






语音增强数据集总结
2024年10月10日 更新数据集EARS,发布于2024 interspeech
语音增强的第一步一般是准备数据,包含带噪语音和纯净语音。一般这些数据都是人工合成的,以纯净语音和噪声数据为基础即可合出带噪语音信号。以下介绍一些语音增强领域常用的数据集。
纯净语音
AVSpeech
16kHz,由谷歌发布
干净语音,用于语音分离任务。音视频数据集(Audio-Visual Dataset)。
每条数据长度在3~10s,共计4700h,包括不同人种、不同语言和不同表情姿态的150,000个说话人。每条数据 > 只出现一个说话人的面部和声音
数据分布如下图:
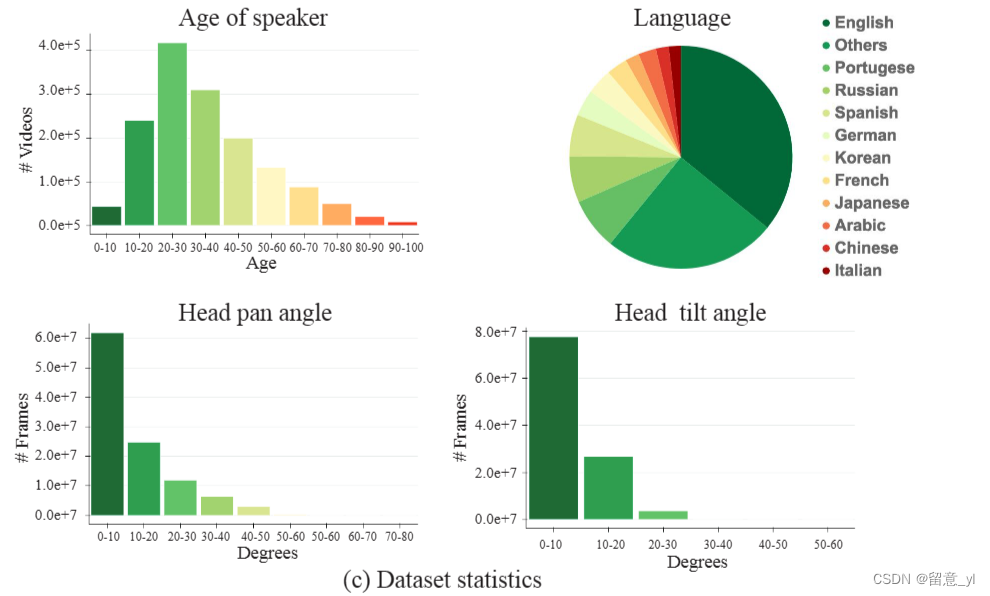
原文:Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation
网页:https://looking-to-listen.github.io/avspeech/
github:http://looking-to-listen.github.io/
Common Voice(2019首次发布,至今一直在更新)
48kHz,16bit,MP3格式 截至2023/7/21,
该数据集包括112种语言的28118小时语音,可用于训练的数据共18652小时。具体分布可看官网。
论文:https://arxiv.org/abs/1912.06670
官网链接:https://commonvoice.mozilla.org/en/languages
因为数据集一直在更新,所以建议直接去官网看。
Multi Lingual Speech(MLS) (2020)
源自LibriVox有声读物的数据集 16kHz,8种语言。
44.6k小时的英语数据,以及总计6k左右的其他7种语言的数据
具体分布如下:
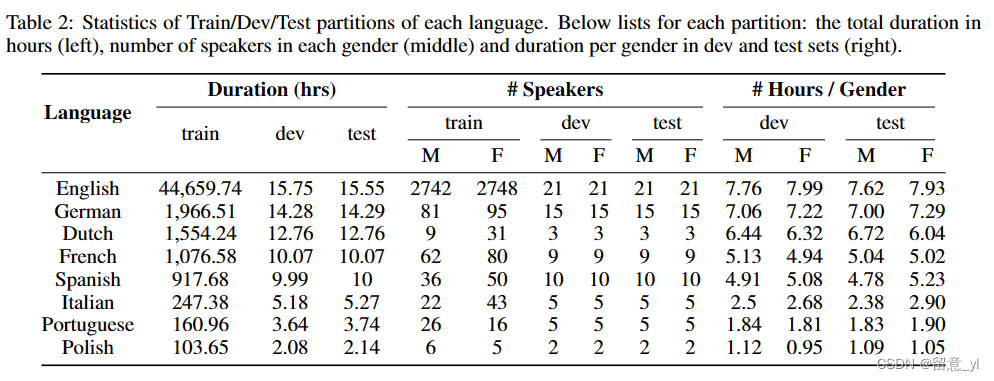
论文:https://arxiv.org/abs/2012.03411
链接:http://www.openslr.org/94/
DidiSpeech(2021)
普通话,由滴滴出行发布 共800小时,6000个说话人,采样率48kHz,位深度16 bit。
性别、地域分布和录音设备(IOS/Andorid)比例基本接近1:1。年龄分布为adults(>=20): youths(13-19): children(<13) = 5:3:2。
包括两个子集DidiSpeech-1和DidiSpeech-2。DidiSpeech-1对标VC(Voice Conversion)任务,包括4500个说话人,共572h,每个说话人的录音有50 parallel sentences(平行语句,每个说话人都说的相同的句子)和50 non-parallel sentences(不被重复的、每个人不同的内容)。
DidiSpeech-2对标multi-speaker speech synthesis 和 ASR任务,共227h,1500个说话人,没个说话人读>100句 non-parallel sentences。
原文链接:https://ieeexplore.ieee.org/document/9414423
数据地址:https://outreach.didichuxing.com/research/opendata/
VCTK(2019)(又名Voice Bank)
