






1.get与post
<form action = " " method =post>
<input type = "text" name = "用户名">
<input type = "password" name = "密码">
<input type = "submit" name = "登录">
</form>
当form method使用post时不会在跳转链接处显示登录用户名和密码,而当method选择get时则会显示
2.response
(1).无伪装直接访问
url = 'https://www.bilibili.com/'
response = requests.get(url)
print(response.content.decode('utf-8'))
请求目标url网址的html源码
(2). 伪装成浏览器访问
有些网站有反爬虫机制,对于爬虫的访问会直接返回状态码400 无法访问,此时就需要将爬虫伪装成浏览器访问
url = 'https://www.zhihu.com/'
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
}
response = requests.get(url,headers=headers)
print(response)
关键在于通过user-agent将其伪装成了正常浏览器,对于user-agent的获取可以使用 链接: 获取header(user-agent)
(3)爬取视频
url = "http://v16m-default.akamaized.net/6d32446acfb574d0388c2e779364018e/64edf05f/video/tos/alisg/tos-alisg-v-0000/oUTrruzqIfAQUEAuzVhoqaBGAEzytmm2xzmZwz/?a=2011&ch=0&cr=0&dr=0&net=5&cd=0%7C0%7C0%7C0&br=3566&bt=1783&cs=0&ds=4&ft=iJOG.y7oZZv0PD1HQ-JXg9wz.DKlBEeC~&mime_type=video_mp4&qs=0&rc=fG9iaGwxZmRobDFkd3JAKTZnZWY1ZzRlODc4Zjs3ZztnKXNxdjx4OmVqdWYzM2o2M3l5Xm1sYXNlb2xhc2xmcnFgXi80NDZfMS41L2E0LmAvYTpjZGducDE0YGkzYS0tMjAtLjo%3D&l=2023082906542674BC74C0F6C95688A8F7&btag=e000a8000"
resp = requests.get(url,stream=True)
print(resp)
with open('./data/xxx.mp4','wb') as file:
for j in resp.iter_content(1024*10): #表示每次在内存中的数据大小
file.write(j)
#如果不写for的那行代码,即一次性全部写入 可以直接写
with open('./data/xxx.mp4','wb') as file:
file.write(resp.content)
(4)爬取图片
url = "https://www.sikiedu.com/files/default/2018/01-22/153438ed7998058773.png"
url2 = "https://www.sikiedu.com/files/course/2020/05-05/1913404b8d78277853.png"
urls = []
urls.append(url)
urls.append(url2)
for x in range(len(urls)): #range(10)表示返回从0-9的数列
resp = requests.get(urls[x])
with open('./data/' + str(x) + '.png','wb') as file:
file.write(resp.content)
(5)一次性爬取多张图片
url="http://www.gaokao.com/gkpic/index.shtml"
resp=requests.get(url)
html=resp.content.decode('gbk')
# print(html)
urls = re.findall('<img src="(.*)" alt=".*">',html) //此处(.*)括号表示显示src的内容.代表除换行符之外的任意字符,*代表前一个字符的任意数量
titles = re.findall('<p class="p1">(.*?)</p>',html) //?表示只匹配前面标签一次
for i in range(0,len(urls)):
with open('./data/picture/'+titles[i]+'.jpg','wb') as file:
resp = requests.get(urls[i])
file.write(resp.content)
print('第{}张图片下载完成'.format(i))
//tiltes 因为是字符串所以可以不用requests.get,但urls中的本身是链接所以需要requests.get
注:在写python代码时哪怕是在等于号前后也不要随意的加空格
(6)json与python的转换
json->python json.loads()
python->json json.dumps()
url = "http://httpbin.org/get"
proxies={
'http':'58.220.95.79' //代理找免费代理网站即可
}
resp = requests.get(url,proxies=proxies)
# resp = requests.get(url)
print(resp.text)
(7) request模拟登录
url = "http://spiderbuf.cn/e01/list" //注意url是实际登录后跳转的页面而不是login
data = {
"password":"123456",
"username":"admin"
}
headers = {
"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36",
}
resp = requests.get(url,data=data,headers=headers)
# resp = requests.get(url,headers)
# print(resp.text)
print(resp.cookies)
(8) 模拟百度登录
其实现原理为在浏览器登录后从网站抓取到其cookies,然后在pycharm中模拟登录时直接注入cookies伪装自己已经登录
cookies={ //最大的工作量在于cookies的爬取
"BAIDUID":"4F9D42E95CB0D57F47F8930B3F098DC3:FG=1",
"BIDUPSID":"4F9D42E95CB0D57FD651878762E506B7",
"PSTM":"1693453350",
"BD_UPN":"13314752",
"ZFY":"DgFg:AIAmhnnmclTqpPfSvb9OGiK001bKb0K4HvL0B1A:C",
"COOKIE_SESSION":"24_0_2_2_4_12_1_0_0_2_1_2_123_0_107_0_1693474768_0_1693474661%7C2%230_0_1693474661%7C1",
"BDRCVFR[Fc9oatPmwxn]":"aeXf-1x8UdYcs",
"BA_HECTOR":"a10k21a1ag2g0k042g848h0g1if5sb31o",
"BDORZ":"B490B5EBF6F3CD402E515D22BCDA1598",
"BDUSS":"1V3Nk1TelB3RDB1VXdvWVJ6NjN4YXJDVjJpbkRQQU00bmRMY2cyNlZWZDBmaHBsRVFBQUFBJCQAAAAAAAAAAAEAAAAOT~1fsbS~qNOxAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAHTx8mR08fJkU"
}
url = "http://www.baidu.com/"
resp = requests.get(url,cookies=cookies)
