







 本文详细介绍了如何在CentOS7上安装Scala并以此为基础搭建Spark2.1.1集群,包括下载安装依赖、配置环境变量、配置Spark相关文件以及启动和测试Spark集群的全过程。通过本文,读者可以了解到Spark集群的最小化安装要求以及如何验证安装成功。
本文详细介绍了如何在CentOS7上安装Scala并以此为基础搭建Spark2.1.1集群,包括下载安装依赖、配置环境变量、配置Spark相关文件以及启动和测试Spark集群的全过程。通过本文,读者可以了解到Spark集群的最小化安装要求以及如何验证安装成功。
关键字:Linux CentOS Hadoop Spark Scala Java
版本号:CentOS7 Hadoop2.8.0 Spark2.1.1 Scala2.12.2 JDK1.8
说明:Spark可以在只安装了JDK、Scala的机器上直接单机安装,但是这样的话只能使用单机模式运行不涉及分布式运算和分布式存储的代码,例如可以单机安装Spark,单机运行计算圆周率的Spark程序。但是我们要运行的是Spark集群,并且需要调用Hadoop的分布式文件系统,所以请你先安装Hadoop,Hadoop集群的安装可以参考该博文:
http://blog.csdn.net/pucao_cug/article/details/71698903
安装单机版的Spark可以参考该博文:
http://blog.csdn.net/pucao_cug/article/details/72377219
Spark集群的最小化安装只需要安装这些东西:JDK 、Scala 、Hadoop 、Spark
1 安装Spark依赖的Scala
Hadoop的安装请参考上面提到的博文,因为Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都进行安装。
1.1 下载和解压缩Scala
打开地址:http://www.scala-lang.org/
目前最新版是2.12.2,我就安装该版本
如图:
直接打开下面的地址也可以:
http://www.scala-lang.org/download/2.12.2.html
如图:
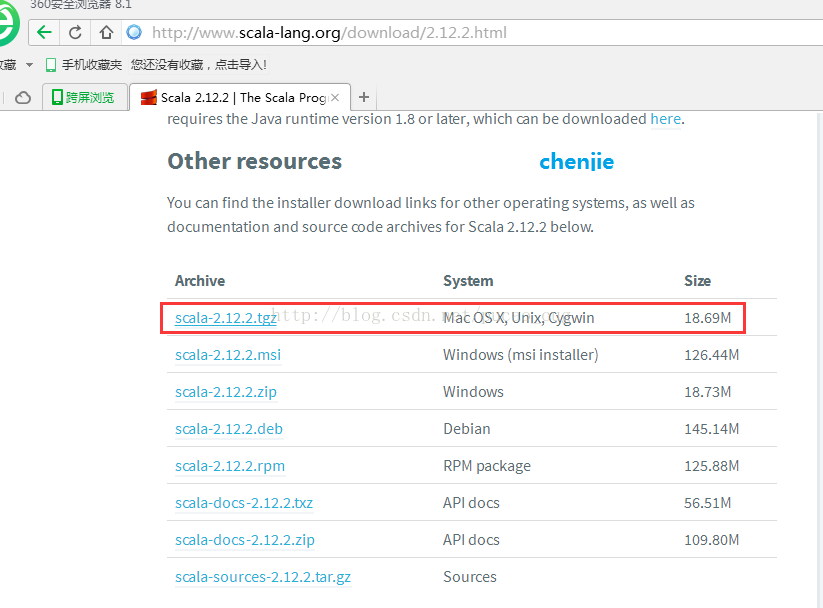
直接用下面的地址下载tgz包也可以:
https://downloads.lightbend.com/scala/2.12.2/scala-2.12.2.tgz
在Linux服务器的opt目录下新建一个名为scala的文件夹,并将下载的压缩包上载上去
如图:
执行命令,进入到该目录:
cd /opt/scala
执行命令进行解压缩:
tar -xvf scala-2.12.2
1.2 配置环境变量
编辑/etc/profile这个文件,在文件中增加一行配置:
export SCALA_HOME=/opt/scala/scala-2.12.2在该文件的PATH变量中增加下面的内容:
${SCALA_HOME}/bin添加完成后,我的/etc/profile的配置如下:
export JAVA_HOME=/opt/java/jdk1.8.0_121
export HADOOP_HOME=/opt/hadoop/hadoop-2.8.0
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib"
export HIVE_HOME=/opt/hive/apache-hive-2.1.1-bin
export HIVE_CONF_DIR=${HIVE_HOME}/conf
export SQOOP_HOME=/opt/sqoop/sqoop-1.4.6.bin__hadoop-2.0.4-alpha
export HBASE_HOME=/opt/hbase/hbase-1.2.5
export ZK_HOME=/opt/zookeeper/zookeeper-3.4.10
export SCALA_HOME=/opt/scala/scala-2.12.2
export CLASS_PATH=.:${JAVA_HOME}/lib:${HIVE_HOME}/lib:$CLASS_PATH
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:${SPARK_HOME}/bin:${ZK_HOME}/bin:${HIVE_HOME}/bin:${SQOOP_HOME}/bin:${HBASE_HOME}/bin:${SCALA_HOME}/bin:$PA 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









