







前言
之前文章已经讲过yolov5模型的训练,这一篇将说一下分类模型训练流程。
https://blog.csdn.net/qq_45066628/article/details/129470290
新版本简介
YOLOv5官方发布了v6.2版本,v6.2版本支持分类模型训练、验证、预测和导出;v6.2版本的推出使得训练分类器模型变得超级简单!
v6.2版本项目结构并无太大改变,主要是增加了classify文件夹以及predict.py train.py val.py 这三个文件;那么这三个文件也分别对应着分类模型的推理、训练和验证。
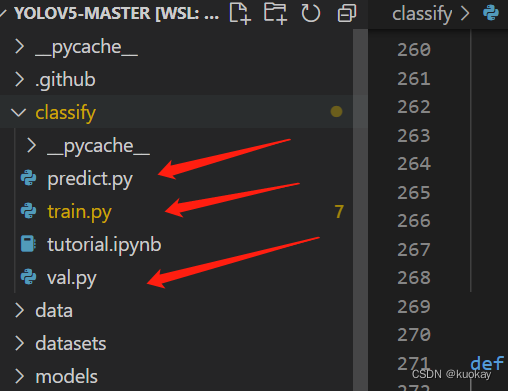
训练前准备工作🌟
模型下载
git clone https://github.com/ultralytics/yolov5
cd yolov5
pip install -qr requirements.txt
数据准备
这里数据集采用kaggle猫狗大战数据集

数据集下载地址:https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition/data
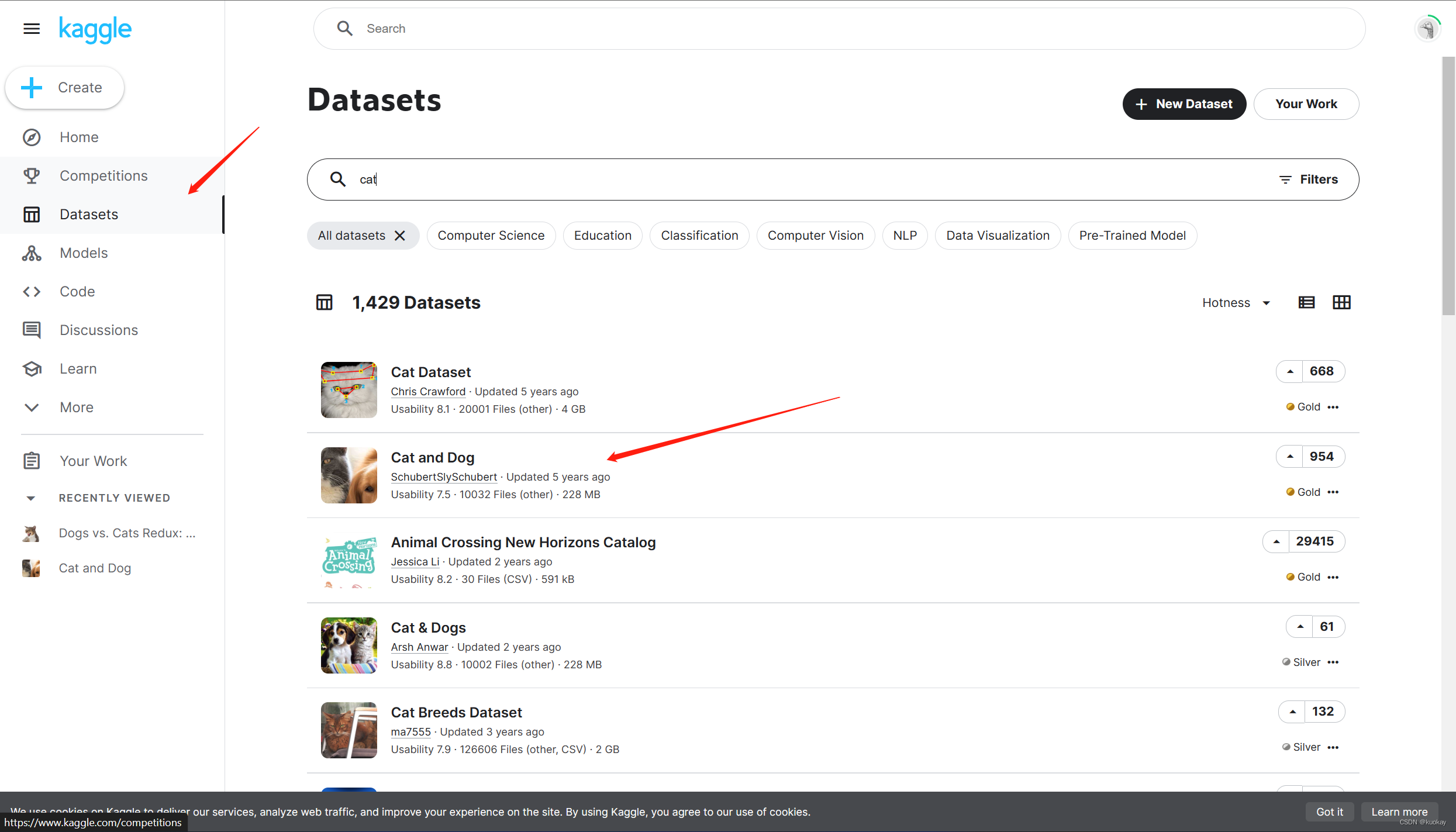
划分数据集