英语,由爱丁堡大学发布 共44小时(数据来源网络),
共110个英语说话人,包含不同的口音,每个说话人读约400个句子,采样率48kHz,位深度16bit。
官方文档及数据下载地址:https://datashare.ed.ac.uk/handle/10283/3443
AiShell
中文,北京希尔贝壳科技 AiShell-1(2017) 共178小时,400个来自中国不同地区的说话人,采样率为16kHz,位深度16bit。
AiShell-3(2020)
共85小时,218个说话人,共88035条语音,采样率为44.1kHz,位深度16bit。说话人分布偏向女性,年龄分布集中在20岁左右。
详情见官方介绍:https://www.aishelltech.com/kysjcp
LibriSpeech
英语 2015 共1000小时,16kHz采样率,接近US English,derive from LibriVox
具体分为如下子集:
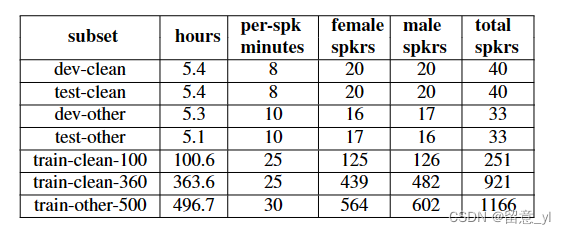
基于WSJ语料库训练出的ASR模型评测每个说话人的WER,WER更低的 speaker被分为clean,WER更高的分为other。
论文:Librispeech: An ASR corpus based on public domain audio books
链接:http://www.openslr.org/12/
TIMIT
英语,由TI(Texas Instruments)、MIT(Massachusetts Institute of Technology)和SRI (Stanford Research Institute)共同收集语料库,也是其名字的由来。
16kHz,共6300个句子,由来自美国8个主要方言区的630人每人读10个句子,10个句子中包括2个方言句、5个phonetically-compact sentences(发音紧凑的句子)和3个phonetically-diverse sentences (语音多样的句子),
具体分布如下表:
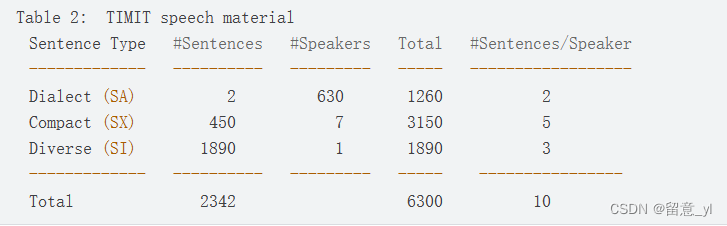
其完整测试集占据整个数据材料的27%,共168个说话人、1344条语句。
论文:https://www.researchgate.net/publication/243787812_TIMIT_Acoustic-phonetic_Continuous_Speech_Corpus
链接:https://www.kaggle.com/datasets/mfekadu/darpa-timit-acousticphonetic-continuous-speech
噪声
AudioSet
WHAM!(2019)
16kHz,32bit,双通道、平均时长10s,最短3.5秒,最长47.7秒。
数据集全称为WSJ0 Hipster Ambient Mixtures。 这些噪声录制于旧金山湾区的咖啡馆、餐厅、酒吧、办公楼、公园等城市环境中
分布如下:
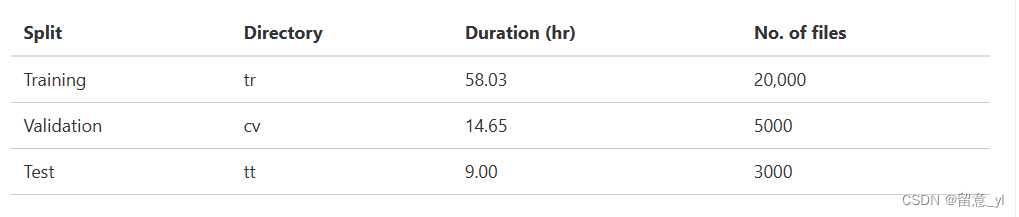
原文:WHAM!: Extending Speech Separation to Noisy Environments
链接:http://www.shujujishi.com/dataset/ae73e948-46d8-4e19-aef3-47a7baa044ab.html
