







数组
我们可以把数组理解为一种容器,它可以用来存放若干个相同类型的数据元素。
数组的新增操作
1)第一种情况,在数组的最后增加一个新的元素。此时新增一条数据后,对原数据产生没有任何影响。可以直接通过新增操作,赋值或者插入一条新的数据即可。时间复杂度是 O(1)。
2)第二种情况,如果是在数组中间的某个位置新增数据,那么情况就完全不一样了。这是因为,新增了数据之后,会对插入元素位置之后的元素产生影响,具体为这些数据的位置需要依次向后挪动 1 个位置。

数组的删除操作
1) 第一种情况,在这个数组的最后,删除一个数据元素。由于此时删除一条数据后,对原数据没有产生任何影响。我们可以直接删除该数据即可,时间复杂度是 O(1)。
2) 第二种情况,在这个数组的中间某个位置,删除一条数据。同样的,这两种情况的区别在于,删除数据之后,其他数据的位置是否发生改变。由于此时的情况和新增操作高度类似,我们就不再举例子了。
数组的查找操作
数组增删查操作的特点
增加:若插入数据在最后,则时间复杂度为 O(1);如果中间某处插入数据,则时间复杂度为 O(n)。
删除:对应位置的删除,扫描全数组,时间复杂度为 O(n)。
查找:如果只需根据索引值进行一次查找,时间复杂度是 O(1)。但是要在数组中查找一个数值满足指定条件的数据,则时间复杂度是 O(n)。
数组的案例
例题一,假设数组存储了 5 个评委对 1 个运动员的打分,且每个评委的打分都不相等。现在需要你:
用数组按照连续顺序保存,去掉一个最高分和一个最低分后的 3 个打分样本;
计算这 3 个样本的平均分并打印。
要求是,不允许再开辟 O(n) 空间复杂度的复杂数据结构。
1)数组一次遍历,过程中记录下最小值和最大值的索引。对应下面代码的第 7 行到第 16 行。时间复杂度是 O(n)。
