






 本文介绍了一项由麻省理工学院和美国剑桥大学合作创建的VocalSound数据集,它包含超过21,000个来自全球各地、年龄和性别均衡的语音样本,旨在提升语音识别准确性和研究。数据集特点包括丰富元数据和类别平衡,有助于解决现有数据集在声音样本和标注质量上的不足。
本文介绍了一项由麻省理工学院和美国剑桥大学合作创建的VocalSound数据集,它包含超过21,000个来自全球各地、年龄和性别均衡的语音样本,旨在提升语音识别准确性和研究。数据集特点包括丰富元数据和类别平衡,有助于解决现有数据集在声音样本和标注质量上的不足。
VOCALSOUND: A DATASET FOR IMPROVING HUMAN VOCAL SOUNDS RECOGNITION
第一章 语音增强之《Vocalsound:一个用于提高人类声音识别的数据集》
文章目录
前言
语音新手入门,学习读懂论文。
本文作者机构是麻省理工学院,美国剑桥大学

一、任务
作者引入了VocalSound数据集,该数据集由超过21,000个众包录音组成,包括笑声、叹息、咳嗽、清喉咙、打喷嚏和抽鼻子,这些录音都是通过Amazon Mechanical Turk收集的。VocalSound数据集是分类平衡的,收集了来自60个国家的3365名演讲者,他们的年龄从18岁到80岁不等。
二、动机
人类非言语发声识别是一项重要的任务,在语音自动转录和健康状况监测等方面有着广泛的应用。然而,现有的数据集有相对较少的声音样本或嘈杂的标签。因此,最先进的音频事件分类模型在检测人类声音时可能表现不佳。为了支持建立强大而准确的声音识别研究,作者创建了一个VocalSound数据集。
三、挑战
声音样本数量相对较少,并且受数据采集方案的限制,没有提供说话人的年龄、性别、母语等信息。由于AudioSet数据集对声音词汇量大的YouTube视频进行标注的困难,在数据集中出现了噪声标签问题。
四、方法
1.数据集对比

