







目录
不想用leaf的web模式;但又想用号段模式+本地api方式直接调用,是否可行?
目前业界有哪些唯一ID的生成方式了?
大概有5种。如下图

UUID模式
uuid全称是通用唯一识别码(Universally Unique Identifier)。底层是通过mac地址+时间+随机数进行生成的128位的二进制,转换为16进制字符串后,长度为32位。
uuid的生成非常简单, 如果用java代码生成,那只需要一行代码
public static void main(String[] args) {
String uuid = UUID.randomUUID().toString().replaceAll("-","");
System.out.println(uuid); }
「优点:」 uuid生成的ID 能满足唯一性;并且不依赖任何中间件;生成速度超快。
「但是uuid的缺点也很明显:」 「生成的ID太长了,字符长度有32位」
在业务系统里,一般ID是要进行存储到库里的,并且很有可能会作为常用的查询条件,比如存储到mysql,比int32的4字节或者int64的8字节来讲,太占空间;
「第二个缺点:就是生成的ID是无序的,不是递增的」;这样在把ID做为索引字段,在底层插入索引时,还会引起索引节点的分裂,影响插入速度。所以用UUID生成的ID,对数据库来说很不友好
「那么UUID是不是就没有业务使用场景了?」
并不是的,像很多大厂的日志链路追踪的ID,就是基于UUID进行生成的。
redis 自增模式
大家都知道 在redis里有一个INCR命令,能从0到Long.maxValue-1进行单一连续的自增,最大19位;9位数字就是亿基本的数了,还剩10位,假设每天1千W的订单数据,即1千W个ID,能支持25亿年;距离地球毁灭时间还差点
redis id的自增代码也很简单,不详述。
「优点:」
redis 自增生成的ID 「能满足唯一性」,「也能满足单调自增性」。做底层数据存储或者索引的时候,对数据库也很友好。生成速度还飞快,因为都是在内存中生成。
「缺点:」
「redis 自增ID的缺点也很明显可能会丢数据」我们知道redis是一个kv内存数据库,虽提供了异步复制数据+哨兵模式 来保证服务的高可用+数据高可靠;但redis不保证不丢数据,即使从库变为主库,但也不保证之前的从库数据是最新的,毕竟是异步同步数据。
建议中大厂,或者能稳定运维redis和具有高可用方案+失败重试方案的厂子使用;小厂慎用吧。
数据库自增模式
在早些年,确实看到过依靠数据库自增的方式,进行唯一ID的生成。此种方式主要是依赖数据库的自增来实现;想要一个唯一的ID,那么往带有自增主键的表里插入一条数据吧,这样sql返回的时候,就会把自增ID返回来了
具体sql
INSERT INTO your_table (column1, column2) VALUES ('value1', 'value2'); SELECT LAST_INSERT_ID();
「优点:」数据库自增生成的ID 「能满足唯一性」,「也基本能满足自增性」
「缺点:」
「生成速度较慢」。
受限于数据库的实现方式,,ID生成速度相较于前两者至少慢一个数量级,毕竟在生成的时候数据库有磁盘IO操作;高并发下,不建议使用此种方式。而且每次要获得一个ID,还需要往数据库里先插入一条记录。本来高并发下,数据库操作就是个瓶颈了,用了此种方式还加剧了数据库的负担。
数据库号段模式
数据库号段模式,可以看做是数据库自增模式的升级版,在数据库自增模式上进行了性能优化,解决了ID生成慢的问题。「思路入下图:」

