







论文来源:ICASSP2023
标题:SELF-SUPERVISED LEARNING-BASED SOURCE SEPARATION FOR MEETING DATA
作者:Yuang Li, Xianrui Zheng, Philip C. Woodland
机构:Cambridge University Engineering Dept., Trumpington St., Cambridge, CB2 1PZ U.K.
原文链接:SELF-SUPERVISED LEARNING-BASED SOURCE SEPARATION FOR MEETING DATA
摘要:语音分离可以从有重叠语音中提取单个说话人的信号以提升多方会议场景下的语音识别性能。尽管基于自监督学习(SSL)的模型在单通道语音分离上已经取得了很大成功,但他们大部分都是在合成数据上训练的。本文中,我们在模拟和真实数据集上比较了7种SSL模型。其次,我们通过一种新奇的迭代源选择方法将表现最好的SSL模型WavLM嵌入到自动转录系统。为了提升在真实数据上的表现,时域无监督混合不变训练被应用于时频域。实验显示,在转录系统中,在自动语音识别(ASR)模型前出入语音分离(SS)模型并在分离语音上微调ASR模型,在AMI dev和test set上测得的未知数量说话者的级联最小排列字错误率分别有1.9%和1.5%的下降。
关键词:语音分离,自监督学习,自动语音识别
1.引言
在日常对话中,语音的重叠时有发生,语音清晰度的下降为ASR系统带来了很大挑战。为了克服这个问题,源分离技术被用来分出每个单独说话人的信号。早期研究如deep clustering[1]和句级别的置换不变训练(PIT)[2]在时频域进行单通道语音分离,并忽视相位信息、估计单个说话人的幅度谱。最近的时域方法因为可以兼顾对幅度和相位信息的建模而变得受欢迎。从TasNet[3]开始,直接用encoder-decoder的结构预测输出波形,之后又有几种结构[4,5]被提出。目前为止,基于Transformer的模型展现出了最有希望的性能。
监督训练要求单个说话人的信号作为目标,但从真实的重叠信号中获取这些参考信号是很难的,所以一种通用的方法为将多个说话人的片段组合到一起[1]。为了贴近现实,可以添加一些噪声和混响,但合成数据和真实数据间仍然存在mismatch。为了利用真实的重叠语音,研究者提出了无监督训练方法,从预训练的分离模型得到伪标签、或寻找分离源与混合物之间的一致性。Sivaraman等人[12]展示了无监督混合不变训练(MixIT)在AMI数据集上的有效性,但不包括基于ASR的评估集,并且他们更多地关注时域模型而非时频域掩码模型。
SSL通过从大量无标签数据中学习而有利于多种语音下游任务[13]。使用Conformer作为下游模型,WavLM[15]在LibriCSS[16]上获得了SOTA分离性能。Huang [17]等人进一步在LibriMix上比较了13中SSL模型的性能。然而,这些比较仅限于模拟数据。而且,SSL模型被完全frozen,只被用来生成升学表征。
在本文中,我们会彻底分析SSL模型在真实数据源分离任务上的表现。对传统的话语分离任务,我们在LibriMix[18] (R-LibriMix), LibriCSS[16]和AMI[19]上使用基于信号和基于ASR的准则比较了7种SSL模型。SSL模型的的潜力通过两阶段微调机制被充分探索,首先训练轻量级下游模型,其次微调SSL模型。将实验扩展到了真实世界的应用:会议转录系统。为了减轻域间的mismatch,我们用时频域无监督MixIT在真实的重叠数据上引入相位感知掩码(PSM)。分离模型有多个输出,并能基于说话人信息自动选择我们想要的某个输出。为此,提出的源选择方法根据diarisation提供的说话人标签计算并优化speaker embedding。
