







目录
Hadoop运行模式——本地运行
1、Hadoop官网
1)登录官网
https://hadoop.apache.org/
2)Geting start 从这里开始
https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html
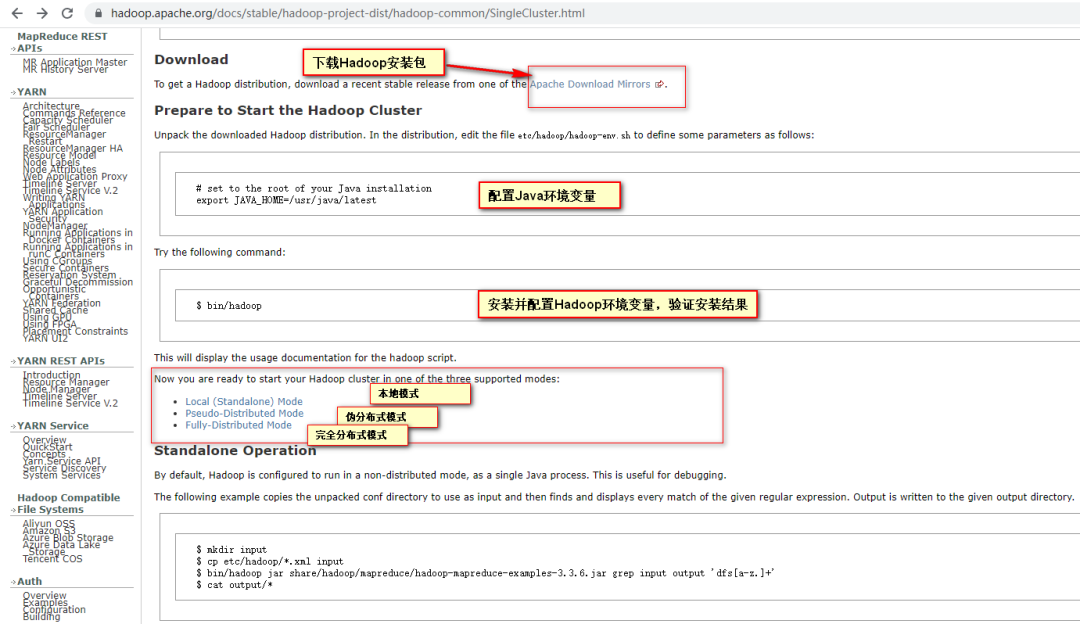
2、Hadoop运行模式
Hadoop运行模式分为3种:本地模式、 伪分布式模式 以及 完全分布式模式
1)本地模式
单机运行,数据存储在 Linux 服务器本地,由 Linux 操作系统来管理存储的数据,用来演示官方案例。
应用场景:生产环境不用,偶尔用作测试环境,简单做个测试
2)伪分布式模式
单机运行,数据存储在 HDFS ,由 Hadoop 的 HDFS 组件自己来管理存储的数据,具备Hadoop集群所有功能,1台服务器模拟1个分布式的环境。
应用场景:生产环境不用,节约成本时用来作测试环境
3)完全分布式模式
多台服务器运行组成1个分布式环境,数据存储在 HDFS ,由 Hadoop的多台服务器部署的 HDFS 组件共同来管理存储的数据。
应用场景:生产环境使用,企业中大量部署,用于生产环境的使用
3、Hadoop本地运行模式
1)演示官方 Grep 案例
Grep案例:其实是从大量文件中找到符合匹配规则的数据以及个数
(1)在 Hadoop 安装目录 /opt/module/hadoop-3.1.3/ 下面创建 input 文件夹
cd /opt/module/hadoop-3.1.3mkdir -v input
(2)将 Hadoop 安装目录配置文件目录 /opt/module/hadoop-3.1.3/etc/hadoop/ 下的 xml 配置文件复制到 input
cd /opt/module/hadoop-3.1.3cp /opt/module/hadoop-3.1.3/etc/hadoop/*.xml input
(3)执行 /opt/module/hadoop-3.1.3/share/ 目录下的 MapReduce 程序
