







在这文章以前已经搭建了spark集群,但不是高可用只有一个master,这次是将集群的升级为高可用
spark集群搭建(非高可用)文章地址:https://blog.csdn.net/qq_45016628/article/details/107192428
拓扑结构
 首先呢,要停掉我们之前的spark集群,在spark的sbin目录下运行
首先呢,要停掉我们之前的spark集群,在spark的sbin目录下运行 ./stop-all.sh
从node2上将 scala 和 spark 传给node1
scp -r scala211/ @node1:/`pwd`
scp -r spark246/ @node1:/`pwd`
到node1中配置scala和spark的环境变量,并且测试是否成功
到spark的conf目录下修改 spark-env.sh 配置文件:vi spark-env.sh
将之前配置的删除
JAVA_HOME=/usr/software/jdk8
SCALA_HOME=/usr/local/scala211
HADOOP_HOME=/usr/local/hadoop210
HADOOP_CONF_DIR=/usr/local/hadoop210/etc/hadoop/
#SPARK_MASTER_IP=node2
SPARK_WORKER_MEMORY=1G
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark"
export JAVA_HOME SCALA_HOME HADOOP_HOME HADOOP_CONF_DIR SPARK_MASTER_IP SPARK_WORKER_MEMORY
修改 slaves配置文件:vi slaves
#localhost
node1
node2
node3
node4
将 spark-env.sh, slaves 发送到 node2, 3,4