在本文的剩余部分,第二章回顾一些SSL模型,第三章展示源分离框架,监督和无监督训练方法,以及我们提出的源选择方法。第四章和第五章提供实验配置与结构,第六章总结本文。音频样本公开于
https://sites.google.com/view/ssl-ss/home。
2.语音信号SSL 模型
SSL模型为下游任务提供信息表征,并为后来的微调带来更好的初始化。这些模型可被分为两类:重构原始特征的生成模型和通过聚类或量化生成离散语音表征的判别模型。TERA[20]是一个基于生成任务的自监督Transformer Encoder, 在训练阶段其输入会被随机mask。该模型通过L1损失重构原始谱图进行优化。Wav2Vec2[21]以原始波形作为输入,并在latent space对特征进行mask。它引入了一个以离散隐式特征为训练目标的量化模块。这个模型通过对比学习任务进行训练,这将掩蔽时间步的真实量化特征和一组干扰信号区分开。HuBert[22]采用离线聚簇的方法生成离散标签。该模型估计伪标签的分布,并与被mask的区域计算cross-entropy(交叉熵)损失。UniSpeech-SAT 和WavLM[23,15] 是HuBert的变体,用于促进说话人身份信息的提取。它们共有的特点是使用uttrance mixing augmentation(句混合增强),也就是将主句和随机选取的其他说话人语音片段组合到一起。
3.方法
3.1语音分离使用SSL表征
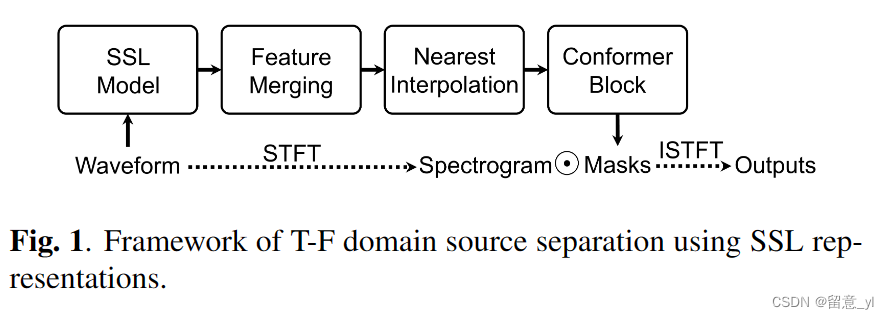
图1展示了基于SSL的语音分离框架。SSL模型处理时域语音波形并生成SSL表征。此后,为了利用多层次信息,对SSL中Transformer每一层出来的特征进行加权融合。然后,Nearest interpolation阶段提升SSL的时域分辨率使其与TF频谱分时序分辨率一致。最后,用一个Conformer Block估计多个TF域的mask,用来恢复被分离信号。Conformer比以前工作中的下游模型[15,17]有更少的参数。注意我们没有使用时域模型,因为SSL特征需要和语谱图有相似的stride, 而时域模型往往有更小的stride。
为了优化分离模型,其标准做法是使用PIT[2],也就是从多种可能的答案中选择损失最小的组合。在本文中,当损失用于合成数据,其计算方式见式(1),它使用了相位感知目标谱[24]。
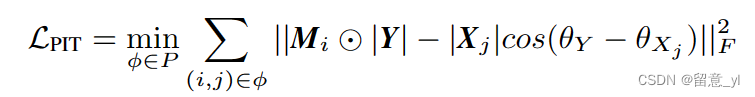
φ表示一种置换;P是所有可能置换的集合;Y是混合语音的T-F域表示;Mi是输出的mask; Xj是目标谱;θY和θxj分别是Y和Xj的相位;||·||F是Frobenius范数。
3.2 时频域混合不变训练(MixIT)
PIT只能在合成数据上使用,而MixIT可以使用真实的混合数据作为标签,这是通过假设输出源可以被重新混合成原始标签实现的。MixIT首先混合多个真实的有重叠信号制造Mixture of mixtures(MOMs)。然后模型以MOMs作为输入,并估计多个输出音频。MixIT遍历地计算每一种混合组合,以其跟源混合音频得到的最小误差作为损失。
原始的MicIT使用在时域语音分离上的,这时输出可以直接把波形样本相加混合得到,但在时频域上,由于相位误差的存在,直接把幅度谱相加是不合适的。因此,MixIT适用于有PSM的的时频域处理,因为时域混合信号等于带相位感知目标的混合信号,所以损失函数采用了和PIT损失类似的式(2)。和(1)的不同在于其预测结果是一个混合信号而非单个信号的语谱。
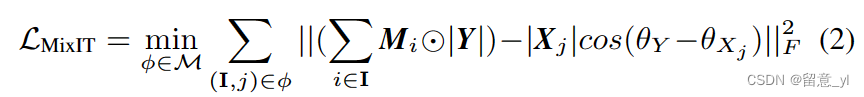
