









|
ELK是ElasticSearch 、 Logstash、Kibana三大开源框架首字母大写简称。Logstash是ELK的中央数据流,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地。Kibana可以将elastic的数据通过友好的页面展示出来,提供实时分析的功能。
|
- 前期准备:jdk8以上、node环境。
如果不会,请点击我
一,安装ElasticSearch
| 下载ES必须保证jdk1.8+,否则启动ES会失败 |
一、设置谷歌浏览器默认下载地址(我们需要下载的东西有点多,所以放在一个文件夹下,比较好管理)
- 新建ELK文件夹(我是在D盘下)

- 设置谷歌浏览器默认下载地址
浏览器右上角->设置->高级->下载位置


二、华为云镜像安装(需要有华为云账号,手机号注册就够了)


-
下载完成->解压到当前目录下:

-
目录结构

-
config目录:

-
jvm.options默认是1G内存给ES使用的,我电脑比较菜,就只能安排512m(在电脑内存范围内,当然越高性能越好)

-
修改保存后:
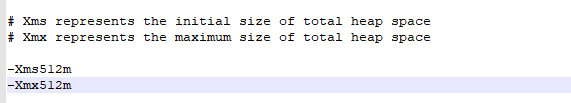
-
点击:elasticsearch.bat启动


- 打开9200端口(出现如下,说明ES安装成功)

二,安装elasticsearch-head-master插件
| elasticsearch可能有很多节点(es默认单个也是一个集群),使用es可视化界面可以方便调度es集群 |
-
由于该插件是基于webpack的,需要node环境(如果还没有安装,本文最开始给了安装方法)
-
下载(东西比较小,直接到github上去下载)

-
下面是git安装(压缩包下载安装也可以)
-
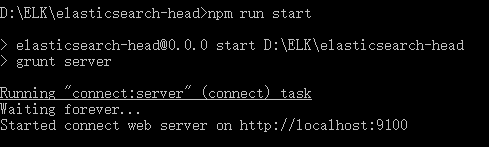
下载后,进入文件夹下执行((如果配置了淘宝镜像,cnpm下载更快)):
npm install
- 最后启动:
- 发现不能连接es(点击连接,右边显示,跨域了,ES进程与客户端端口不同,存在了跨域)

- 在ES下解决跨域问题(保存修改后,重启es进程):

- 修改配置文件有一个坑,yml文件,k与v要有空格,不然程序会闪退(语法不对,读取文件错误)。

三,安装kibana
| Kibana是一个针对ElasticSearch的开源分析及可视化平台,用来搜索、查看交互存储在ElasticSearch索引中的数据。使用Kibana,可以通过各种如表进行高级数据分析及展示。Kibana让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板实时显示Elasticsearch查询动态。设置Kibana非常简单。无需编码或者额外的基础构架,几分钟内就可以完成Kibana安装并启动Elasricsearch索引检测。 |
- 安装kibana(和安装ES一样,我们到华为云镜像仓库下载)

- 和ES一样,我们也选择7.6.1下载(版本差距过大会有冲突),下载完成解压就好了

- 设置中文(Kibana在6.7版本开始,支持了多种语言。并且自带在安装包里。默认为英文,我们需要修改配置文件变为中文)

- 启动kibana,好起来了

- 试一下效果:

- 用ES-head查询数据

| 一般我们用ES-head去查询,kibana去操作数据(它也可以查询) |
四,安装Logstash
| Mysql、ES数据同步 |
- 官网地址
点击此处 - 选择与ES版本一样的Logstash

- 在Logstash目录里面添加mysql jar包

- logstash/config里面添加一个文件:mysql.config
input {
jdbc {
# mysql相关jdbc配置
jdbc_connection_string => "jdbc:mysql://172.16.21.11:3306/kjt_data?characterEncoding=utf8&serverTimezone=Asia/Shanghai"
jdbc_user => "shuang"
jdbc_password => "shuang@12345"
# jdbc连接mysql驱动的文件目录
jdbc_driver_library => "./config/mysql-connector-java-8.0.17.jar"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_paging_enabled => true
jdbc_page_size => "50000"
jdbc_default_timezone =>"Asia/Shanghai"
# mysqlSQL语句
statement => "select id,title, CONCAT_WS(' ' ,type,tag1,tag2,tag3) as tag,update_time FROM kjt_patent"
# 也可以使用文件
# statement_filepath => "./config/jdbc.sql"
# 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年)
schedule => "* * * * *"
#type => "jdbc"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
#record_last_run => true
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
# 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "update_time"
tracking_column_type => "timestamp"
last_run_metadata_path => "./logstash_capital_bill_last_id"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
#是否将 字段(column) 名称转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
hosts => "172.16.21.31:9200"
index => "kjt_patent"
document_id => "%{id}"
template_overwrite => true
}
# 这里输出调试,正式运行时可以注释掉
stdout {
codec => json_lines
}
}
- 执行如下命令
mysql与ES数据同步问题就好起来了
















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











