









python爬取某金融网站的用户评论,并进行词云图可视化。
一,爬取数据
1. 唠叨一下
多说一句,这里编写的代码用来作为学习所用,希望使用者不要恶意的用来造成别人的网站服务器压力,我们爬到数据就行不要恶意运行代码,好了不多说了,说我们的正事。
2. 所要爬取的网站,及其数据
网站
http://www.affta.cn/financeReview.jspxpageNumber=1&pageSize=10&contentType=0&zim=#viewall
爬取的数据
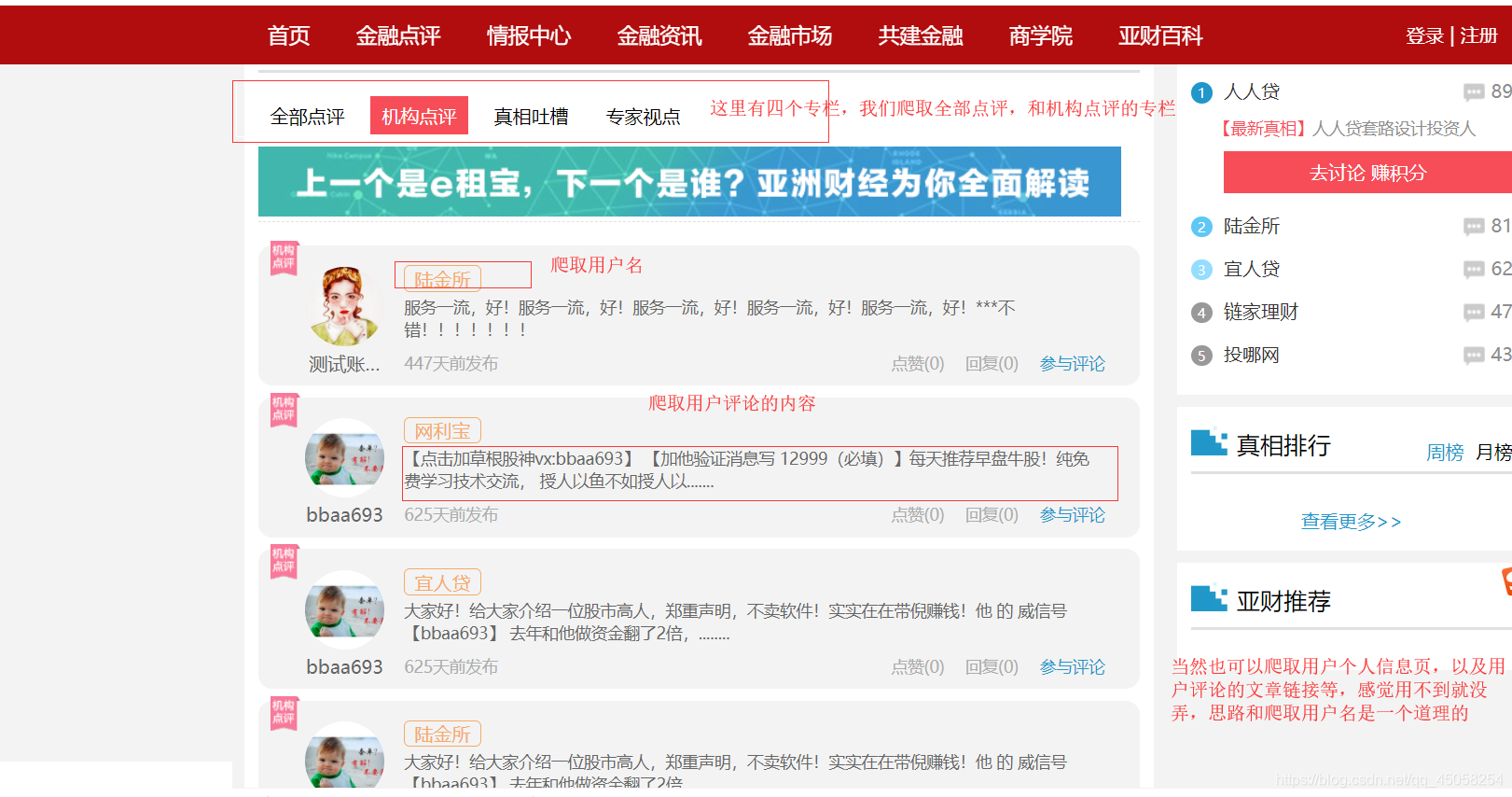
3. 审查元素发现爬取的数据都是静态的,请求就可以得到,没有JavaScript,以及AjAX动态发送过来的,这样就好办了,直接解析网页,提取内容就可以了。
# -*- coding: utf-8 -*-
#@Project filename:PythonDemo SpiserFinancial.py
#@IDE :IntelliJ IDEA
#@Author :ganxiang
#@Date :2020/03/27 0025 15:19
import json
import requests
import parsel
import pandas
headers = {
'User-Agent':"Mozilla/5.0 (Windows NT 10.0; WOW64; rv:38.0) Gecko/20100101 Firefox/38.0"
}
def process(url): #process()方法是爬取机构点评的数据,使用css提取数据
print(url)
res =requests.get(url,headers=headers)
# print(res.text)
sel =parsel.Selector(res.text)
user_name =sel.css('p.list_org a span::text').getall()
print(user_name)
user_href =sel.css('p.list_org a::attr(href)').getall()
print(user_href)
comments =sel.css('p.list_content ::text').getall()
print(comments)
s =[user_name,user_href,comments]
return s
def process_all(url):#process_all()方法是爬取全部点评的数据,使用xpath提取数据
print(url)
res =requests.get(url,headers=headers)
# print(res.text)
sel =parsel.Selector(res.text)