DEMAND
16通道 48kHz 六中大环境下的真实噪声
具体分布如下
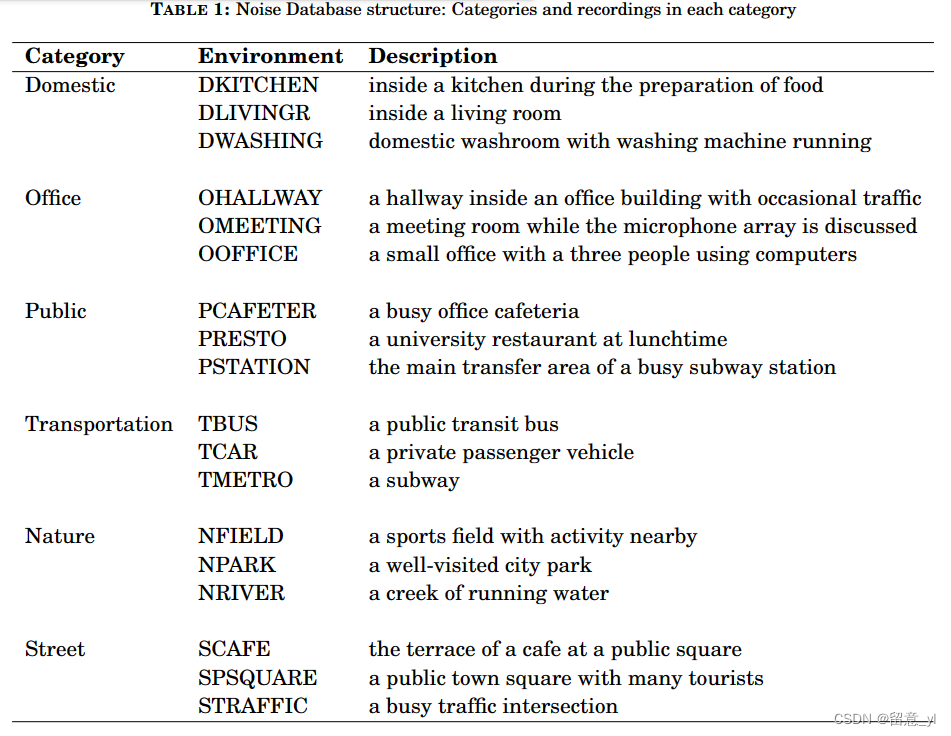
FSD50K(2021)
44.1kHz, 16it
用于声音事件检测任务,有200种噪声种类,51197条音频文件,主要包括人声、动物声音、自然界的声音、音乐和事物的声音,共108小时。
分布如下:
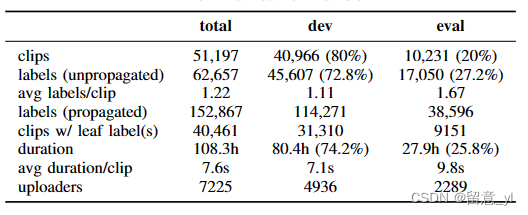
论文:FSD50K: An Open Dataset of Human-Labeled Sound Events
链接:https://annotator.freesound.org/fsd/release/FSD50K/
https://zenodo.org/record/4060432
Noise-92
19.98kHz,16bit,
每条音频时长为235秒 包含15种噪声类型:白噪声、粉红噪声、餐厅内嘈杂说话声、2种工厂噪声、3种驾驶舱噪声、机舱噪声、控制室噪声、两种军车噪声、枪声、车辆内部噪声和高频通道噪声
链接:http://spib.linse.ufsc.br/noise.html
AudioSet
用于音频事件识别的数据集,取自Youtube video。包含1789621条(178万)10s音频,共计4971小时。其中训练集为1771873条,评估集为17748条。包含632种声音事件,其中有485类声音事件包含至少100个实例。
包含六大类声音事件:Human Sounds, Animal Sounds, Natural Sounds, Music, Sound of Things, Source-ambiguous Sounds, Channel environment and background。
本文偏向语音增强领域的应用,因此具体细节不再赘述,请参考原论文。
链接:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7952261
已经合好的公开语音增强数据集
EARS
英语,48kHz,32bit
作者收集了干净语音数据集EARS,并构建了EARS-WHAM和EARS-Reverb分别用于语音增强和解混响任务
EARS
100h干净无回声数据, 107个说话人,每人语音接近1小时,其中有18分钟自由独白;
演讲者来自不同种族,年龄范围为18-75岁;数据集共包含7种不同阅读风格,22种情绪,具体请见原论文。
数据集划分: 训练集说话人p001 ~ p099 , 验证集:p100 and p101, 测试集:p102 to p107
EARS-WHAM
将EARS的语音和WHAM!的真实噪声混合,在[−2.5, 17.5] dB 范围内随机采样的信噪比得到带噪语音
除原来的测试集外,额外创建了新的盲测集,包含6个说话人,3男3女,743条语音共2小时
EARS-Reverb
使用来自多个公共数据集的真实记录的房间脉冲响应(RIR)[16,17,18,19,20,21,22](CC BY 4.0,MIT License)。
论文: https://www.isca-archive.org/interspeech_2024/richter24_interspeech.pdf
官方链接: https://github.com/facebookresearch/ears_dataset
