









lucene从4开始大量使用的数据结构是FST(Finite State Transducer)。FST有两个优点:1)空间占用小。通过对词典中单词前缀和后缀的重复利用,压缩了存储空间;2)查询速度快。O(len(str))的查询时间复杂度。
下面简单描述下FST的构造过程。我们对“cat”、 “deep”、 “do”、 “dog” 、“dogs”这5个单词进行插入构建FST(注:必须已排序)。
1)插入“cat”
插入cat,每个字母形成一条边,其中t边指向终点。

2)插入“deep”
与前一个单词“cat”进行最大前缀匹配,发现没有匹配则直接插入,P边指向终点。
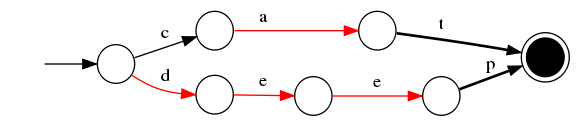
3)插入“do”
与前一个单词“deep”进行最大前缀匹配,发现是d,则在d边后增加新边o,o边指向终点。
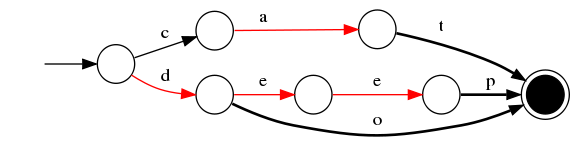
4)插入“dog”
与前一个单词“do”进行最大前缀匹配,发现是do,则在o边后增加新边g,g边指向终点。
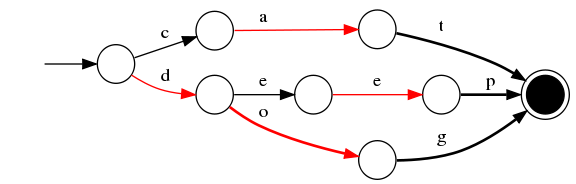
5)插入“dogs”
与前一个单词“dog”进行最大前缀匹配,发现是dog,则在g后增加新边s,s边指向终点。
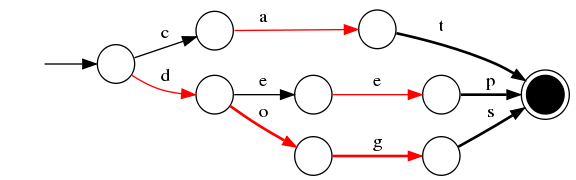
最终我们得到了如上一个有向无环图。利用该结构可以很方便的进行查询,如给定一个term “dog”,我们可以通过上述结构很方便的查询存不存在,甚至我们在构建过程中可以将单词与某一数字、单词进行关联,从而实现key-value的映射。
















 3439
3439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