分类模型无需标注数据,只需要将训练的图片按类别文件夹划分即可
格式如下🍀:
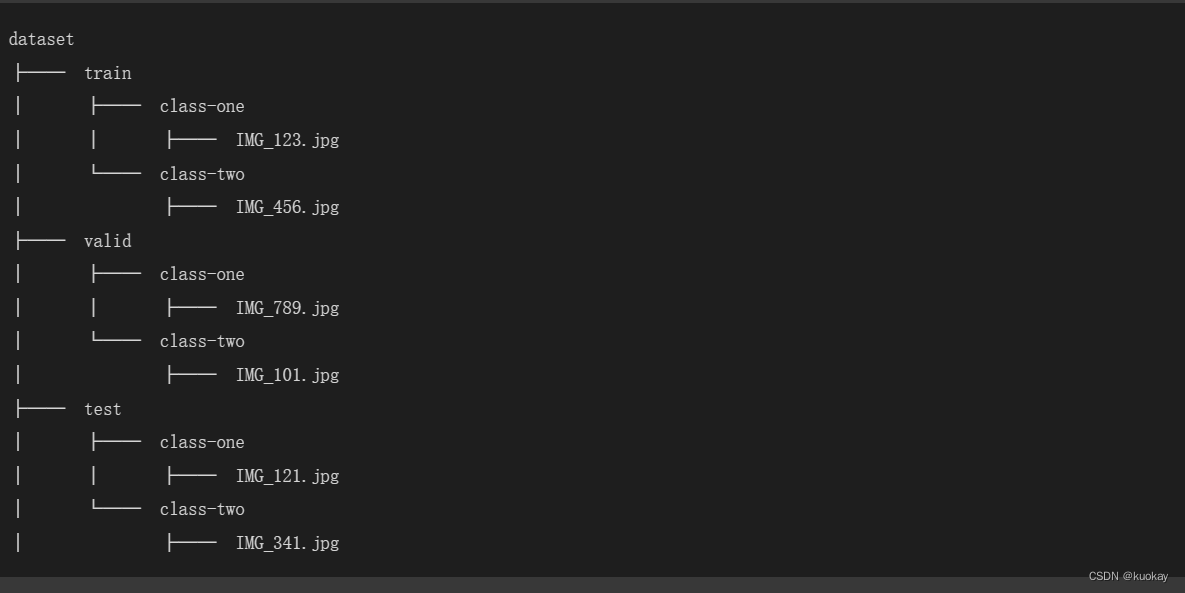
示例:
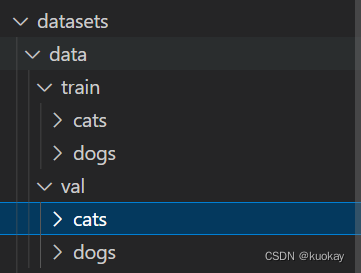
划分脚本:
import os
from shutil import copy
import random
def mkfile(file):
if not os.path.exists(file):
os.makedirs(file)
# 获取data文件夹下所有文件夹名(即需要分类的类名)
file_path = '../test_set/'
save_path = './data/'
flower_class = [cla for cla in os.listdir(file_path)]
# 划分比例,训练集 : 测试集 :验证= 7:1:2
split_train = 0,7
split_val = 0.1
split_test = 0.2
# 遍历所有类别的全部图像并按比例分成训练集和验证集
for cla in flower_class:
cla_path = file_path + '/' + cla + '/' # 某一类别的子目录
images = os.listdir(cla_path) # iamges 列表存储了该目录下所有图像的名称
