






思路梳理
我们打开网页,可以看到这其中有许多链接,我们可以查看一下网页源代码,可以看到如我们所期盼的一样,这里有许多的链接,我们只需要把链接爬取出来就可以了

我们可以开始编写最主要的请求代码了

我们经过查找可以发现,链接都存储在li标签下面,所以首先我们先来访问一下这个li所有的东西

我们接下来获取这个a标签中的所有href
然后就可以看到我们输出了很多标签
我们继续清理,便可以循环查找出真实地址

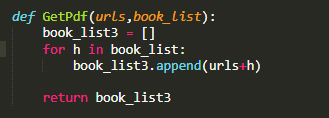
拼接我们所要访问的地址

我们可以看到这个网址已经被输出出来了
封装函数
既然我们已经做好了这个程序,我们就可以把她封装成函数了

我们最后调用这个函数,便可以看到它输出了网址

#Name : GetRJBook-1.py
#Time : 2020-07-15
#Use : Python3.8 Windows10
from bs4 import BeautifulSoup
import requests
import re
def GetWebSite(urls,website_list):
website_list2 = []
for h in website_list:
website_list2.append(urls+h)
return website_list2
def GetTiaoZhuanWebsite(url = "https://bp.pep.com.cn/jc/"):
book = requests.get(url)
book.encoding = "utf-8"
soup = BeautifulSoup(book.text, 'html5lib')#导入模块
address = []
tiaozhuan = []
tiaozhuan2 = []
for i in soup.find_all("a"):
address.append(i["href"])
for h in address:
msg = re.search("http://.*?",h)
if msg == None:
tiaozhuan.append(h)
else:
pass
for j in tiaozhuan:
msg = re.search("./.*?/.*?/",j)
if msg == None:
pass
else:
tiaozhuan2.append(j)
website_list = GetWebSite("https://bp.pep.com.cn/jc/",tiaozhuan2)
return website_list
web = GetTiaoZhuanWebsite()
print(web)
重要提示
如需转载,请附上原文链接
















 518
518











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