info =sel.xpath('//*[@id="viewall"]/ul')
for f in info:
user_name =f.xpath('./li/div/p[2]/a/text()').getall()
print(user_name)
user_href =f.xpath('./li/div/p[2]/a/@href').getall()
print(user_href)
comments =f.xpath('./li/div/h4/a/text()').getall()
print(comments)
comments_href =f.xpath('./li/div/h4/a/@href').getall()
print(comments_href)
all_data =[user_name,user_href,comments,comments_href]
return all_data
def save(text):#这里为了方便保存数据我直接使用pandas的DataFrame方法直接导出,会出现重复的用户,用户链接,用户评论的内容,这里没太多影响就没更一步的美化了
# 这个data保存的是机构点评的数据
data ={
"用户":text[0],
"用户链接":["http://www.affta.cn/financeReview"+x for x in text[1]],
"用户评论内容":text[2]
}
# 这个all保存的是全部点评的数据
# all ={
# "用户":text[0],
# "用户个人链接":text[1],
# "用户评论内容":text[2],
# "用户评论内容链接":text[3]
# }
df =pandas.DataFrame(data)
# df.to_excel("./SaveData/financial.xlsx")
df.to_csv("./SaveData/financial_机构点评.csv",mode="a",encoding='gb18030',index=1)#以追加的形式将数据写入到同一张csv表中
def run():
# urls =['http://www.affta.cn/financeReview.jspx?pageNumber={}&pageSize=10&zim=#viewall'.format(i)for i in range(1,19)]#这是全部点评的url
urls =['http://www.affta.cn/financeReview.jspx?pageNumber={}&pageSize=10&contentType=0&zim=#viewall'.format(i)for i in range(1,11)]#这是机构点评的url
for url in urls:
text =process(url)