num = len(images)
eval_train = random.sample(images, k=int(num * split_train)) # 从images列表中随机抽取 k 个图像名称
eval_val = random.sample(images, k=int(num * split_val))
for index, image in enumerate(images):
if image in eval_train:
image_path = cla_path + image
new_path = save_path+'/tarin/' + cla
mkfile(new_path)
copy(image_path, new_path) # 将选中的图像复制到新路径
elif image in eval_val:
image_path = cla_path + image
new_path = save_path+'/val/' + cla
mkfile(new_path)
copy(image_path, new_path) # 将选中的图像复制到新路径
else:
image_path = cla_path + image
new_path = save_path+'/test/' + cla
mkfile(new_path)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index + 1, num), end="") # processing bar
print()
print("processing done!")
下载权重文件
下载地址:https://github.com/ultralytics/yolov5
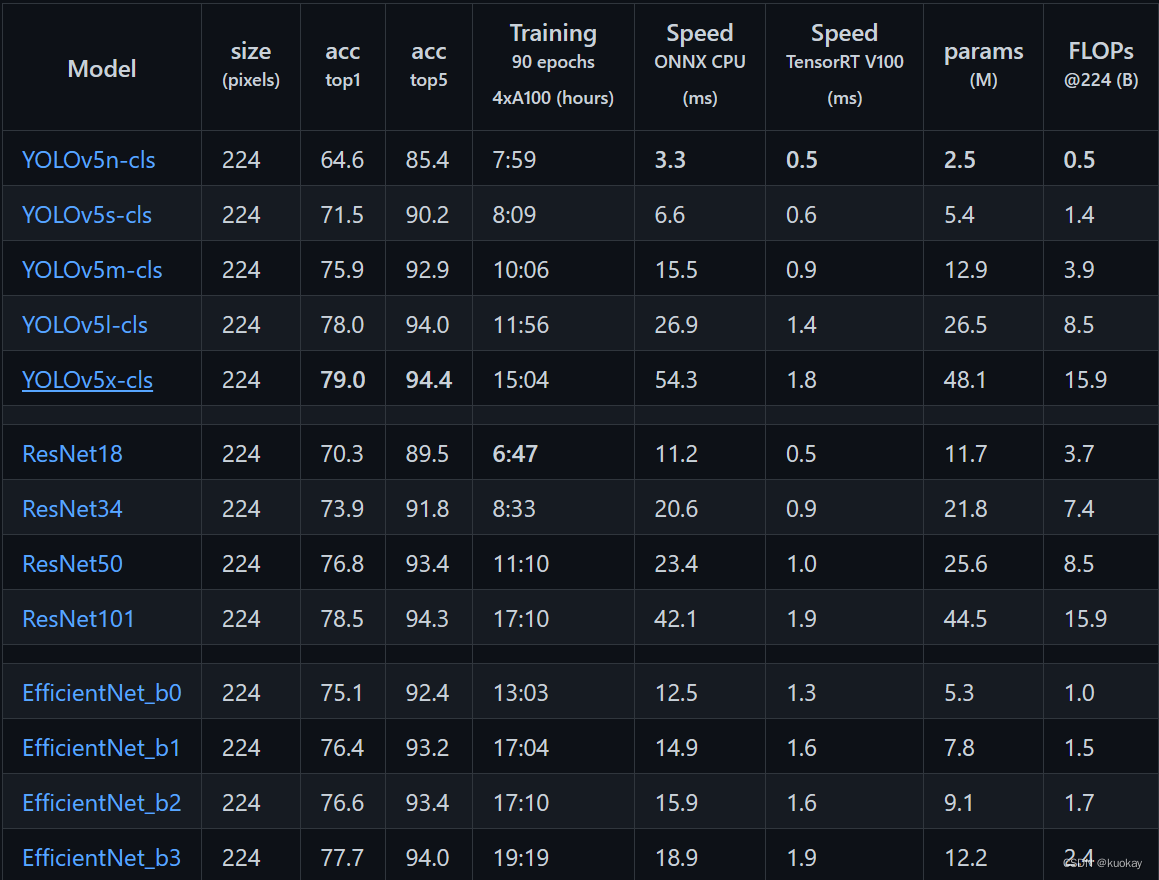
不同文件,使用产生的效果也不一样,这里使用YOLOv5s-cls
修改配置文件
到classify文件夹下,修改train.py
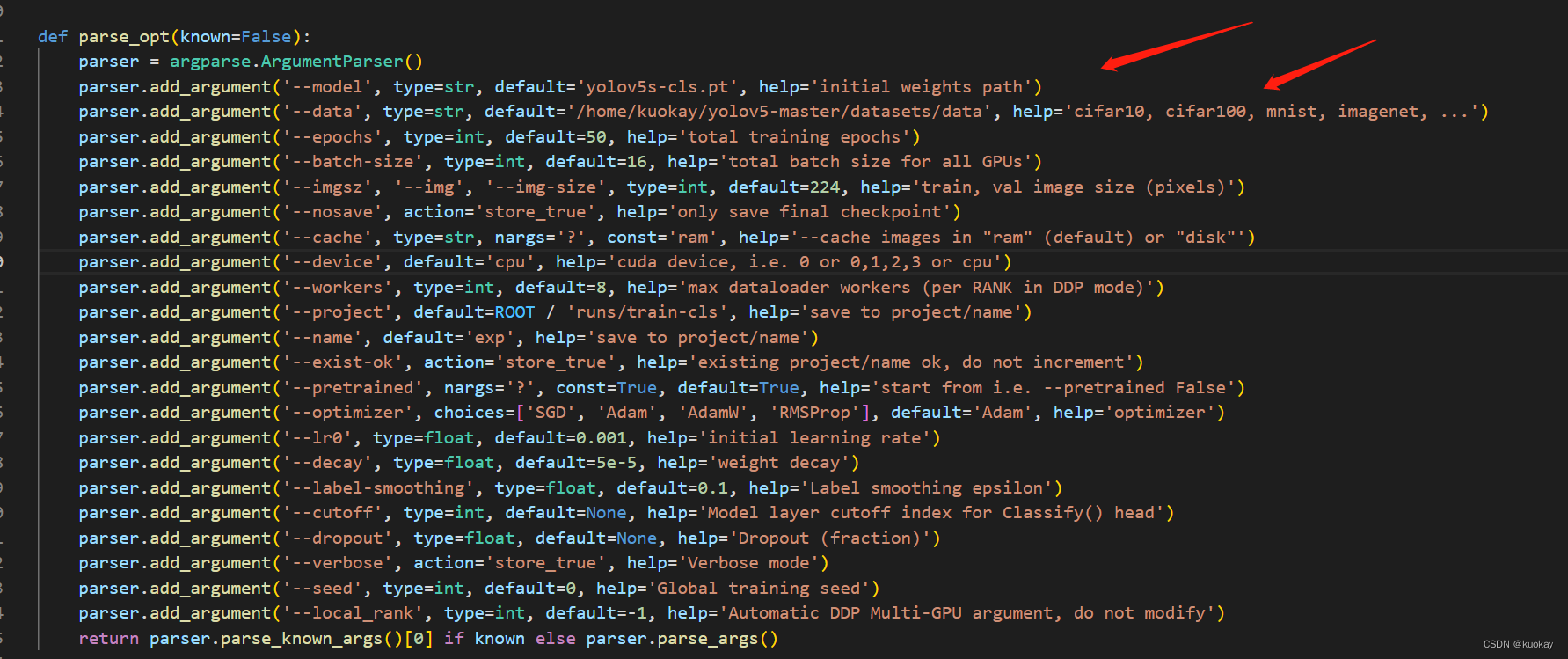
第一行设置自己下载的权重文件路径,第二行设置数据集路径,其余参数可根据自行需要修改。
开始训练🚀
-
方法一:
运行classify下的train.py文件,这里由于cuda问题,暂时选用cpu进行训练演示。
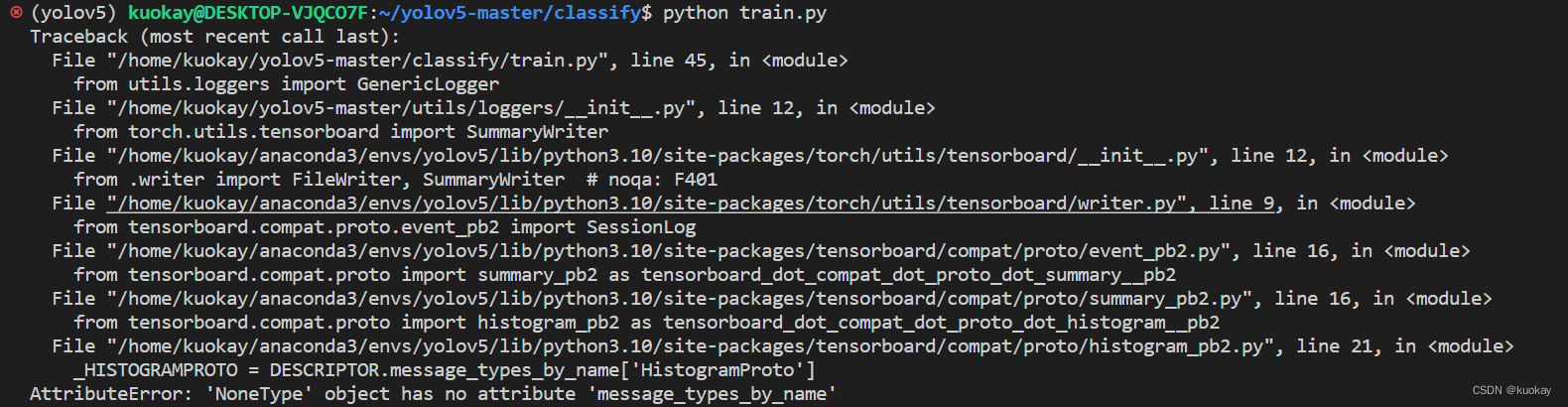
运行后这里缺失模块产生了一个报错,若没有跳过,解决方法:pip install --upgrade protobuf
然后重新运行train.py文件