φ是一种混合,M表示所有混合的可能;I是一组会被混合输出流;Y是时频域的MOM;Mi是输出的一个mask,Xj是一个目标语谱;θY和θXj是Y和Xj的相位。
MixIT并不明确地引导模型分离单个说话人的信号作为单个输入,因为这有可能导致over-separation,因此联合PIT和MixIT的半监督会更有效。
3.3 迭代源选择
相比于没有目标说话人的源分离,说话人提取是更有现实意义的任务,它从一组混合信号中估计目标说话人的语音。为了区分目标说话人,通常的做法是使用辅助分支从注册语音中提取speaker embedding(说话人嵌入), 并将其输送给主分离网络[25]。在本文中,说话人提取被分为了源分离和源选择两个阶段。对于源选择,我们假设句子来自提供了说话人标签的日志系统。接下来,我们从同一个说话人的所有句子中提取average speaker embedding,这个embedding在后面被用来做源选择。然而,这些句子是被污染过的有重叠语音,所以speaker embedding会被逐步优化,一些异常值被剔除。具体步骤如下:
- Step1:计算每一个句子的speaker embedding
- Step2:计算你每一个说话人的average embedding
- Step3:对每一个说话人,移除其average embedding中的异常值,按欧氏距离判断
- Step4:计算移除了异常值的average embedding
- Step5:按照余弦相似度选择embedding与average embedding最接近的输出源
- Step6:计算所有选择的输出源的speaker embedding
- Step7:返回到Step2
使用这样的源选择策略,分离模型可以直接用于说话人提取,不用改动模型结构也不用重新训练。而且,我们的方法不要求注册语音,可以直接嵌入到转录系统中。
4.实验配置
4.1 数据集及配置
对于PIT实验,本文通过图像方法添加混响[26]以及添加同向噪声方法[27],将LibriMix[18]拓展到R-LibriMix版本。混响信号被用作训练目标,模型关注于分离。对于MixIT实验,使用来自AMI[19]的远程麦克风记录的波束形成音频。合成的MOMs信噪比范围为[-5,5]dB。验证时,为了实现基于域内信号模型和基于ASR的真实数据模型的比较,我们使用了合成的R-LibriMix、合成的LibriCSS以及真实AMI数据。
下游模型是一个单个Comformer block[28], attention维度是256,4个attention head,1024维隐藏状态。有监督PIT训练和半监督PIT&MixIT训练输出的mask分别为2个和4个。**半监督用softmax替换sigmoid激活层,因为其引入了mask间的关联信息,这和MixIT的假设一致,**带来了更快且稳定的收敛。短时傅里叶变换使用400点的hann 窗,其stride为160个点。微调机制有两个阶段。在第一个阶段,只对Conformer进行100次更新100k。在第二阶段,SSL模型被解冻,并进行80k次微调。对于半监督训练,MixIT是使用几率为80%,从AMI中采样,而PIT从R-LibriMix中采样。
4.2 转录系统
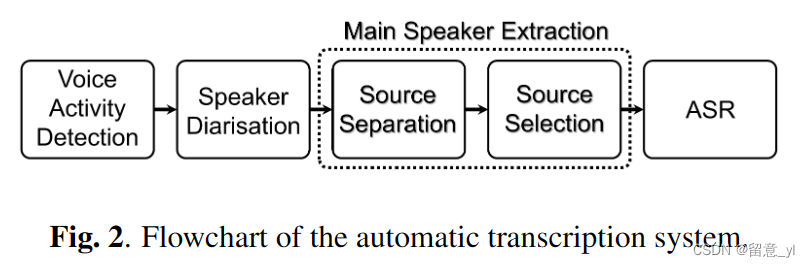