# text =process_all(url)
print(type(text))
save(text)
if __name__ =='__main__':
run()
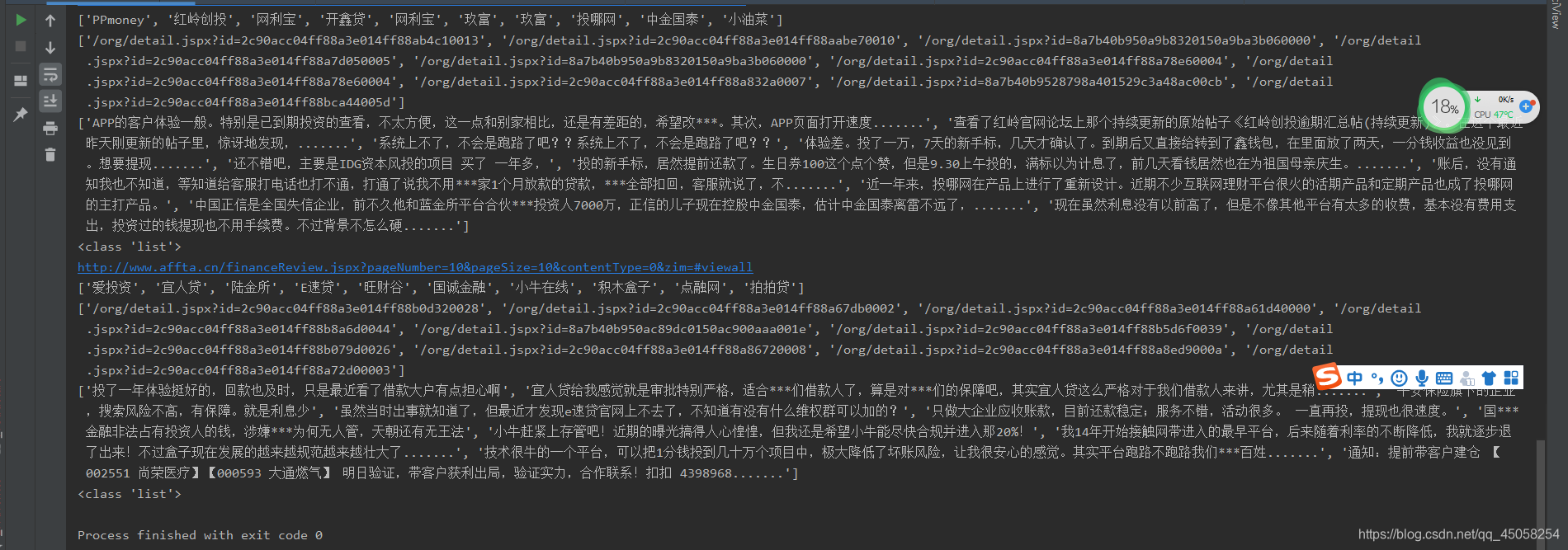
上面代码是爬取机构点评的数据,运行结果如下图
二,词云图可视数据
得到数据为了方便他人浏览,这里简单的进行词云图的可视化,之前我也写了词云图可视化的代码,博文链接为https://blog.csdn.net/qq_45058254/article/details/104445612,可参考。
1,可视化用户评论次数结果
将用户的信息保存到一个txt文档中,然后读取数据,使用Wordcould,matplotlib库画词云图。
# -*- coding: utf-8 -*-
#@Project filename:PythonDemo FinancialWordCloud.py
#@IDE :IntelliJ IDEA
#@Author :ganxiang
#@Date :2020/03/27 0027 17:33
from wordcloud import WordCloud
import matplotlib.pyplot as plt
with open("./Read/user.txt",'r',encoding='utf-8') as f:
txt =f.read()
# print(txt)
photo =plt.imread('./Read/t1.jpg')#形成词云图的图片形状
wordCould=WordCloud(
font_path="simhei.ttf",#设置输出词云的字体
max_font_size=100,#设置字体的大小,默认200
background_color='white',
width=2300,height=1900,
scale=3,#设置图的词密度
random_state=50,## random.Random用来生成随机颜色
mask=photo#设置图片形状
).generate(txt)#根据用户的名字出现频率画词云图
plt.imshow(wordCould,interpolation='spline16')
plt.axis('off')
plt.savefig('./Save/financial_user.jpg')
plt.show()
用户词云图

2,根据用户的评论内容画词云图
原理跟上面一样的,这里不多说了,直接展示画好的图了。

最后,感觉有帮助的,点赞一哈,毕竟也写了一哈时间的。














 3592
3592











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