数据库自增模式,每次获取一个ID,都需要操作一次库,太慢了。号段模式每次操作数据库是申请一个号段的范围。比如操作一次数据库,申请1000到2000是这个应用的业务申请的号段;然后只能这个应用实例的业务能用;应用申请了号段后放到内存中,每次业务需要的时候,从内存里累加1返回,在java里也有现成的工具,比如AtomicLong包装下(省事还能解决并发问题);如果发现快不够了,还能异步提前从数据库中申请,放入内存中,这样就避免了业务需要唯一ID的时候,在去数据库申请,加快业务获取ID的速度。
「优点:」
能满足唯一性,也能满足自增性,性能也不差,美团开源的leaf使用此种模式,速度能到 5W/秒。
「缺点:」
对数据库是强依赖;但我想大多数业务系统基本都依赖数据库吧
个人认为此方案最适合小厂;性能不差,而且也不需要依赖太多的中间件;而且大厂里也不缺乏使用此方案身影,比如滴滴开源的Tinyid也是用的此模式
雪花算法模式
雪花算法(Snowflake)出自大名鼎鼎的twitter公司之手;是的就是那个被硅谷钢铁侠 马斯克收购的公司。该算法开源后,深受国内大厂好评。并且像百度这种大厂,基于雪花算法思想,开发了自己开源的 UidGenerator 分布式ID生成器。
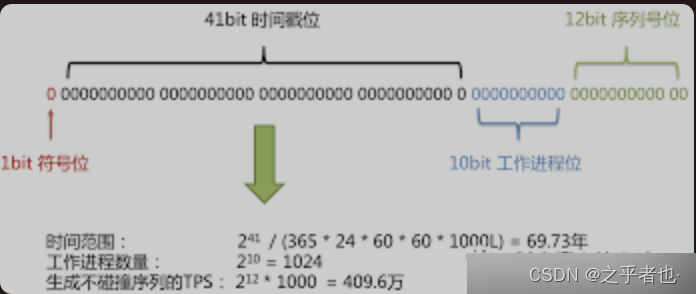
Snowflake生成的是Long类型的ID,我们知道一个Long类型占8个字节空间,1个字节又占8比特,也就是说一个Long类型会用88 64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特。
-
第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0。
-
时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年 (如果你建设的IT系统要使用100年,慎用此法)
-
工作机器id(10bit):也被叫做workId,这个可以灵活配置,机房或者机器号组合都可以。
-
序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成4096个ID
「优点:」
* 雪花算法生成的ID,能保证唯一性;
* 随这时间齿轮的流转,也能满足自增性;有大厂的背书,生成速度也是超快;
* 对第三方中间件也是弱依赖
「缺点:」
-
存在时钟回拨问题,所有机器时钟必须保存同步,否则会导致生成重复ID;但是也能解决
-
生成的数字会随这时间的流逝增大,不会因为数据量的增大而增大,在某些业务场景不太适用
-
需要维护机器ID的配置;或者依赖第三方中间件根据机器信息,生成机器ID
这么多的分布式唯一id生成方法,我该选择哪一种?
为了方便选择,列了个表。到底我的应用里,该选哪个方案了?还需结合自身业务,团队大小,技术实力,实现复杂度和维护难易度进行选择。

想偷懒,有现成的唯一ID生成工具吗?
有的,像比如美团开源的leaf 能支持数据库号段和雪花模式,传输门:https://github.com/Meituan-Dianping/Leaf
百度的 UidGenerator 使用的是雪花模式,传输门:https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md#uidgenerator
而滴滴的 Tinyid 使用的是号段模式,可以认为是基于美团leaf的开源版,传输门:https://github.com/didi/tinyid/wiki
请注意:以上三个工具都是用java语言写的,用java语言的同学有福了,基本是开箱即用。
集成美团leaf 号段模式
1、从git上 https://github.com/Meituan-Dianping/Leaf 下载 leaf源码
2、mvn clean install -DskipTests 编译打包工程
3、用工程里的script脚本目录下的sql 脚本,创建数据表
CREATE DATABASE leaf
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
4、在leaf-server工程里配置数据库连接信息
5、启动leaf-server工程,访问 浏览器访问 http://localhost:8080/api/segment/get/leaf-segment-test即可。
注意:这里的leaf-segment-test即时bizTag。如果想要换成其它业务标,往leaf_alloc插入一条数据即可。
不想用leaf的web模式;但又想用号段模式+本地api方式直接调用,是否可行?
可行的。只需要引入美团的leaf-core jar包即可。是的,这么好的工具,居然没有maven信息;不死心的我,去maven官方仓库搜了一把,还真发现了leaf-core的坐标。如下:
<dependency>
<groupId>com.tencent.devops.leaf</groupId>
<artifactId>leaf-core</artifactId>
<version>1.0.2-RELEASE</version>
</dependency>
但是下载下来后,包名居然是腾讯的包名。反编译后,发现代码基本上没怎么变。如果想偷懒,可直接下载。
为了保险起间,我还是用了美团的leaf-core(只好做本地jar依赖)。然后在代码里加入对ID生成器的初始化。代码如下:
@Service
public class LeafIdDBSegmentImpl implements InitializingBean {
IDGen idGen;
DruidDataSource dataSource;
@Override
public void afterPropertiesSet() throws Exception {
Properties properties = PropertyFactory.getProperties();
// Config dataSource
dataSource = new DruidDataSource();
dataSource.setUrl(properties.getProperty("leaf.jdbc.url"));
dataSource.setUsername(properties.getProperty("leaf.jdbc.username"));
dataSource.setPassword(properties.getProperty("leaf.jdbc.password"));
dataSource.init();
// Config Dao
IDAllocDao dao = new IDAllocDaoImpl(dataSource);
// Config ID Gen
idGen = new SegmentIDGenImpl();
((SegmentIDGenImpl) idGen).setDao(dao);
idGen.init();
}
public Long getId(String key){
Result result = idGen.get(key);
if (result.getStatus().equals(Status.EXCEPTION)) {
throw BizException.createBizException(BizErrorCode.LEAF_CREATE_ERROR_REQUIRED);
}
return result.getId();
}
}
该代码主要做了几件事:
1、在该单列类,实例化后,会进行 数据库源的初始化工作,并且自行实例化IDAllocDao;当然你可以把工程里已有的数据源赋给IDAllocDaoImpl
2、获取ID时,调用底层idGen.get获取
3、业务代码使用时 用 LeafIdDBSegmentImpl.get方法 传入数据库里事先配置好的bizTag即可。
















 1224
1224











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