图2是转录系统的流程图。首先,通过VAD和Speaker Diarisation系统将连续输入记录裁剪到句子级别,并打上说话人标签。然后,通过源分离和源选择,语音中的重叠被移除并保留了主说话人信号。最后,使用ASR模型生成转录文本。具体细节如下:1)VAD:WavVec2在AMI上fine-tune, 并在softmax后添加了一个线性层,给出语音存在或不存在的概率。语音区域间的时间间隔大于0.04s,同[29]。2) Diarisation: 用ECAPA-TDNN[30]生成speaker embedding,时间窗为3s,窗移为1.5s。然后通过频谱聚簇将说话人个数归类到10个。3)source separation: WavLM模型以半监督方式在R-LibriMix和AMI上微调。4)source selection:迭代源选择使用ECAPA-TDNN生成的speaker embedding。在AMI dev set上,我们发现WER在前两次迭代中有明显下降,而后基本保持不变。因此,为提高效率迭代次数设为2。另外,移除了60%的异常值以稳定收敛。5)ASR:ASR模型使用Wav2Vec2-Robust[31]作为base模型,与以下模型作比较:在Switchboard[32]上fine-tune的W2V2-SWB;在AMI上fine-tune的W2V2-AMI;基于W2V2-AMI进一步在AMI分离语音上fine-tune的W2V2-SMI-Sep。
4.3 评估
我们使用尺度不变信噪比(SISNR)和词错率(WER)对SSL模型进行初步比较。R-LibriMix提供参考信号,计算所有置换组合的最高SISNR。对于LibriCSS和AMI,仅转录可获得的句子,从未获得分离源的最低WER。
源选择通过和oracle selection(权威选择)的WER比较进行评估(Oracle selection是选择转录文本和ground truth最接近的源)。同时要计算选择的准确率,定义为estimate selection和oracle selection匹配的时长百分比。
对于转录系统,很难计算传统的WER,因为VAD提供的片段可能和参考句子可能有大不相同的开始和结束时间。因此,我们使用会话级别的cpWER-us[29]。首先一段会话中每个说话人估计值和参考值都按时间顺序串联起来。然后,计算所有可能说话人排列的WER,并去除多余的说话人。最后,最低的WER值被选择作为cpWER-us值。
5.实验结果
5.1 SSL模型的比较
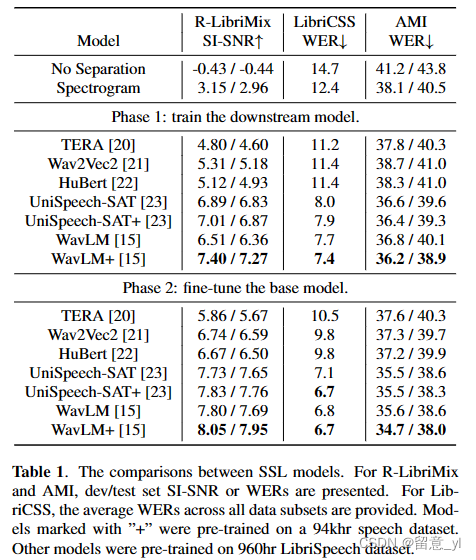
如表1所示。只训练下游模型是,在R-LibriMix和LibriCSS上所有SSL模型都优于频谱。然而,在AMI dev set和test set上,频谱的WER表现更好,分别为38.1%和40.5%,相比于Wav2Vec2和HuBert在AMI dev set 上的38.7%和38.3%,两者在AMI test set都为41.0%。TERA在R-LibriMix上比WavVec2和HuBert稍差,但在AMI dev和test set上有更好的性能,分别达到了37.8%和40.3%,这可能是因为TERA的spectral alteration机制提高了其通用性。这些比较结果说明,虽然R-LibriMix和LibriCss是人造的模拟会与记录语音,但在其上训练出来的结果仍可能与真实预料库结果不一致,因为它们有不同的噪声种类、混响和语音内容。如果SSL模型尽在干净语音记录上训练,其在真实重叠对话语音中可能表现很差。UniSpeech-SAT和WavLM在所有数据集上都比其他模型达到了更好的性能,即使其训练集没有扩大。在AMI语料库上,UniSpeech-SAT在dev和test set上错误率分别为36.6%和39.6%,WavLM稍差分别为36.8%和40.1%。这可能说明,允许模型同时暴露于多说话人的环境下的句混合策略是为语音分离任务提取鲁棒表征的关键。
