







python 爬虫与数据可视化
1.引言
Web已经成为日新月异迅速发展的网络信息技术中的信息载体,如何有效地提取和利用搜索引擎获得互联网最有用的、可以免费公开访问的数据集,查找用户所需的价值数据或者相近的价值信息。网络爬虫具有诸多优势,可根据用户的实际需求,对网页数据信息进行爬取,获取整个网页,且具备很强的自定义性特点。本文通过利用python进行数据爬取与分析,python是近几年比较热门的语言,python入门简单,应用让范围广,与当下众多热门软件兼容,其对应的数据包和框架也逐渐成熟。
2.需求分析
2.1网站分析
爬取豆瓣读书Top250的基本信息,如下图(2-1)第一本书籍,红楼梦,书籍名称、作者、图片、评分、评价人数等数据。利用python向浏览器发送请求的时候,返回的是html代码,然后对html解析,解析的工具有很多。比如:正则表达式、Beautifulsoup、Xpath等,这里采用xpath方法。
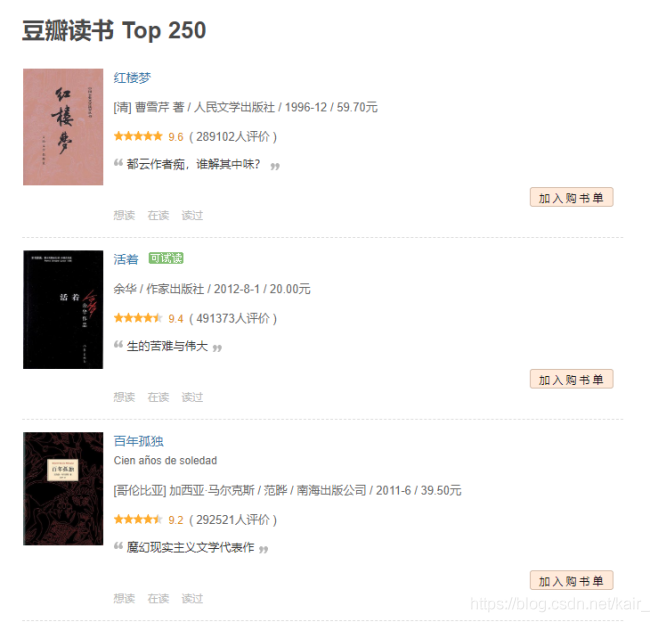
图2-1
借助Chrome开发者工具(F12)来分析网页,在Element下找到需要数据的位置如下图(2-2)所示:
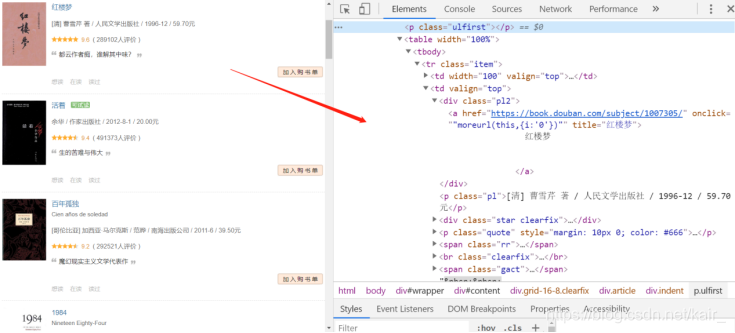
图2-2
2.2爬取基本流程
URL分析
通过浏览器查看分析目目标网页。
获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Respone,便是所要获取的页面内容。
解析内容
得到的内容可能是HTML、json等格式,可以用页面解析库、正则表达式等进行解析。
存储数据
保存形式多样,可以存为文本,也可以保存到数据库,或者保存特定格式的文件
流程如下图(2-3)所示:

图2-3
2.3数据可视化
使用Flask框架将爬取的数据进行可视化分析,Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。本实验用于Flask框架将数据显示到网页,以及生成书籍评分柱状图(使用Echarts模块)和利用书籍概况生成词云(使用WordCloud模块)。
2.3.1引入Flask框架
Flask是一个使用 Python 编写的轻量级 Web 应用框架。其WSGI工具箱采用 Werkzeug ,模板引擎则使用 Jinja2 。
Flask程序运行过程:每个Flask程序必须有一个程序实例。Flask调用视图函数后,会将视图函数的返回值作为响应的内容,返回给客户端。一般情况下,响应内容主要是字符串和状态码。调用视图函数,获取响应数据后,把数据传入HTML模板文件中,模板引擎负责渲染响应数据,然后由Flask返回响应数据给浏览器,最后浏览器处理返回的结果显示给客户端。
创建Flask
图2-4
在运行的环境配置中,勾选Flask Debug

图2-5
使用Echarts
商业级数据图表,它是一个纯JavaScript的图标库,兼容绝大部分的浏览器,底层依赖轻量级的canvas类库ZRender,提供直观,生动,可交互,可高度个性化定制的数据可视化图表。创新的拖拽重计算、数据视图、值域漫游等特性大大增强了用户体验,赋予了用户对数据进行挖掘、整合的能力。
支持的图表:
折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)
雷达图(填充雷达图)、和弦图、力导向布局图、地图、仪表盘、漏斗图、事件河流图等12类图表
官方中文网址:https://www.echartsjs.com/zh/index.html
使用流程:
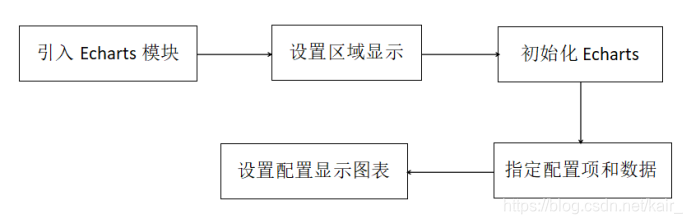
图2-6
使用WordCloud
WordCloud是python的一个三方库,称为词云也叫做文字云,是根据文本中的词频,对内容进行可视化的汇总.原理是首先将爬取的文本数据通过分隔单词,然后统计单词出现次数并过滤,接着根据统计配置字号,最后将生成的字号布局到给定的环境中。
2.4引入模块
模块(module):用来从逻辑上组织Python代码(变量、函数、类),本质就是py文件,提高代码的可维护性。Python使用import来导入模块。如本次实验用到的模块有:
3.实现代码
3.1爬取网页
3.1.1URL分析
页面URL:https://book.douban.com/top250?start=
页面包括250条书籍数据,分10页,每页25条,每页的URL的不同之处:最后的数值=(页数-1)*25

图3-1
3.1.2获取数据
通过HTTP库向目标站点发起请求,请求可以包含额外的header等信息,如果服务器能正常响应,会得到一个Response,便是所要获取的页面内容。具体操作如下:
对每一个页面,调用gainURL函数,传入一个url参数;urllib.request.urlopen发送请求获取响应;read()获取页面内容
def gainURL(url):
head = {
#模拟浏览器头部信息,向豆瓣服务器发送消息
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
request = urllib.request.Request(url,headers=head)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
return html
3.1.3解析内容
得到的内容可能是HTML、JSON等格式,可以用bs4、正则表达式、xpath等进行解析。
使用正则表达式找到具体的内容
findLink = re.compile(r'<a class="nbg" href="(.*?)" οnclick=') # 读书详情链接
findimgSrc = re.compile(r'<img src="(.*?)"')# 书籍图片链接
findTitle = re.compile(r'title="(.*?)"')# 书籍名称
findAuthor = re.compile(r'<p class="pl">(.*?)</p>')# 书籍作者
findRating = re.compile(r'<span class="rating_nums">(.*?)</span>')#书籍评分
findInq = re.compile(r'<span class="inq">(.*)</span>')# 书籍概况
BeautifulSoup定位特定的标签位置与正则表达式结合爬取内容
#解析数据
soup=BeautifulSoup(html,"html.parser") #bs4定位特定的标签位置
for item in soup.find_all('table'):
data = [] # 保存一部电影的所有信息
item = str 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3907
3907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









