







拓扑结构
 我们的hadoop的版本为2.7.1 所以要去找scala和spark与hadoop2.7.1相对应的版本
我们的hadoop的版本为2.7.1 所以要去找scala和spark与hadoop2.7.1相对应的版本
这里我使用的是scala2.11.12 和 spark 2.4.6
下载地址:
https://www.scala-lang.org/download/2.11.12.html
http://spark.apache.org/downloads.html
首先将scala和 spark上传到node2上
安装并配置scala
解压并且重命名
tar -xvf scala-2.11.12.tgz
mv scala-2.11.12 scala211
配置scala环境变量
vi /etc/profile

source /etc/profile
测试scala是否安装成功 :输入 scala 命令

然后再配置spark
解压并重命名
tar -xvf spark-2.4.6-bin-hadoop2.7.tgz
mv spark-2.4.6-bin-hadoop2.7 spark246
配置spark的环境变量
vi /etc/profile

source /etc/profile
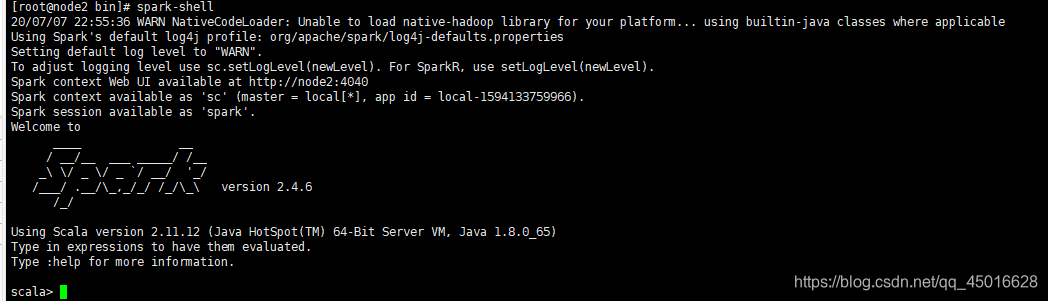
测试spark是否安装成功:输入spark-shell 命令
配置spark集群( 在node2上将node2设为master节点)
进入spark的conf目录,输入 cp spark-env.sh.template spark-env.sh 将文件复制为.sh文件
vi spark-env.sh
输入内容:
JAVA_HOME=/usr/software/jdk8
SCALA_HOME=/usr/local/scala211
HADOOP_HOME=/usr/local/hadoop210
HADOOP_CONF_DIR=/usr/local/hadoop210/etc/hadoop/
SPARK_MASTER_IP=node2
SPARK_WORKER_MEMORY=1G
export JAVA_HOME SCALA_HOME HADOOP_HOME HADOOP_CONF_DIR SPARK_MASTER_IP SPARK_WORKER_MEMORY
cp slaves.template slaves 复制并重命名slaves.template文件 cp slaves.template slaves
vi slaves
#localhost
node3
node4
将 node2上的 scala 发送到 node3, node4中
scp -r scala211/ root@node3:`pwd`