VoiceBank+Demand
英语,爱丁堡大学,48kHz;语音数据来自VCTK,有两个子集:28说话人和56说话人
28说话人
train set: 14female 14male (all England accent)
10种噪声数据,2种人为生成、8种来自Demand,4种信噪比:15,10,5,0dB;因此有10*4=40种不同的噪声。共11572条,9.4h。

test set: 1 female1male (England); 5种噪声数据,全都来自Demand,4种信噪比:17.5, 12.5, 7.5 以及2.5dB,有5*4=20种噪声。共824条,0.6h。

56说话人
28female 28male (Scotland and United States)
论文:Speech Enhancement for a Noise-Robust Text-to-Speech Synthesis System
using Deep Recurrent Neural Networks
官方链接:Noisy speech database for training speech enhancement algorithms and TTS models
NISQA
发布于Quality and Usability Lab, Technische Universit ̈at Berlin、Deutsches Forschungszentrum f ̈ur K ̈unstliche Intelligenz (DFKI),Berlin, Germany
同时拥有合成的和真实的带噪语音 train和validation set都有人工标注的MOS评分
2个training dataset: NISQA_TRAIN_SIM 10,000 samples from 2,322 speakers; NISQA TRAIN LIVE 1,020 samples from 486 speaker speaker;
2个validation dataset: NISQA VAL SIM (2,500 samples from 938 speaker);NISQA VAL LIVE (200 samples from 102 speakers)
4个test set: NISQA TEST P501(240 samples from 4 speakers 男女各半), NISQA TEST FOR(240 samples from 8 speakers,男女各半), NISQA TEST NSC(240 samples from 240 speakers),NISQA TEST LIVETALK wit(232 samples from 8 speakers,男女各半)
论文:https://arxiv.org/abs/2104.09494
链接:https://github.com/gabrielmittag/NISQA/wiki/NISQA-Corpus
NOISEX-92
16kHz,16bit,数据需要空间1.4G;
语音部分来自ESPRIT SAM EUROM_0,共一男一女两个说话人,每人读两张一百个独立数字组成的表,一张用于训练一张用于测试,每人还有两张50个三位数组成的表,同样分别作为训练和测试,噪声部分来自RSG.10 NOISE-ROM-0,从中选择了8种噪声。
具体分布如下:

最终音频信噪比为18,12,6,0,-6dB.