在SSL模型微调后,他们的性能一致都有提升,因为训练参数从1.8M增至了92M,除了TERA。TERA有着最少的参数,为23M,所以其提升是最小的。微调实验的结果说明,解冻SSL模型的参数对性能更有利,因为这允许模型学习针对特定下游任务的表征,并且不会导致overfitting,因为在AMI上的跨域性能也得到了提升。尽管所有SSL模型都针对语音分离任务进行了优化,但UniSpeech-SAT和WavLM仍然显著优于Wav2Vec2和HuBert,这说明SSL任务的初始化是至关重要的,即使对于可以自动生成大型合成数据集的源分离这样的任务。此外,WavLM+和UniSpeech+两者相较,WavLM+更能凶大量预训练数据中获利,因为多数情况下WavLM和WavLM+的性能差距更大。比如,在AMI dev和test集上,对比WavLM,WavLM+的WER提升为0.9%和0.6%;而对于UniSpeech-SAT,在AMI test set上只有0.3%的绝对提升。一般来说,WavLM+是性能最好的模型,因此在本文的剩余部分中使用了该模型。
5.2 MixIT和源选择的结果
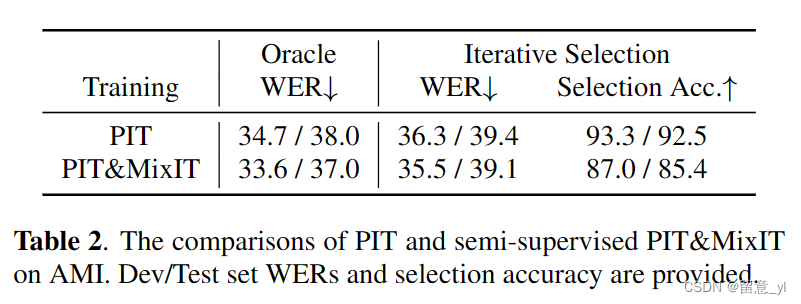
表2比较了PIT和半监督的PIT&MixIT的结果。有了oracle source,PIT&MixIT在AMI dev 和test set的WER有了接近1%的绝对提升。这是因为MixIT使用了真实的you重叠句子,丰富了训练数据。而且,MixIT并不被语音分量限制。使用四个输出源时,非语音分量,如咳嗽声和笑声有时能从语音信号中分离出来。然而,使用迭代源选择后,MixIT变得不那么有效,因为更多的输出源提高了源选择的难度。对于PIT&MixIT,选择准确率在85%左右,但PIT只在输出两个源时,选择准确率高于90%。因此,在真实场景下,输出源数目不同时,不能使用传统置换不变准则去评估模型。对分离性能和源选择准确率间的权衡是更重要的。从这方面来说,有更低WER的半监督训练仍然更好。
5.3 转录系统结果
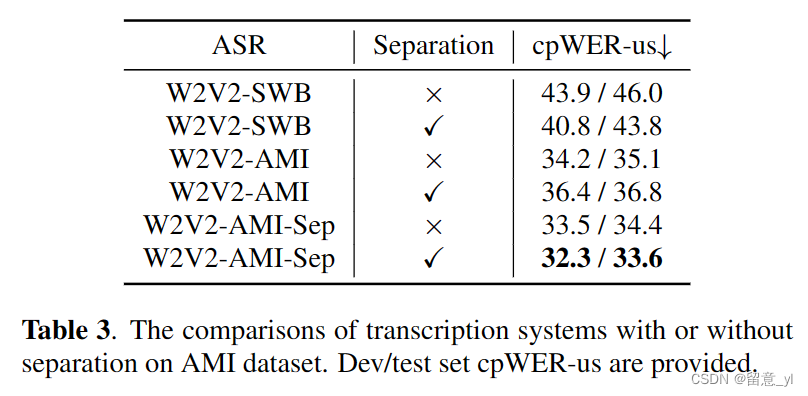
表3展示了源分离对转录系统的影响。对于W2V2-SWB,基于无重叠语音信号训练的ASR模型,不适用分离系统,其在AMI dev和test set上的cpWER-us为43.9%和46.0%。在加入了分离系统后,cpWER-us降至40.8%和43.8%。然而,如果ASR模型在AMI(W2V2-AMI)上进行微调,则源分离会损害性能,并观察到删除错误的大幅增加。一个可能的原因是W2V2-AMI看到了重叠的数据,所以它学会了忽略背景说话人,分离系统后,更多的语音成分可能被错误地识别为背景。此外,分离模型引入了域外数据,如具有长静音的话语和系统噪声。为了解决这些问题,W2V2-AMI模型对分离的数据进行了微调,得到的W2V2-AMI-Sep与没有使用W2V2-AMI进行源分离的系统相比,得到了最低的cpWER-us,AMI dev和test set的绝对减少了1.9%和1.5%。与W2V2-AMI相比,W2V2-AMI-Sep使用非分离数据也显示了更好的性能,AMI dev和test set的绝对cpWER-us减少了0.7%和0.7%,这意味着重叠可能会损害ASR模型的训练
6.总结
本文研究了七种SSL模型用于源分离。我们强调了使用真实会议数据的重要性,因为在模拟数据及上的表现可能与真实数据集上的不一致。实验表明,SSL模型不仅作为特征提取器有效,而且也是有效的可训练基础模型。然而,在干净单说人语音上训练的SSL模型,比如Wav2Vec2和HuBert,在真实数据上的通用性能受限。对于转录系统来说,使用源选择方法的源分离系统可以直接放在diarization后和ASR之前。为了最优化性能,MixIT使用真实混合语音进行训练,ASR模型进一步在分离语音上微调。最后的结果是,cpWER-us在AMI上有显著下降。















 1478
1478











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