2)执行两次基于索引值的删除操作。除非极端情况,否则时间复杂度仍然是 O(n)。对应于下面代码的第 18 行到第 30 行。
3)计算删除数据后的数组元素的平均值。对应于下面代码的第 32 行到第 37 行。时间复杂度是 O(n)。
因此,O(n) + O(n) + O(n) 的结果仍然是 O(n)。
public void getScore() {
int a[] = { 2, 1, 4, 5, 3 };
max_inx = -1;
max_val = -1;
min_inx= -1;
min_val = 99;
for (int i = 0; i < a.length; i++) {
if (a[i] > max_val) {
max_val = a[i];
max_inx = i;
}
if (a[i] < min_val) {
min_val = a[i];
min_inx = i;
}
}
inx1 = max_inx;
inx2 = min_inx;
if (max_inx < min_inx){
inx1 = min_inx;
inx2 = max_inx;
}
for (int i = inx1; i < a.length-1; i++) {
a[i] = a[i+1];
}
for (int i = inx2; i < a.length-1; i++) {
a[i] = a[i+1];
}
sumscore = 0;
for (int i = 0; i < a.length-2; i++) {
sumscore += a[i];
}
avg = sumscore/3.0;
System.out.println(avg);
}
字符串
字符串(string) 是由 n 个字符组成的一个有序整体( n >= 0 )。