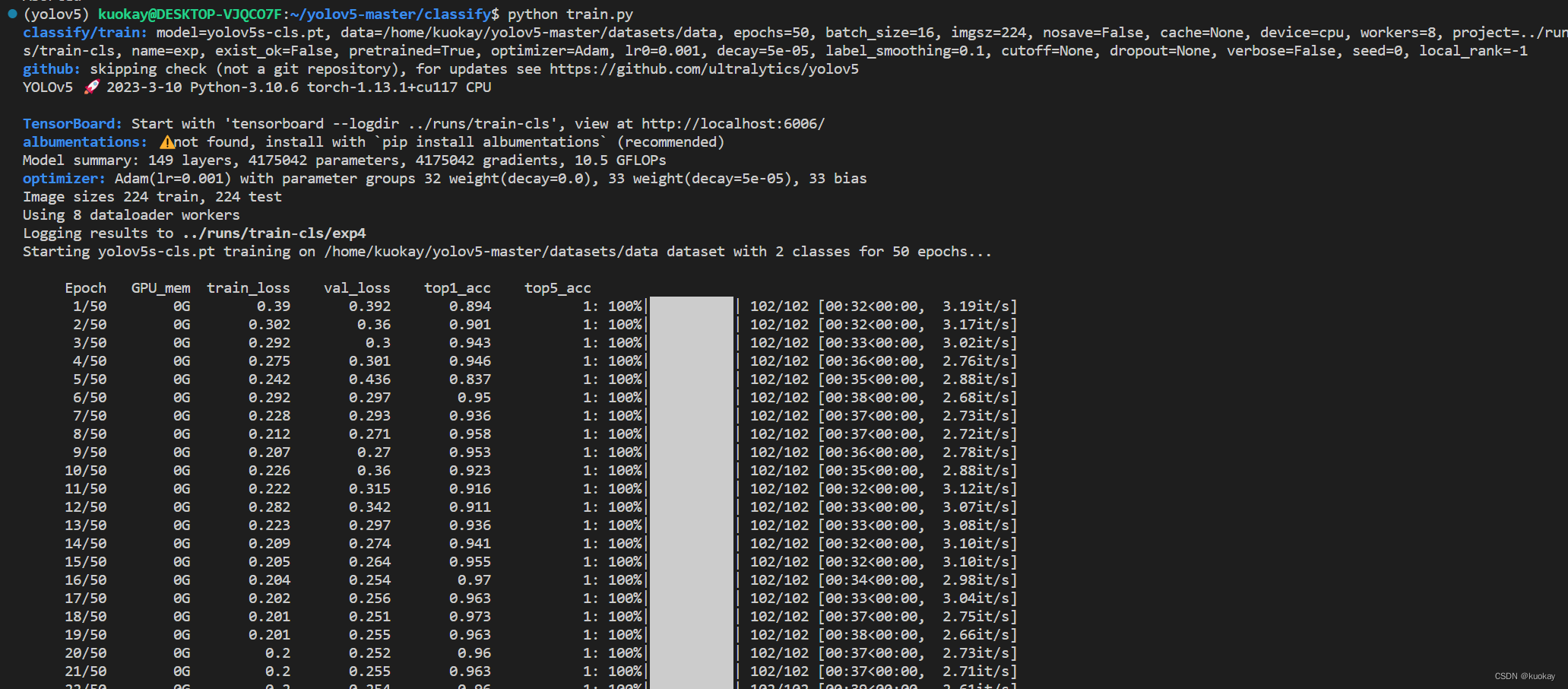
-
方法二:
python classify/train.py --model yolov5s-cls.pt --data datasets/data–epochs 100 --batch-size 32 --imgsz 224
训练完成后,会在runs文件夹下看到模型
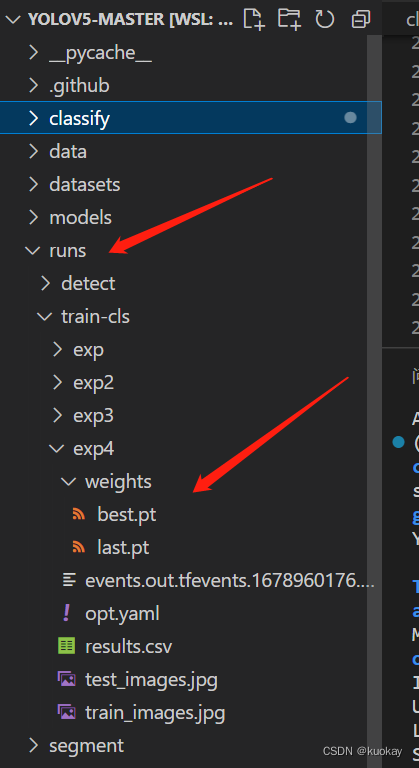
验证和推理
验证
-
方法一:
python classify/val.py --weights runs/train-cls/exp4/weights/best.pt --data datasets/data
-
方法二:
到classify文件夹下,修改val.py
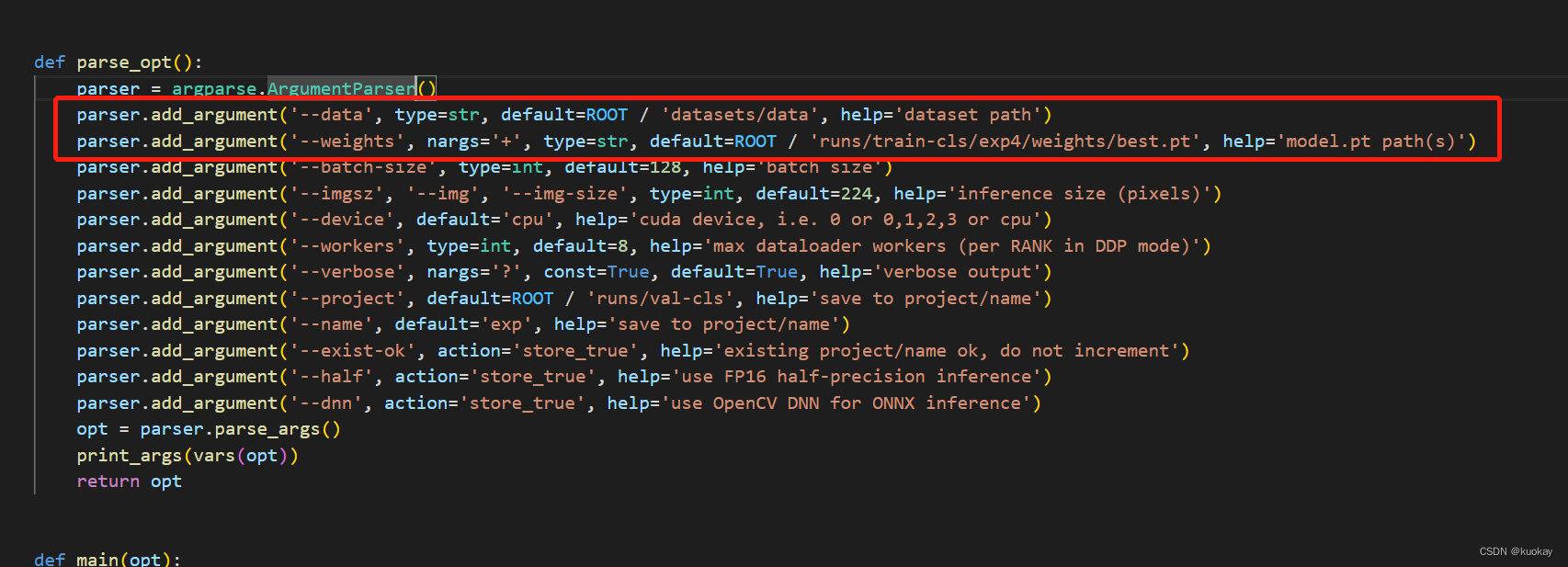
第一行使用自己训练的模型文件,第二行修改数据集路径,其余参数可根据自行需要修改。
验证结果:
输出类别和正确率信息

推理
方法与上述类似,该文件或直接使用命令行
# 测试im1.jpg
python classify/predict.py --weights runs/train-cls/exp4/weights/best.pt --source im1.jpg