cd /opt/module/hadoop-3.1.3bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep input output 'dfs[a-z.]+'#bin/hadoop 也可以直接用 hadoop 因为配置了环境变量#hadoop后面指明执行一个 jar包【 jar 】#jar后面指明 jar包的位置【 share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar 】#hadoop-mapreduce-examples-3.1.3.jar是个示例集,指明具体是哪1个示例【 grep 】,具体要做什么动作#'dfs[a-z.]+' 匹配的正则规则
(4)查看输出结果
cd /opt/module/hadoop-3.1.3cat /opt/module/hadoop-3.1.3/output/*ll /opt/module/hadoop-3.1.3/output/cat /opt/module/hadoop-3.1.3/output/part-r-00000
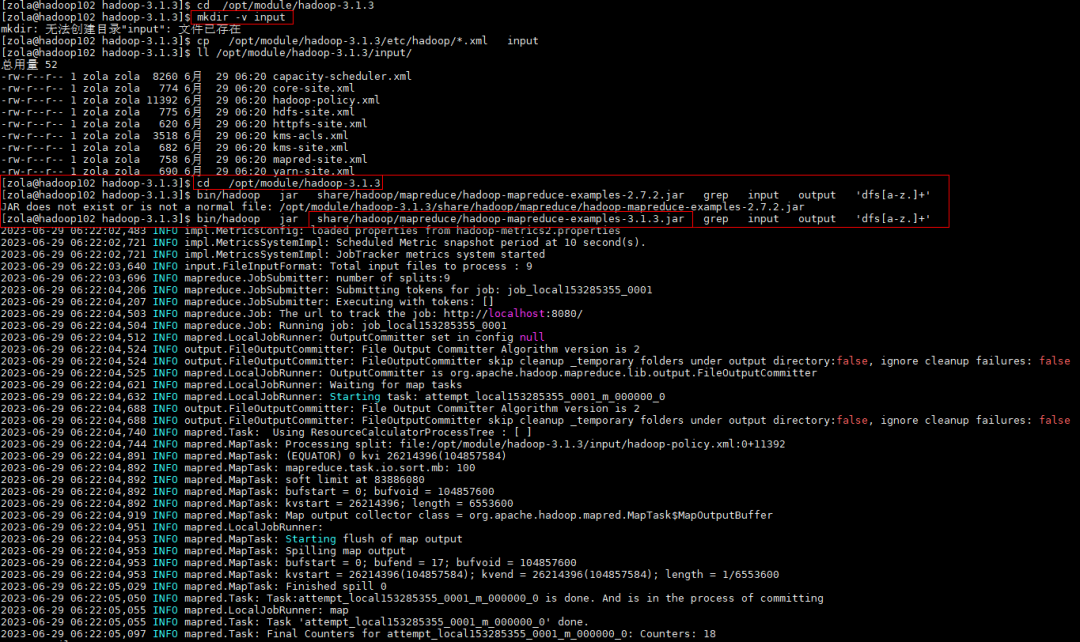
最后执行输出的结果会在这个文件里 part-r-00000 ,另外 _SUCCESS 这个文件只是一个标记文件,标记任务执行结果成功与否
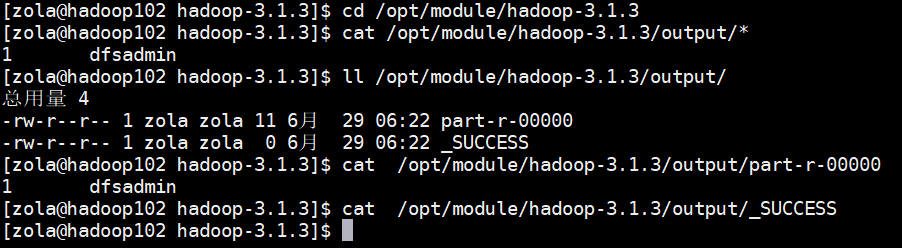
最后,得出结果从上述一堆配置文件中查到了一个满足正则的数据dfsadmin ,出现过1次
2)演示官方 WordCount 案例
WordCount案例:其实是从大量文档中统计单词出现的频率次数
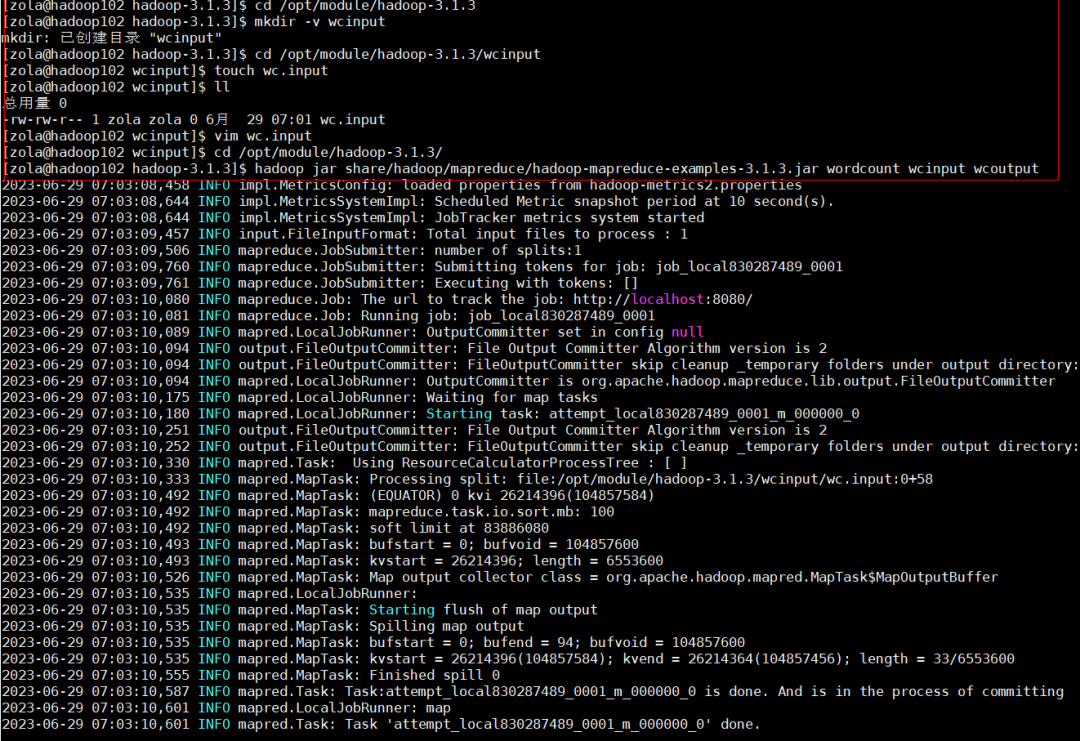
(1)在 Hadoop 安装目录 /opt/module/hadoop-3.1.3/ 下面创建 wcinput 文件夹
cd /opt/module/hadoop-3.1.3mkdir -v wcinput
(2)将 Hadoop 安装目录 /opt/module/hadoop-3.1.3/wcinput 下创建一个 wc.input 文件
cd /opt/module/hadoop-3.1.3/wcinputtouch wc.inputll
(3)编辑 wc.input 文件
vim wc.input#在文件中输入如下内容hadoop yarnhadoop mapreduce月亮 zola zola zola月亮#保存退出:wq
