







1. Raft协议
nacos的CP架构是通过Raft协议来实现的,Raft协议和ZAB协议都是分布式一致性协议的实现,两者很类似,主要包括两部分:
- Leader选举(半数以上节点投票同意)
- 集群节点写入数据同步(两阶段提交,半数以上节点写入成功)
①:Leader选举
集群中各节点有三种状态可以切换:跟随者(Follower)、领导者(Leader)、候选者(Candidater)
-
在进行leader选举时,所有的节点都从跟随者(
Follower)状态开始

-
这些跟随者(
Follower)如果没有收到其他leader的心跳,那么他们会变成候选者(Candidater)状态

-
当然,跟随者(
Follower)在成为候选者(Candidater)状态时,并不是只要没接收到Leader心跳就会变换状态,这样是不合理的! Raft协议规定了Follower成为Candidater之前所等待的时间被随机分配在150毫秒至300毫秒之间,尽可能的避免多个节点同时发起投票,造成多节点选票一致的情况。如果出现了多节点选票一致的情况,那么此次选举作废,重新随机分配等待时间,重新发起选举,直到选举成功!

-
变成候选者(
Candidater)的B节点开始向其他节点开始发起投票!

-
其他节点在接收到B节点的投票请求时,分别给B投一票,并重新为自己随机分配一个
150 - 300毫秒的选举时间!

-
B节点获取了大于集群节点一半的选票,变成了领导者
Leader

-
后续B作为
Leader会给其他节点发送心跳验证节点存活、同步数据。其他节点接受心跳后会重置变成候选者(Candidater)状态的时间。

-
如果B节点宕机,A、C节点会通过
150 - 300毫秒的随机时间后变为候选者(Candidater)节点,并在AC中选举新的Leader节点!由于C节点收到了A和C(自身)节点的选票,同时2 > 1.5,所以C变为新的Leader!

②:集群节点数据同步
-
首先客户端集群写数据时,只能向
Leader节点中写
-
当
Leader接收到数据时,并不是马上在Leader节点内部保存数据,并给客户端回应。而是把数据传输给其他节点。
-
其他节点接收到数据后给
Leader返回响应,Leader接收到大多数(可配置,一般为半数以上)Flower节点的响应后,数据才在Leader节点提交,写入Leader节点内部,并响应给客户端写数据成功!

-
Leader响应给客户端写数据成功,然后再通过心跳把数据更新到其他Flower节点下

③:发生网络分区,出现脑裂如何处理?
- 当多个节点发生了网络分区,就会出现多个
Leader,也就是俗称的脑裂现象!

- 由于
Raft协议规定:更新数据时Leader要与Flower节点通信,且必须收到大多数(默认半数)节点的响应才能更新数据成功,下图由于网络分区把5个节点的集群变成了两个分区,分区之间无法通信:- B节点作为
Leader在他自己的分区内最多接受1个节点响应,1=1(半数),并没有大于半数1,所以无法更新数据,进而无法给客户端更新成功的响应,可以无法对外提供服务,该分区不可用! - 而C节点作为
Leader在他自己的分区内可以接受2个节点响应,2>1.5(半数),大于半数节点1.5,所以在当前分区内可以正常更新数据,正常给客户端发送成功的响应! - 通过这个半数机制,保证即使发生了脑裂,也能保证数据的一致性!

- B节点作为
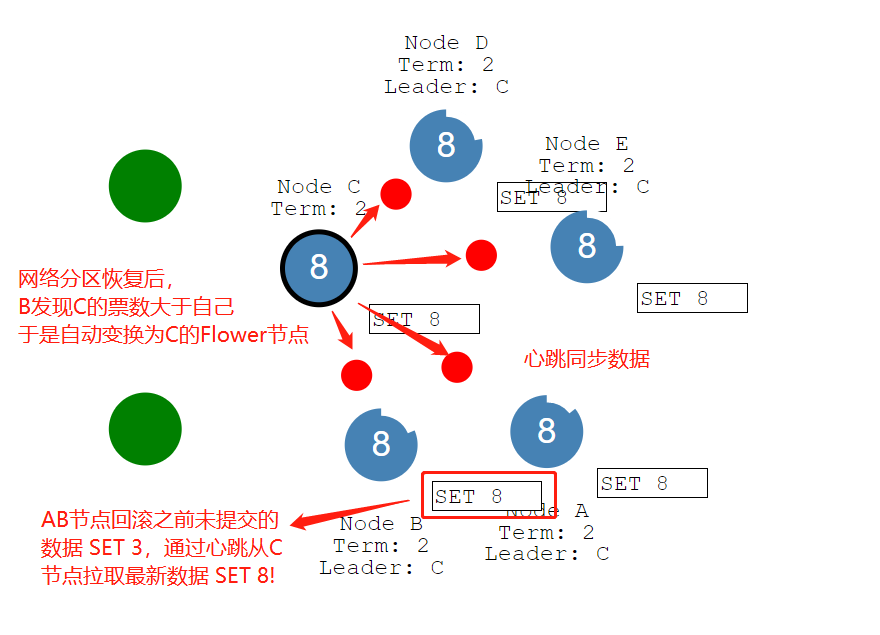
- 当网络分区恢复后,
Leader节点B由于看到Leader节点C拥有更多的选票,就把自己的Leader身份下掉,变为Leader节点C的Flower节点!并回滚自己之前未提交的数据SET 3。然后通过心跳从Leader节点C同步最新的数据!














 796
796











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