# 测试im2.jpg
python classify/predict.py --weights runs/train-cls/exp4/weights/best.pt --source im2.jpg
推理结果:
可以到runs文件夹下的predict-cls文件夹下查看结果


导出
使用ONNX
执行命令导出onnx:
python export.py --weights runs/train-cls/exp4/weights/best.pt --include onnx
输出:
Detect: python classify/predict.py --weights runs/train-cls/exp4/weights/best.onnx
Validate: python classify/val.py --weights runs/train-cls/exp4/weights/best.onnx
PyTorch Hub: model = torch.hub.load(‘ultralytics/yolov5’, ‘custom’, ‘runs/train-cls/exp4/weights/best.onnx’) # WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
使用TensorRT
执行命令导出engine:
python export.py --weights runs/train-cls/exp4/weights/best.pt --include engine --device 0
输出:
Detect: python classify/predict.py --weights runs/train-cls/exp4/weights/best.engine
Validate: python classify/val.py --weights runs/train-cls/exp4/weights/best.engine
PyTorch Hub: model = torch.hub.load(‘ultralytics/yolov5’, ‘custom’, ‘runs/train-cls/exp/weights/best.engine’) # WARNING ⚠️ ClassificationModel not yet supported for PyTorch Hub AutoShape inference
Visualize: https://netron.app
















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