(4)执行 /opt/module/hadoop-3.1.3/share/ 目录下的 MapReduce 程序
cd /opt/module/hadoop-3.1.3/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput#可以直接用 hadoop 因为配置了环境变量#hadoop后面指明执行一个 jar包【 jar 】#jar后面指明 jar包的位置【 share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar 】#hadoop-mapreduce-examples-3.1.3.jar是个示例集,指明具体是哪1个示例【 wordcount 】,具体要做什么动作#mapreduce相关的程序指令,必须要指定对应的 输入路径【 wcinput 】 和 输出路径【 wcoutput 】,注意输出路径 不能存在,存在会报错!!!
( 5 )查看输出结果
cd /opt/module/hadoop-3.1.3cat /opt/module/hadoop-3.1.3/wcoutput/*cat /opt/module/hadoop-3.1.3/wcoutput/part-r-00000cat /opt/module/hadoop-3.1.3/wcoutput/_SUCCESS
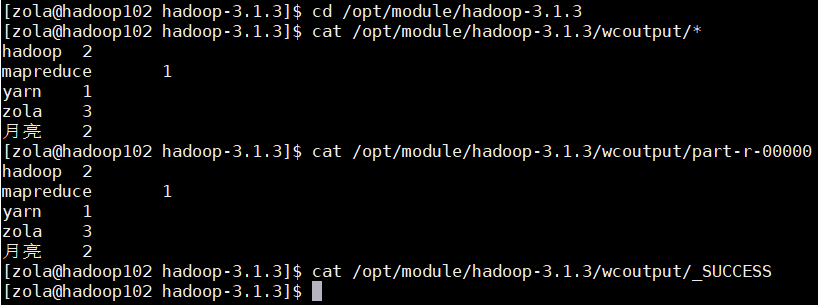
最后,得出结果从 输入文件 中统计单词出现的次数
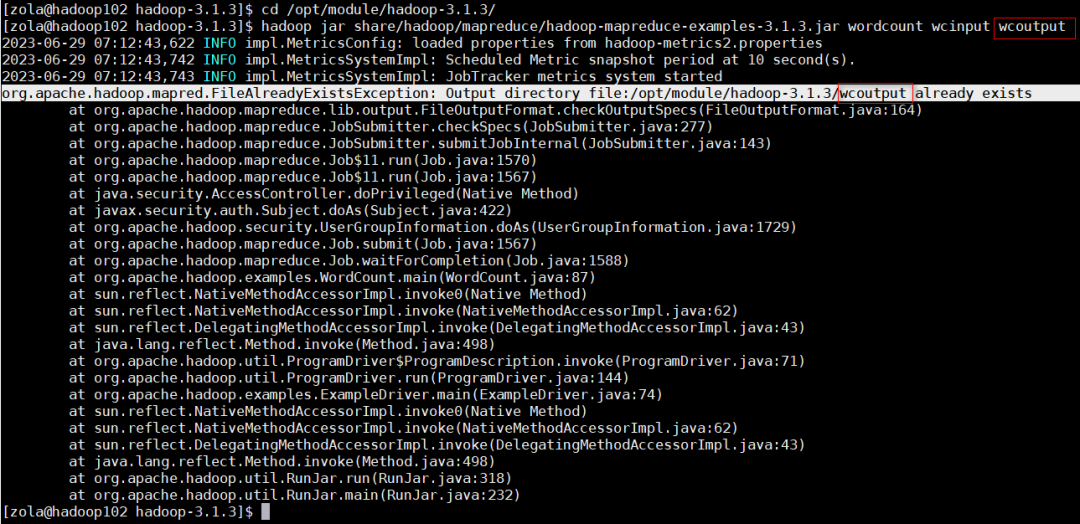
3)演示输出路径存在时报错案例
cd /opt/module/hadoop-3.1.3/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput
报错:这里是因为输出目录已经存在所以报错,抛异常
org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/opt/module/hadoop-3.1.3/wcoutput already exists
















 1256
1256











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