scp -r spark-env.sh/ root@node2:`pwd`
scp -r spark-env.sh/ root@node3:`pwd`
scp -r spark-env.sh/ root@node4:`pwd`
scp -r slaves root@node2:`pwd`
scp -r slaves root@node3:`pwd`
scp -r slaves root@node4:`pwd`
在node1的 sbin 中启动集群 ./start-all.sh
在 node2 的sbin中启动 ./start-master.sh
访问 http://node1:8080 http://node2:8080
可以观察到node1的状态为alive 而 node2的状态是standby
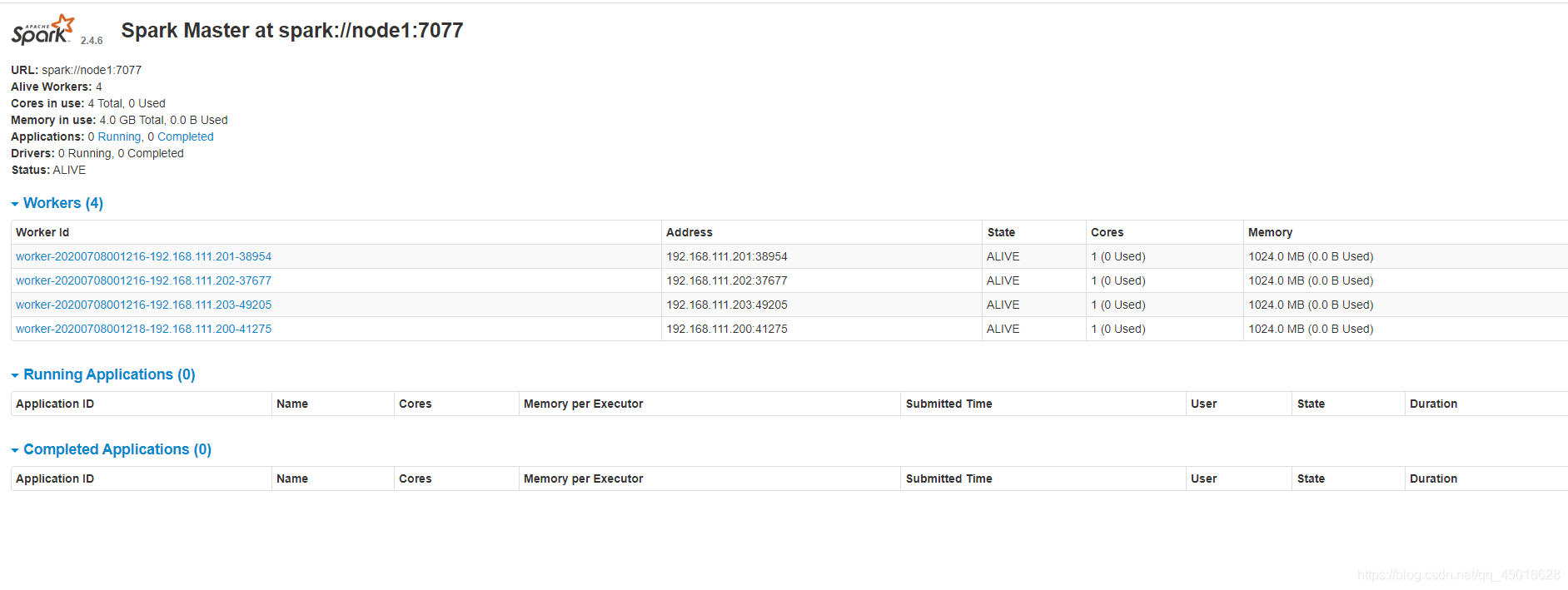
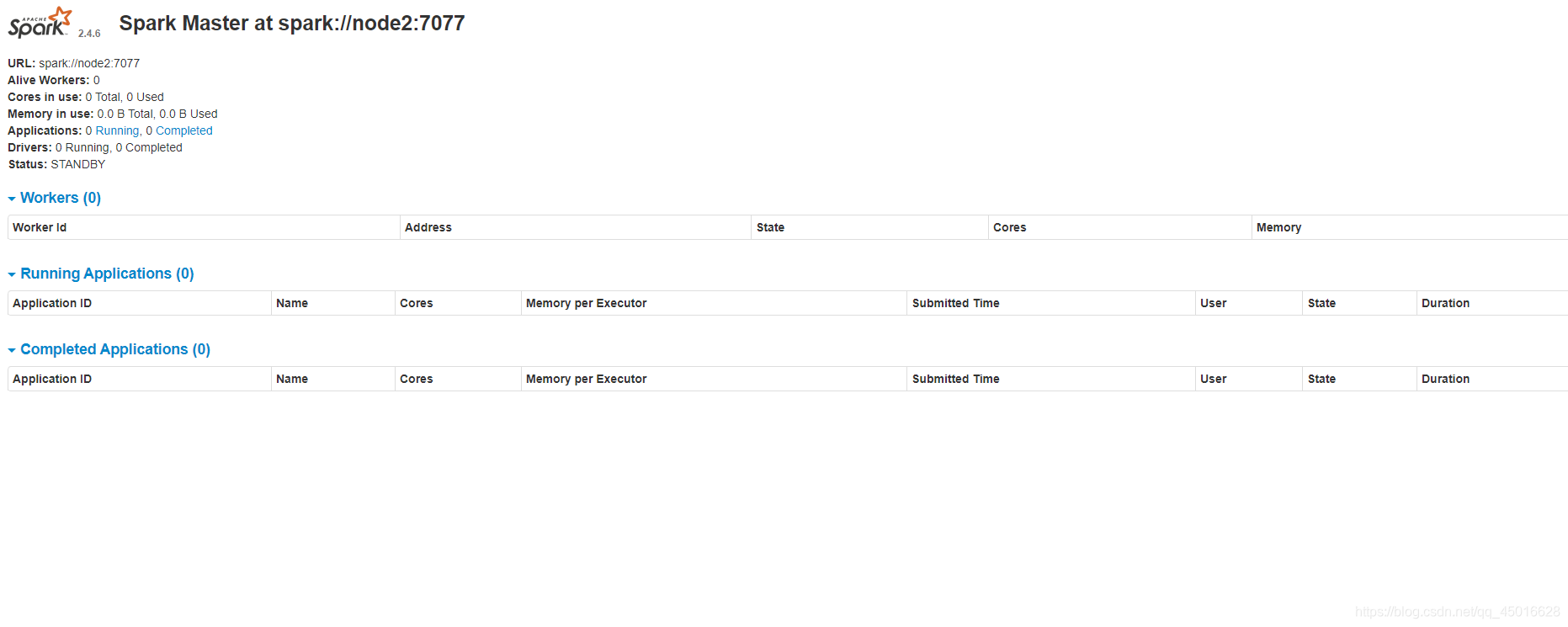
为了确保是否能正常运行 结合 hadoop集群完成一个 WordCount练习
hadoop dfs -mkdir /input2
hadoop fs -put /usr/local/hadoop210/README.txt /input2
在spark集群的master节点(现在node1是alive状态)上运行一个 spark-shell
spark-shell --master spark://node1:7077
sc.textFile("hdfs://node1:8020/input2/README.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://node1:8020/out2")
运行成功,得到结果
















 2547
2547











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









