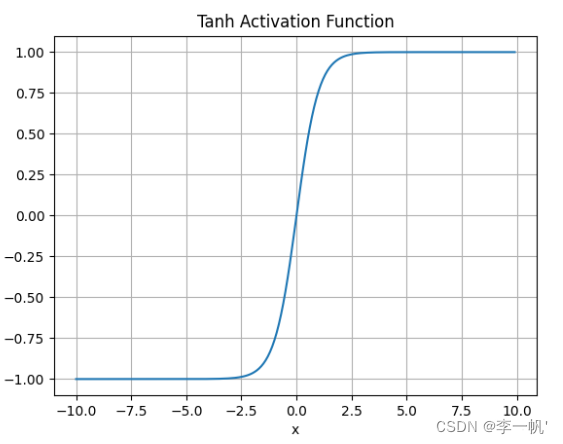
- 何时使用
- 映射范围为[-1,1],且函数以0为中心,比sigmoid更好
- 负输入将被强映射为负,而零输入被映射为接近零
- 缺点
- 仍然存在梯度饱和的问题
- 依然进行的是指数运算
Softsign
- 公式: f ( x ) = x 1 + ∣ x ∣ f(x) = \frac x {1+|x|} f(x)=1+∣x∣x
- 导数: f ′ ( x ) = 1 ( 1 + ∣ x ∣ ) 2 f'(x)= \frac 1 {(1+|x|)^2} f′(x)=(1+∣x∣)21
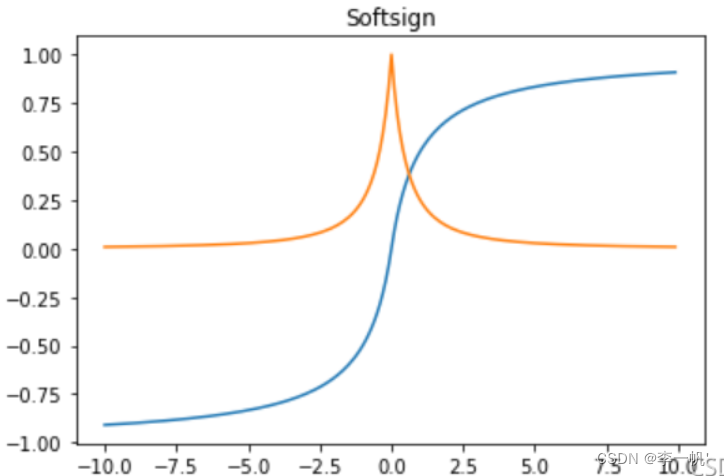
- Softsign函数是Tanh函数的另一个替代选择,是反对称、去中心、可微分,并返回-1和1之间的值。其更平坦的曲线与更慢的下降导数表明它可以更高效地学习,比tTanh函数更好的解决梯度消失的问题
- Softsign函数的导数的计算比Tanh函数更复杂
Softmax
- 公式: f ( x ) = e X i ∑ i e
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