print(resp.content.decode("utf-8"))
(9)对于cookies信息格式进行自动转换
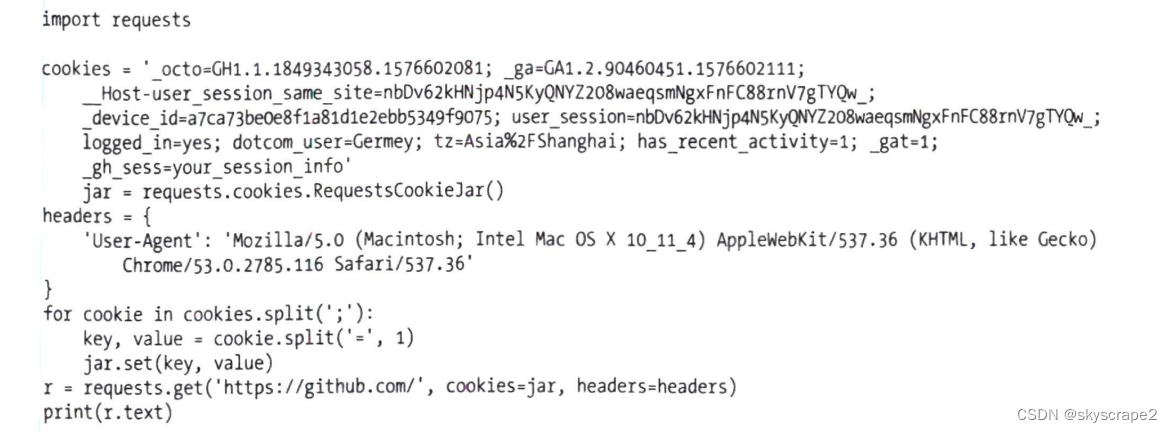
通过创建jar来储存cookies信息,然后用split函数对于原始cookies信息进行分割
(10)session会话保持同浏览器访问
url = 'https://www.httpbin.org/cookies/set/number/123456'
s = requests.session();
s.get(url);
response = s.get('https://www.httpbin.org/cookies')
print(response.content.decode('utf-8'))
3.爬取項目
import logging
import requests
import re
import json
import multiprocessing
from os import mkdir
from os.path import exists
from urllib.parse import urljoin
# logging.basicConfig(level=logging.INFO, format='%(asctime)s-%(levlename)s:%(message)s')
RESULTS_DIR = 'results'
exists(RESULTS_DIR) or mkdir(RESULTS_DIR)
logging.basicConfig(level=logging.INFO,
format='%(asctime)s - %(levelname)s: %(message)s') #定义logging日志的格式
Base_url = 'https://ssr1.scrape.center'
Total_page = 10
def scrape_page(url): #获取网页的text
logging.info('scraping %s...', url)
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
logging.error('get invalid status code %s while scraping %s', response.status_code, url)
except requests.RequestException:
logging.error('error occurred while scraping %s', url, exc_info=True)
def scrape_index(page): #获取网页的具体url
# index_url = f'{Base_url}/detail/{page}'
# index_url = f'{Base_url}/page/{page}'
# return scrape_page(index_url)
index_url = str(Base_url) + "/page/" + str(page)
return scrape_page(str(index_url))
def parse_index(html): #获取每部电影详情的url
pattern = re.compile('<a.*?href="(.*?)".*?class="name">')
items = re.findall(pattern, html)
if not items:
return []
for item in items:
detail_url = urljoin(Base_url, item)
logging.info('get detail url %s', detail_url)
yield detail_url
def scrape_detail(url):
return scrape_page(url)
def parse_detail(html):
cover_pattern = re.compile('<img.*?src="(.*?)".*?class="cover">', re.S)
name_pattern = re.compile('<h2.*?>(.*?)</h2>')
publishat_pattern = re.compile('(\d{4}-\d{2}-\d{2})')
categrioes_pattern = re.compile('<button.*?<span>(.*?)</span>.*?', re.S)
score_pattern = re.compile('<p.*?score.*?>(.*?)</p>', re.S)
# drama_pattern = re.compile('<div.*?class="drama".*?<p.*?>"(.*?)".*?', re.S)
drama_pattern = re.compile('<div.*?drama.*?>.*?<p.*?>"(.*?)"</p>', re.S)
# if re.search(drama_pattern,html):
# drama=re.search(drama_pattern,html).group(1).strip()
# else:
# drama=None
if re.search(cover_pattern,html):
cover = re.search(cover_pattern, html).group(1).strip()
else:
cover=None
if re.search(name_pattern,html):
name=re.search(name_pattern,html).group(1).strip()
else:
name=None
if re.findall(categrioes_pattern,html):
categrious=re.findall(categrioes_pattern,html)
else:
categrious=None
if re.search(publishat_pattern,html):
publishat=re.search(publishat_pattern,html).group(1).split()
else:
publishat=None
if re.search(score_pattern,html):
score=re.search(score_pattern,html).group(1).split()
else:
score=None
return{
'cover': cover,
'name': name,
'categrious': categrious,
# 'drama':drama,
'publishat': publishat,
'score': score
}
def save_data(data):
name=data.get('name')
data_path=f'{RESULTS_DIR}/{name}.txt'
json.dump(data, open(data_path, 'w', encoding='utf-8'), ensure_ascii=False, indent=2)
def main(page):
index_html = scrape_index(page)
detail_urls = parse_index(index_html)
for detail_url in detail_urls:
detail_html = scrape_detail(detail_url)
data = parse_detail(detail_html)
logging.info('get detail data %s',data)
logging.info('saving datat to file')
save_data(data)
logging.info('save data successfully')
if __name__ == "__main__":
pool = multiprocessing.Pool() #多线程模式,用以不同的线程去分别检索目标网页
pages=range(1, Total_page+1)
pool.map(main ,pages)
pool.close()
pool.join()















 2712
2712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