真实带噪语音
REAL-M(2021)
8kHz
文本来自LibriSpeech,提供给每一对说话者,房间里的说话人同时阅读句子,共收集了1436个mixture;另外有144个mixture的其中一个说话人语音是通过视频会议软件录制的;这增加了数据集的多样性和应用场景。
论文:https://arxiv.org/abs/2110.10812
链接:https://sourceseparationresearch.com/static/REAL-M-v0.1.0.tar.gz
DAPS(2014)
该数据集有真实的带噪语音,并且提供了答案。收集方法为:现在安静环境下录干净语音,然后在特定噪声环境下经这段语音用扬声器放出来,和噪声一起录下来,作为带噪语音。
20 speakers, 每个说话人有5段脚本大概14 minutes的语音,采样率44.1kHz
论文:Can we Automatically Transform Speech Recorded on Common Consumer Devices in Real-World Environments into Professional Production Quality Speech?—A Dataset, Insights, and Challenges
链接:https://ccrma.stanford.edu/~gautham/Site/daps.html
其他
MUSAN(2015)
约翰斯霍普金斯大学语言语音处理中心
包括语音、音乐和噪声三种数据集,109小时,16kHz
Speech:约60h,其中20h21m来自Librivox, 40h1m来自美国政府公开的听证会、委员会和辩论等
Music:42h31m,分为popular genres和Western art music
Noise:约6小时,共929条音频文件,来自Free Sound和Sound Bible
论文:MUSAN: A Music, Speech, and Noise Corpus
链接:http://www.openslr.org/17/
BABEL(2011-)
BABEL计划收集的数据集,该计划的目标是开发可应用与任何人类语言的语音技术,目前包含爪哇语、粤语、蒙古语、Dholuo、阿姆哈拉语、瓜拉尼、Igbo Language, Lithuanian Language, Cebuano Language, Kazakh Language, TokPisin Language, Telugu Language, Haitian Creole Language, Kurmanji Kurdish Language, Lao Language, Swahili Language, Tamil Language, Vietnamese Language, Zulu Language, Assamese Language, Bengali Language, Georgian Language, Pashto Language, Tagalog Language, Turkish Language共25种语言
8kHz,通话录音
链接:https://catalog.ldc.upenn.edu/byyear
https://www.iarpa.gov/index.php/research-programs/babel
语音分离
LibriCSS(2020)
16kHz、源自LibriSpeech,面向CSS任务(Continuous Speech Separation)
包含10 sessions,每个session 1小时,LibriCSS共计10小时。
每个session包含6 段10分钟的mini session,每个段mini session 有8个说话人(从LibriSpeech development set的40个说话人中随机选择),OVR (overlap ratio)为0-40%,重叠率为0时,句子间silence为0.1-0.5s的被称为short silence version, 句间silence为2.9-3.0s的则被称为long silence; mini session中的uttrance为52-125不等。
原文:Continuous speech separation: Dataset and analysis
数据:https://github.com/chenzhuo1011/libri_css
LibriMix(2020)
16kHz,语音源自LibriSpeech,噪声来自WHAM! 在训练集中,每个句子只使用一次。
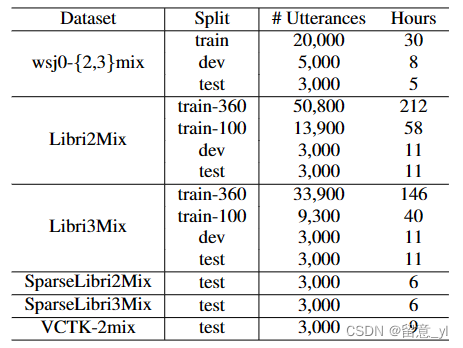
原文:LibriMix: An Open-Source Dataset for Generalizable Speech Separation
参考链接:https://blog.csdn.net/FonFon27/article/details/113834692
AMI(2005)
爱丁堡大学
包含100小时的会议录音,英语。大部分说话人为非母语人士
原文:The AMI meeting corpus
链接:https://groups.inf.ed.ac.uk/ami/corpus/
https://groups.inf.ed.ac.uk/ami/corpus/overview.shtml
个性化语音增强
DNS4-Track2
WSJ0-2mix
AiShell2Mix
Common Voice
最后,这是网上一些其他的数据集整理链接
https://www.cnblogs.com/LXP-Never/p/15474948.html(凌逆战)
https://blog.csdn.net/qq_34637672/article/details/117925485
https://github.com/nanahou/Awesome-Speech-Enhancement
https://zhuanlan.zhihu.com/p/267372288

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









