









Java学习——Java集合(上)
文章目录
一、对象容器——集合
集合本质是基于某种数据结构数据容器。常见的数据结构:数组(Array)、集(Set)、队列 (Queue)、链表(Linkedlist)、树(Tree)、堆 (Heap)、栈(Stack)和映射(Map)等结构。
(1). 类集设置的目的
普通的对象数组的最大问题在于数组中的元素个数是固定的,不能动态的扩充大小,所以最早的时候可以通过链表实现一个动态对象数组。但是这样做毕竟太复杂了,所以在 Java 中为了方便用户操作各个数据结构, 所以引入了类集的概念,有时候就可以把类集称为 java 对数据结构的实现。
在整个类集中的,这个概念是从 JDK 1.2(Java 2)之后才正式引入的,最早也提供了很多的操作类,但是并没有完 整的提出类集的完整概念。
类集中最大的几个操作接口:Collection、Map、Iterator,这三个接口为以后要使用的最重点的接口。 所有的类集操作的接口或类都在 java.util 包中。
Java 类集结构图:

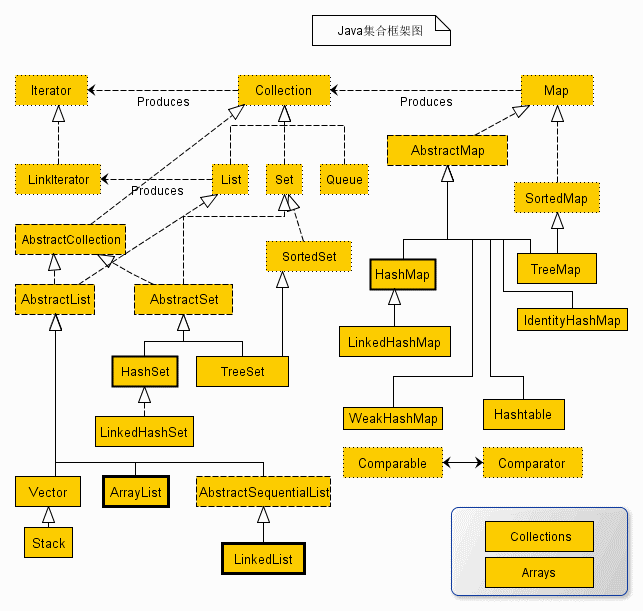
二、三大父接口——Collection
Collection 接口是在整个 Java 类集中保存单值的最大操作父接口,里面每次操作的时候都只能保存一个对象的数据。 此接口定义在 java.util 包中。
此接口定义如下:
public interface Collection<E> extends Iterable<E>
此接口使用了泛型技术,在 JDK 1.5 之后为了使类集操作的更加安全,所以引入了泛型。
接口中一共定义了 15 个方法,那么此接口的全部子类或子接口就将全部继承以上接口中的方法。

在开发中不会直接使用 Collection 接口。而使用其操作的子接口:List、Set。
(1).List 接口
在整个集合中 List 是 Collection 的子接口,里面的所有内容都是允许重复的。
List 子接口的定义:
public interface List<E> extends Collection<E>
在 List 接口中有以上 10 个方法是对已有的 Collection 接口进行的扩充:

我们通常使用的是此接口的实现类,常用的实现类有如下几个: · ArrayList(95%)、Vector(4%)、LinkedList(1%)
1.ArrayList
ArrayList: Object[]数组,默认初始化容量:10
ArrayList 是 List 接口的子类,此类的定义如下:
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, Serializable
此类继承了 AbstractList 类。AbstractList 是 List 接口的子类。AbstractList 是个抽象类,适配器设计模式。
扩容
添加元素时使用 ensureCapacityInternal() 方法来保证容量足够,如果不够时,需要使用 grow() 方法进行扩容,新容量的大小为 oldCapacity + (oldCapacity >> 1),也就是旧容量的 1.5 倍。
- 主要一个超精度负数判断,如果经度精度过长,则默认使用当前长度
- 数据复制使用Arrays.copyOf(elementData, newCapacity);
内存空间占用
ArrayList 的空间浪费主要体现在在 list 列表的结尾会预留一定的容量空间,而 LinkedList 的空间花费则体现在它的每一个元素都需要消耗比 ArrayList 更多的空间(因为要存放直接后继和直接前驱以及数据)。
示例:
import java.util.ArrayList;
import java.util.List;
public class Demo1 {
public static void main(String[] args) {
List<String> all = new ArrayList<String>(); // 实例化List对象,并指定泛型类型
all.add("hello "); // 增加内容,此方法从Collection接口继承而来
all.add(0, "LAMP "); // 增加内容,此方法是List接口单独定义的
all.add("world"); // 增加内容,此方法从Collection接口继承而来
System.out.println(all); // 打印all对象调用toString()方法
all.add("hello "); // 增加内容,此方法从Collection接口继承而来
all.add(0, "LAMP2 "); // 指定下标,若改下标存在数据,则做覆盖操作
all.add("world"); // 增加内容,此方法从Collection接口继承而来
all.remove(1); // 根据索引删除内容,此方法是List接口单独定义的
boolean flag = all.remove("world"); // 删除指定的对象,返回布尔类型
System.out.println("删除情况:" + flag);
System.out.println("集合中的内容是:");
for (int x = 0; x < all.size(); x++) { // size()方法从Collection接口继承而来
System.out.print(all.get(x) + "、"); // 此方法是List接口单独定义的
}
}
}
结果:

此类的iterator和listIterator方法返回的迭代器是快速失败的:
在使用迭代器对集合进行遍历的时候,我们在多线程下操作非安全失败(fail-safe)的集合类可能就会触发 fail-fast 机制,导致抛出 ConcurrentModificationException 异常。另外,在单线程下,如果在遍历过程中对集合对象的内容进行了修改的话也会触发 fail-fast 机制。
如果在创建迭代器之后的任何时候对列表进行结构修改,除了通过迭代器自己的remove或add方法之外,迭代器将抛出ConcurrentModificationException。
因此,在并发修改的情况下,迭代器快速而干净地失败,而不是在未来的未确定时间冒任意,非确定性行为的风险。
请注意,此实现不同步。 如果多个线程同时访问ArrayList实例,并且至少有一个线程在结构上修改了列表,则必须在外部进行同步。 (结构修改是添加或删除一个或多个元素的任何操作,或显式调整后备数组的大小;仅设置元素的值不是结构修改。)这通常通过同步一些自然封装的对象来实现。
如果不存在此类对象,则应使用Collections.synchronizedList方法“包装”该列表。 这最好在创建时完成,以防止意外地不同步访问列表:
List list = Collections.synchronizedList(new ArrayList(...));
2.Vector
Vector:Object[]数组
Vector 本身也属于 List 接口的子类
此类的定义如下:
public class Vector<E> extends AbstractList<E> implements List<E>,RandomAccess, Cloneable, Serializable
此类与 ArrayList 类一样,都是 AbstractList 的子类。所以,此时的操作只要是 List 接口的子类就都按照 List 进行操作。
示例:
我们仅是将上面ArrayList示例中的ArrayList改为Vector(其实与ArrayList操作方法大致)

运行结果一致。Vector 属于 Java 元老级的操作类,是最早的提供了动态对象数组的操作类,在 JDK 1.0 的时候就已经推出了此 类的使用,只是后来在 JDK 1.2 之后引入了 Java 类集合框架。但是为了照顾很多已经习惯于使用 Vector 的用户,所以在 JDK 1.2 之后将 Vector 类进行了升级了,让其多实现了一个 List 接口,这样才将这个类继续保留了下来。
Vector 类和 ArrayList 类的区别

3.链表操作类:LinkedList
双向链表(JDK1.6 之前为循环链表,JDK1.7 取消了循环)
LinkedList定义了一个内部的Node 节点,基于双向链表实现,使用 Node 存储链表节点信息。
此类的定义如下:
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, Serializable
此类继承了 AbstractList,所以是 List 的子类。但是此类也是 Queue 接口的子类,Queue 接口定义了如下的方法:

示例:
import java.util.LinkedList;
import java.util.Queue;
public class Demo1 {
public static void main(String[] args) {
Queue<String> queue = new LinkedList<String>();
queue.add("A");
queue.add("B");
queue.add("C");
int len = queue.size(); //把queue的大小先取出来,否则每循环一次,移除一个元素,就少一个元素,那么queue.size()在变小,就不能循环queue.size()次了。
for (int x = 0; x < len; x++) {
System.out.println(queue.poll()); //将遍历结果弹出队列,并返回输出
}
System.out.println(queue); //队列中所有均被弹出,此时队列为空
}
}
结果:

(1).Set 接口
Set 接口也是 Collection 的子接口,与 List 接口最大的不同在于,Set 接口里面的内容是不允许重复的。 Set 接口并没有对 Collection 接口进行扩充,基本上还是与 Collection 接口保持一致。因为此接口没有 List 接口中定义 的 get(int index)方法,所以无法使用循环进行输出。
那么在此接口中有两个常用的子类:HashSet、TreeSet
1.散列存放:HashSet
HashSet 基于 HashMap 实现的,底层采用 HashMap 来保存元素,HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个固定对象。
Set 接口并没有扩充任何的 Collection 接口中的内容,所以使用的方法全部都是 Collection 接口定义而来的。
HashSet集合存储数据的结构(哈希表)
什么是哈希表呢?
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率
较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
简单的来说,哈希表是由数组+链表+红黑树(JDK1.8增加了红黑树部分)实现的,如下图所示。

存储流程:

HashSet 属于散列的存放类集,里面的内容是无序存放的。
import java.util.HashSet;
import java.util.Set;
public class Demo1 {
public static void main(String[] args) {
Set<String> all = new HashSet<String>(); // 实例化Set接口对象
all.add("A");
all.add("B");
all.add("C");
all.add("D");
System.out.println("添加情况:" + all.add("A")); //Set中不允许有重复元素,添加失败
System.out.println(all);
Object obj[] = all.toArray(); // 将集合变为对象数组
String[] str = all.toArray(new String[] {});// 变为指定的泛型类型数组
for (Object i : obj) {
System.out.print(i + "、");
}
System.out.println();
for (String i : str) {
System.out.print(i + "、");
}
}
}
运行结果:

使用 HashSet 实例化的 Set 接口实例,本身属于无序的存放。 那么,通过循环的方式将 Set 接口中的内容输出,因为在 Collection 接口中定义了将集合变为对象数组进行输出。
2.排序的子类:TreeSet
与 HashSet 不同的是,TreeSet 本身属于排序的子类。
此类的定义如下:
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, Serializable
排序功能验证:
import java.util.Set;
import java.util.TreeSet;
public class Demo1 {
public static void main(String[] args) {
Set<String> all = new TreeSet<String>();
all.add("D");
all.add("C");
all.add("A");
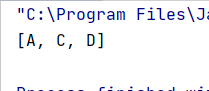
System.out.println(all);
}
运行结果:
接着在Demo中自定义一个内部类Person,用于实现TreeSet的排序功能的实现,然后在main方法中定义TreeSet集合实现:
import java.util.Set;
import java.util.TreeSet;
public class Demo1 {
public static void main(String[] args) {
Set<Person> all = new TreeSet<Person>();
all.add(new Person("张三", 10));
all.add(new Person("李四", 9));
all.add(new Person("王五", 11));
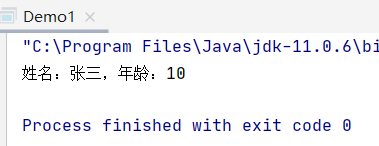
System.out.println(all);
}
static class Person {
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String toString() {
return "姓名:" + this.name + ",年龄:" + this.age;
}
}
}
运行结果:

此时的提示是:Person 类不能向 Comparable 接口转型的问题?
所以,如果现在要是想进行排序的话,则必须在 Person 类中实现 Comparable 接口。
我们在Person类继承接口Comparable ,改动如下:
static class Person implements Comparable<Person>{ //继承接口Comparable里的泛型放你需要比较的对象
private String name;
private int age;
//重写接口方法compareTo
@Override
public int compareTo(Person o) { //方法内自定义你需要比较所实现的逻辑
//this 与 o 比较
//返回数据: 负数 this小/零 一样大/正数 this大
if (this.age > o.age) { //我么你属于类中的age作比较
return 1;
}else if (this.age == o.age) {
return 0;
}else {
return -1;
}
}
运行结果:

特殊情况:

结果:
因为我们在定义接口中的compareTo方法使用的是age作比较,当age相等时,该方法返回0,表示一样大。由于Set 接口里面的内容是不允许重复的,当然其实现的子类也不能,而HashSetcompareTo方法是通过实现的,所以出现添加失败的情况。
我们改动age的话:

结果可以看到,添加成功:

关于重复元素的说明
我们在HashSet无序存储数据时,理应满足继承接口Set的不存在重复元素的特性
我么如是定义:
Set<Person> all = new HashSet<Person>();
all.add(new Person("张三", 10));
all.add(new Person("李四", 10));
all.add(new Person("李四", 10));
all.add(new Person("王五", 11));
all.add(new Person("赵六", 12));
all.add(new Person("孙七", 13));
for (Person p : all) {
System.out.println(p);
}
运行结果:

此时发现,并没有去掉所谓的重复元素,也就是说之前的操作并不是真正的重复元素的判断,而是通过 Comparable 接口间接完成的。
如果要想判断两个对象是否相等,则必须使用 Object 类中的 equals()方法。
从最正规的来讲,如果要想判断两个对象是否相等,则有两种方法可以完成:
- 判断两个对象的编码是否一致,这个方法需要通过 hashCode()完成,即:每个对象有唯一的编码
- 还需要进一步验证对象中的每个属性是否相等,需要通过 equals()完成。
所以此时需要覆写 Object 类中的 hashCode()方法,此方法表示一个唯一的编码,一般是通过公式计算出来的。
我们在Person类中重写两个方法:
public boolean equals(Object obj) {
if (this == obj) {
return true;
}
if (!(obj instanceof Person)) {
return false;
}
Person per = (Person) obj;
if (per.name.equals(this.name) && per.age == this.age) {
return true;
} else {
return false;
}
}
public int hashCode() {
return this.name.hashCode() * this.age;
}
运行得到:

Comparator比较器
Connection中排序方法:
public static <T> void sort(List<T> list)`
将集合中元素按照默认规则排序。
用字符串示例:
import java.util.ArrayList;
import java.util.Collections;
public class Demo1 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
list.add("nba");
//排序方法
Collections.sort(list);
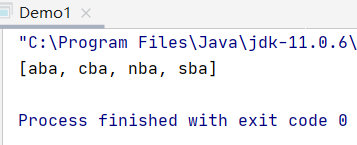
System.out.println(list);
}
}
结果:
我们使用的是默认的规则完成字符串的排序,那么默认规则是怎么定义出来的呢?
说到排序了,简单的说就是两个对象之间比较大小,那么在JAVA中提供了两种比较实现的方式,一种是比较死板的采用 java.lang.Comparable 接口去实现,一种是灵活的当我需要做排序的时候在去选择的 java.util.Comparator 接口完成。
那么我们采用的 public static <T> void sort(List<T> list) 这个方法完成的排序,实际上要求了被排序的类型需要实现Comparable接口完成比较的功能,在String类型上如下:
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
String类实现了这个接口,并完成了比较规则的定义,但是这样就把这种规则写死了,那比如我想要字符串按照第一个字符降序排列,那么这样就要修改String的源代码,这是不可能的了,那么这个时候我们可以使用
public static <T> void sort(List<T> list,Comparator<? super T> )
方法灵活的完成,这个里面就涉及到了Comparator这个接口,位于位于 java.util 包下,排序是comparator能实现的功能之一,该接口代表一个比较器,比较器具有可比性!顾名思义就是做排序的,通俗地讲需要比较两个对象谁排在前谁排在后,那么比较的方法就是:
public int compare(String o1, String o2) //比较其两个参数的顺序。
两个对象比较的结果有三种:大于,等于,小于。
如果要按照升序排序, 则o1 小于o2,返回(负数),相等返回0,01大于02返回(正数)
如果要按照降序排序 则o1 小于o2,返回(正数),相等返回0,01大于02返回(负数)
示例:
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
public class Demo1 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<String>();
list.add("cba");
list.add("aba");
list.add("sba");
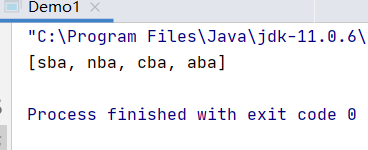
list.add("nba"); //排序方法 按照第一个单词的降序
Collections.sort(list, new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o2.charAt(0) - o1.charAt(0);
}
});
System.out.println(list);
}
}
结果:
Comparable和Comparator两个接口的区别
Comparable:强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序,类的compareTo方法被称为它的自然比较方法。只能在类中实compareTo()一次,不能经常修改类的代码实现自己想要的排序。实现此接口的对象列表(和数组)可以通过Collections.sort(和Arrays.sort)进行自动排序,对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparator强行对某个对象进行整体排序。可以将Comparator 传递给sort方法(如Collections.sort或 Arrays.sort),从而允许在排序顺序上实现精确控制。还可以使用Comparator来控制某些数据结构
(如有序set或有序映射)的顺序,或者为那些没有自然顺序的对象collection提供排序。
Set接口下,TreeSet与HashSet的小结
关于 TreeSet 的排序实现,如果是集合中对象是自定义的或者说其他系统定义的类没有实现 Comparable 接口,则不能实现 TreeSet 的排序,会报类型转换(转向 Comparable 接口)错误。 换句话说要添加到 TreeSet 集合中的对象的类型必须实现了 Comparable 接口。
不过 TreeSet 的集合因为借用了 Comparable 接口,同时可以去除重复值,而 HashSet 虽然是 Set 接口子类,但是对于没有复写 Object 的 equals 和 hashCode 方法的对象,加入了 HashSet 集合中也是不能去掉重复值的。















 1762
1762











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