所提出的VocalSound数据集与之前的工作不同,1)VocalSound数据集是类别平衡的,并且从大量具有合理性别和年龄分布的说话者中收集了更多的声音样本。由于数据采集方案,标签也是可靠的。(2) VocalSound数据集具有丰富的元数据信息,包括说话人的性别、年龄、母语、国家和健康状况,这拓宽了数据集的应用范围,例如,可以使用元数据研究性别、年龄、语言对语音分类模型性能的影响;健康标签可用于构建基于语音的健康分类系统;匿名说话人标签可以潜在地用于建立基于声音的说话人再识别系统等。
2.数据收集
作者通过Amazon Mechanical Turk (AMT)众包VocalSound录音。受试者自愿在AMT上完成我们的人类智能任务(hit),并在hit被我们审查和批准后获得补偿。
HIT由7个子任务组成。首先,我们询问受试者的性别、年龄、国家、母语和健康信息。对于健康状况,我们会问“你今天是否有感冒、过敏或其他可能影响你说话的健康相关症状?”
然后在子任务2-7中,我们要求受试者记录他们自己的笑、叹气、咳嗽、清喉咙、打喷嚏和嗅。我们不会从受试者或录音设备收集个人身份信息,数据收集是匿名的。
3. 数据分布
女性占45%,男性占55%,所以性别平衡。
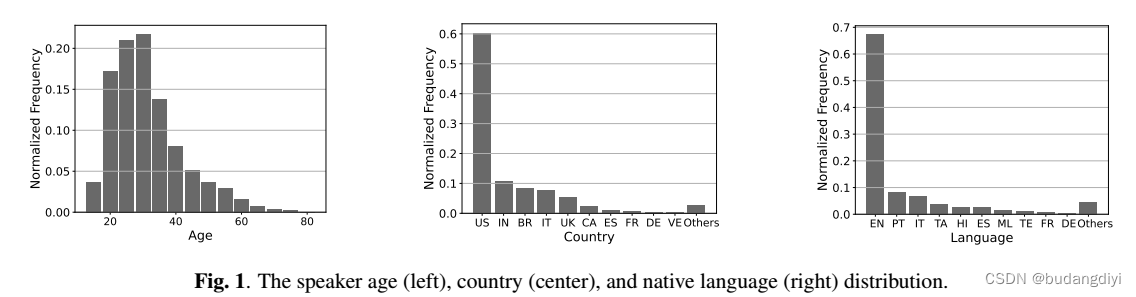
研究对象的年龄在18 - 80岁之间,大多数研究对象的年龄在20 - 40岁之间。然而,仍有321名受试者年龄在50岁以上,这足以评估模型在老年组的表现。
研究对象来自60个国家,其中以美国(60.3%)、印度(10.8%)和巴西(8.3%)为主。英语(67.2%)、葡萄牙语(8.7%)和意大利语(6.8%)是相应的主要母语。
4.0%的受试者报告在数据收集期间出现可能影响其语言的健康相关症状。音频长度的平均值为4.18s,中位数为3.72s,标准差为1.81s。音频以44.1kHz的。wav格式录制。
4.训练模型
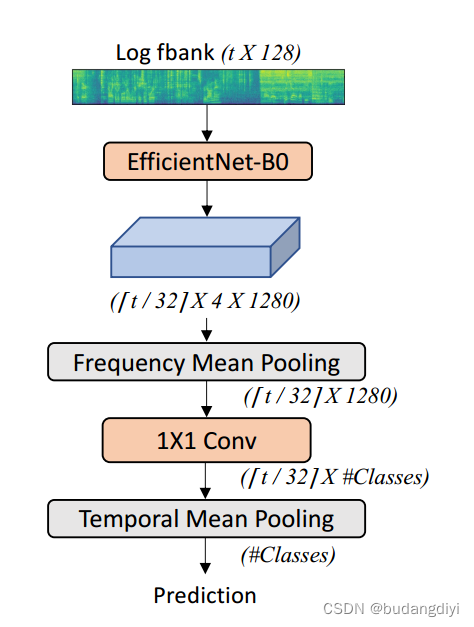
每个音频波形首先转换为128维对数Mel滤波器组(fbank)特征序列,每10ms用25ms汉宁窗口计算。将t×128 fbank特征向量输入到EfficientNet-B0模型中。将时间和频率维度降低了32倍,特征维度为1280。在4个频率维度上应用均值池化来产生一个33×1408表示,该表示被提供给一组具有sigmoid激活函数的1×1卷积滤波器,其中#class是预测类的数量。然后执行时间平均池,为每个类标签生成最终的#class维度输出。
使用Adam优化器[22]训练模型,初始学习率为1e-4,批大小为100,交叉熵损失为50个epoch.
五、实验评价
1.数据集
2.消融实验
3.客观评价
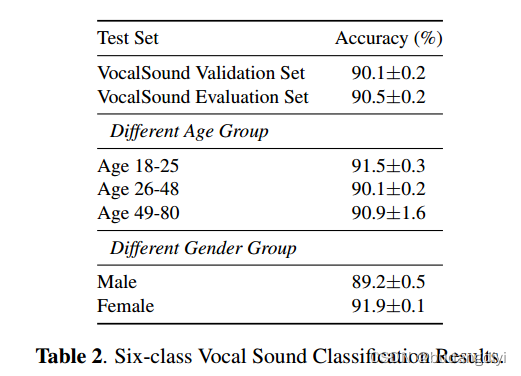
由于VocalSound数据集包含说话人元信息,它可以用来支持未来消除这种模型偏差的研究。
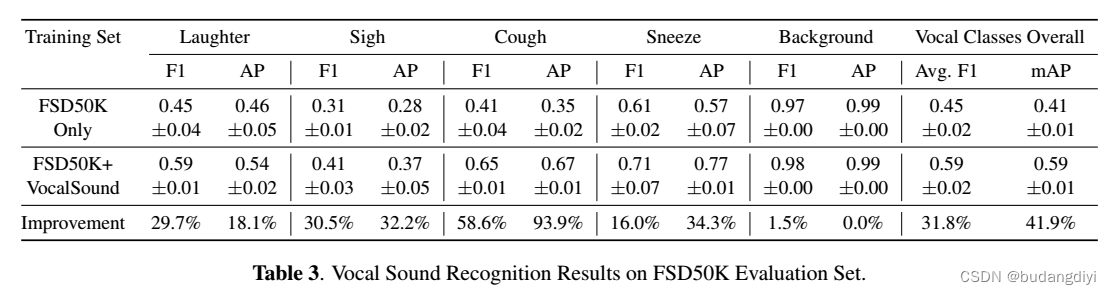
4.主观评价
六、结论
在本文中,我们介绍了VocalSound,这是一个新的数据集,由超过21,000个笑声,叹息,咳嗽,清喉咙,打喷嚏和嗅吸的录音组成。与现有的通用音频事件数据集相比,该数据集具有更多的声音样本和更丰富的说话人信息。我们的实验表明,VocalSound数据集可以显著提高语音识别性能。


















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