字符串的逻辑结构和线性表很相似,不同之处在于字符串针对的是字符集,也就是字符串中的元素都是字符,线性表则没有这些限制。
字符串的存储结构与线性表相同,也有顺序存储和链式存储两种。
字符串的基本操作
与数组的操作很相似。
子串查找(字符串匹配)
首先,我们来定义两个概念,主串和模式串。我们在字符串 A 中查找字符串 B,则 A 就是主串,B 就是模式串。我们把主串的长度记为 n,模式串长度记为 m。由于是在主串中查找模式串,因此,主串的长度肯定比模式串长,n>m。因此,字符串匹配算法的时间复杂度就是 n 和 m 的函数。
第一层循环,去查找第一个字符相等的位置,第二层循环基于此去匹配后续字符是否相等。因此,这种匹配算法的时间复杂度为 O(nm)。其代码如下:
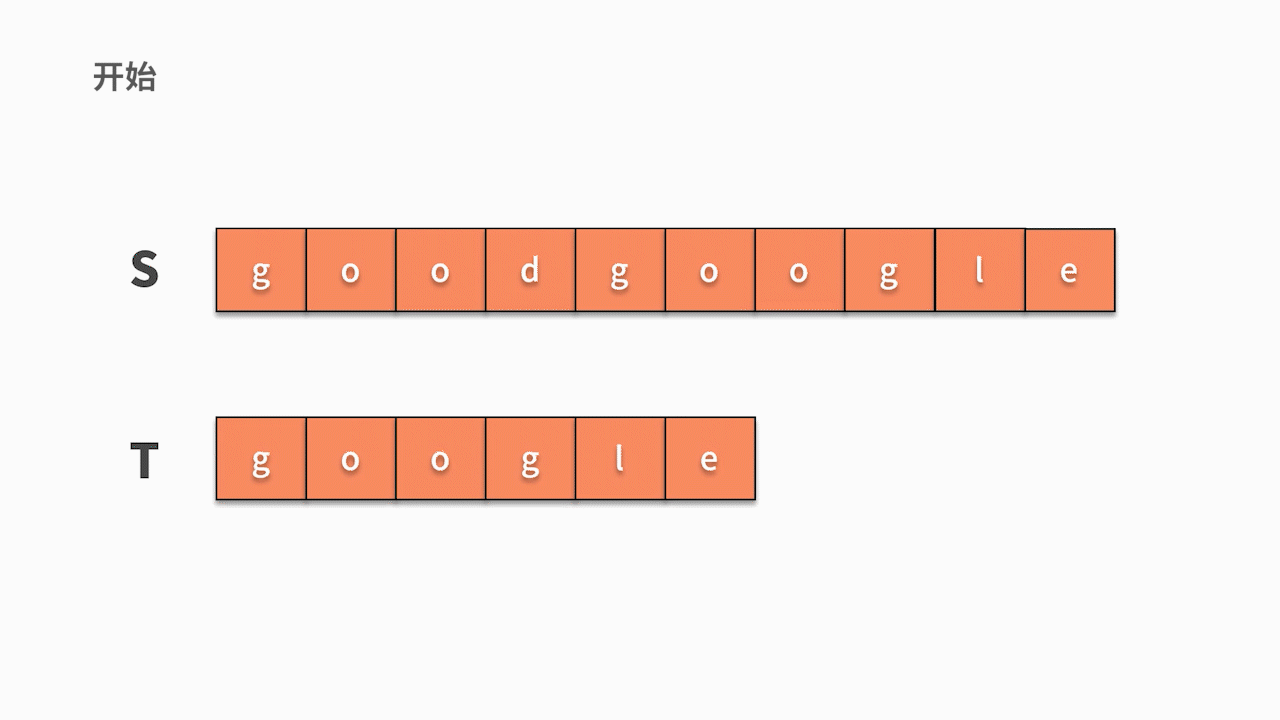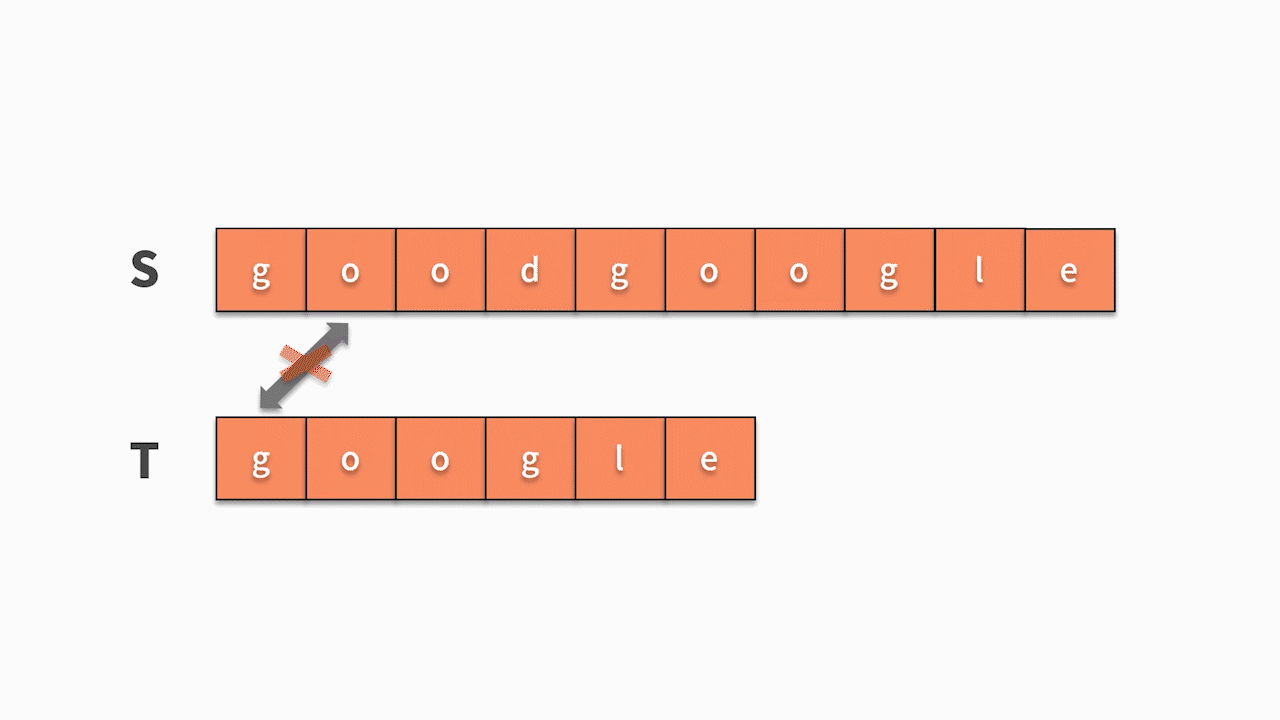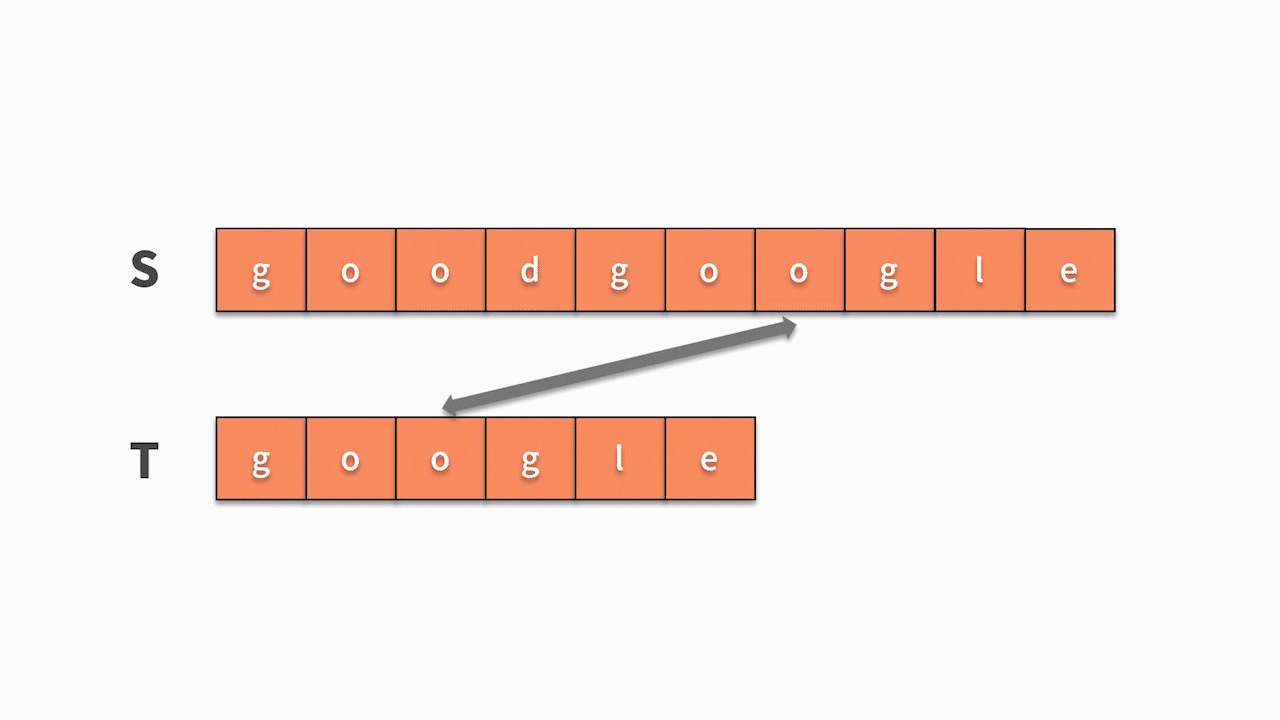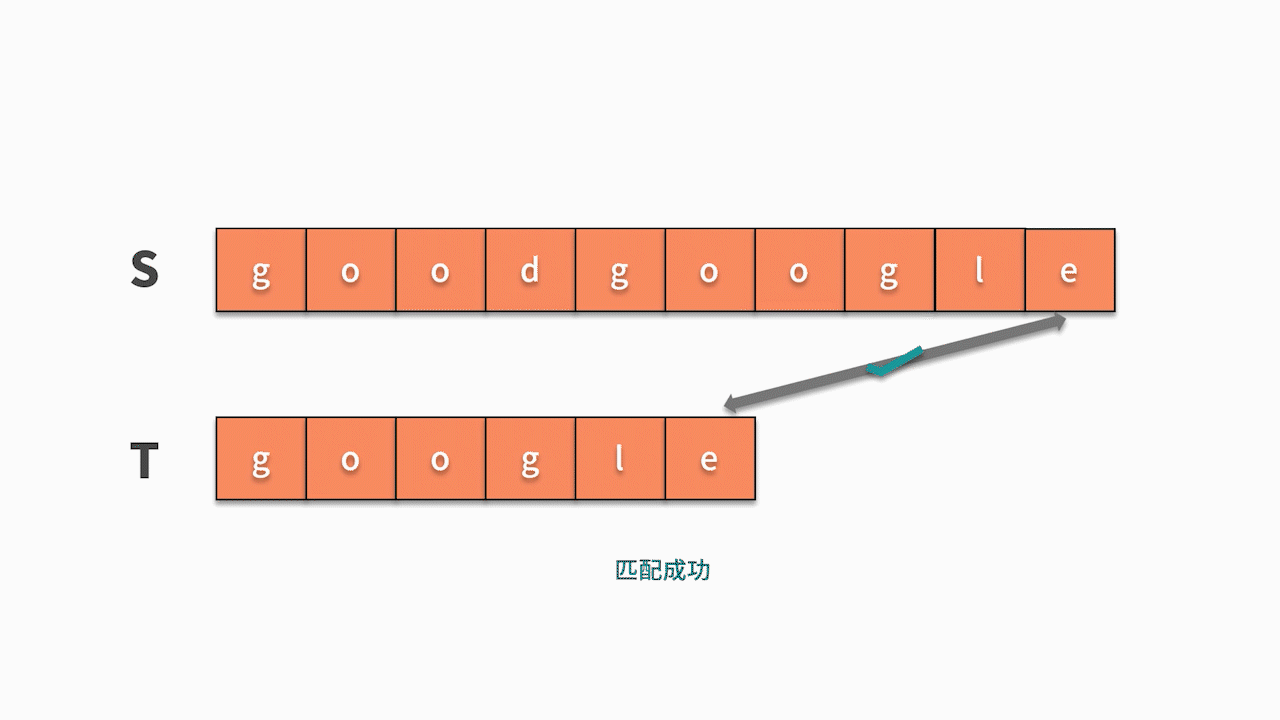
public void s1() {
String s = "goodgoogle";
String t = "google";
int isfind = 0;
for (int i = 0; i < s.length() - t.length() + 1; i++) {
if (s.charAt(i) == t.charAt(0)) {
int jc = 0;
for (int j = 0; j < t.length(); j++) {
if (s.charAt(i + j) != t.charAt(j)) {
break;
}
jc = j;
}
if (jc == t.length() - 1) {
isfind = 1;
}
}
}
System.out.println(isfind);
}
例2:查找出两个字符串的最大公共字串。
假设有且仅有 1 个最大公共子串。比如,输入 a = “13452439”, b = “123456”。由于字符串 “345” 同时在 a 和 b 中出现,且是同时出现在 a 和 b 中的最长子串。因此输出 "345”。
第一步需要两层的循环去查找共同出现的字符,这就是 O(nm)。一旦找到了共同出现的字符之后,还需要再继续查找共同出现的字符串,这也就是又嵌套了一层循环。可见最终的时间复杂度是 O(nmm),即 O(nm²)。代码如下:
public void s2() {
String a = "123456";
String b = "13452439";
String maxSubStr = "";
int max_len = 0;
for (int i = 0; i < a.length(); i++) {
for (int j = 0; j < b.length(); j++){
if (a.charAt(i) == b.charAt(j)){
for (int m=i, n=j; m<a.length()&&n<b.length(); m++,n++) {
if (a.charAt(m) != b.charAt(n)){
break;
}
if (max_len < m-i+1){
max_len = m-i+1;
maxSubStr = a.substring(i, m+1);
}
}
}
}
}
System.out.println(maxSubStr);
}
















 1604
1604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