scp -r scala211/ root@node4:`pwd`
配置好环境变量,测试scala:输入scala命令
将 node2上的 spark发送到 node3, node4中
scp -r spark246/ root@node3:`pwd`
scp -r spark246/ root@node4:`pwd`
配置好环境变量,测试spark 输入spark-shell命令
node2,node3,node4已经配置完成
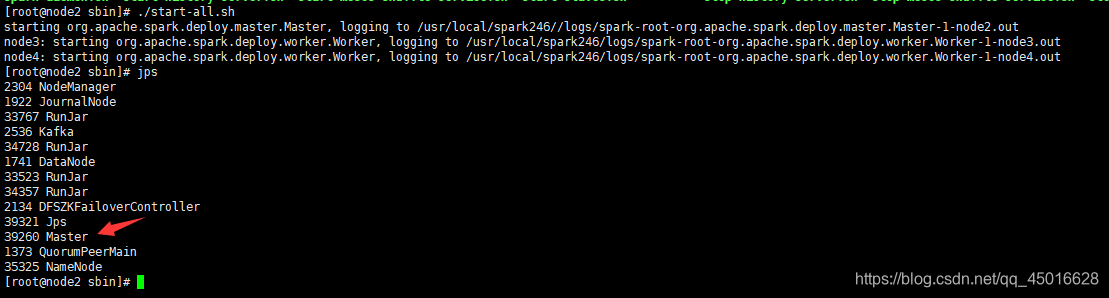
首先确保 hadoop集群先启动, 再进入到 spark安装目录的 sbin下,使用以下命令启动spark集群
./start-all.sh
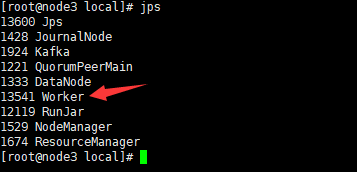
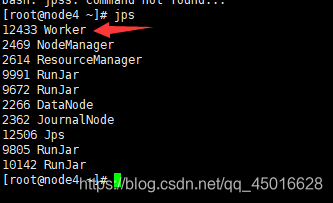
在node2,3,4上查看进程
node2 上有 Master
node3 上有 Worker
node4 上有 Worker
查看Master的 spark UI —— http://node2:8080/
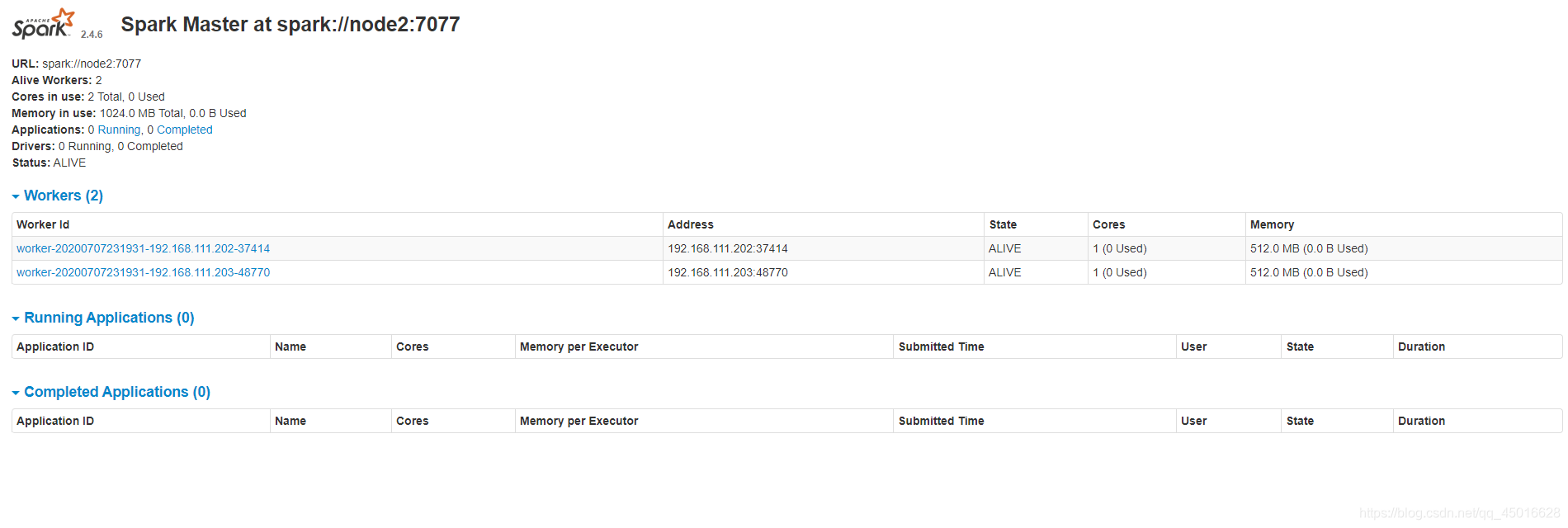 这样集群就配置完成了
这样集群就配置完成了
为了确保是否能正常运行 结合 hadoop集群完成一个 WordCount练习
hadoop dfs -mkdir /input
hadoop fs -put /usr/local/hadoop210/README.txt /input
在spark集群的master节点( node2 )上运行一个 spark-shell
spark-shell --master spark://node2:7077
sc.textFile("hdfs://node1:8020/input/README.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://node1:8020/out1")
在这过程中呢,一直报警告
WARN scheduler.TaskSchedulerImpl: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
而程序是waitting状态,并没有运行,后来将conf的spark-env.sh中的SPARK_WORKER_MEMORY=1G参数从512M该到了1G 就正常运行了
运行成功,得到结果
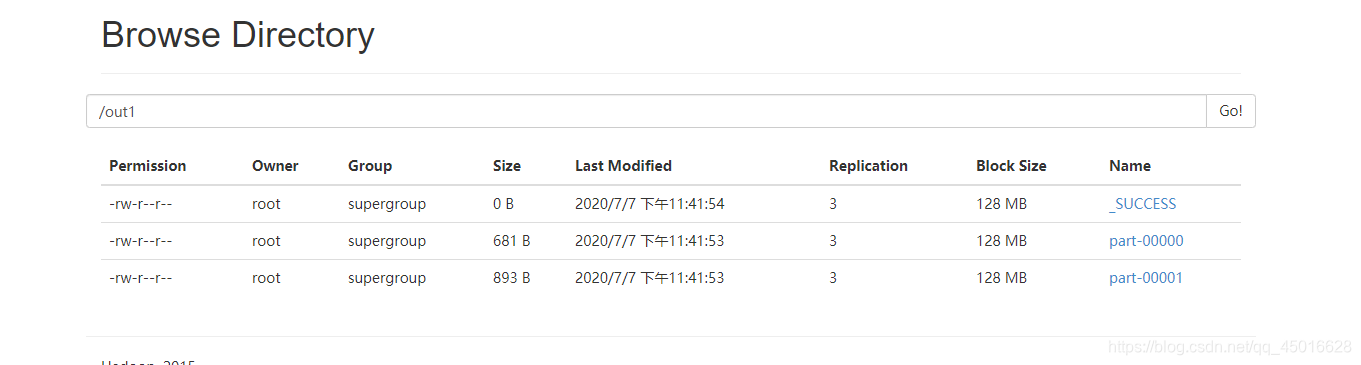















 348
348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









