






pod&&namespace&&label
k8s核心资源pod介绍
**K8s 官方文档:**https://kubernetes.io/
**K8s 中文官方文档: **https://kubernetes.io/zh/
**K8s Github 地址:**https://github.com/kubernetes/
pod是什么
官方文档:https://kubernetes.io/docs/concepts/workloads/pods/
Pod 是 Kubernetes 中的最小调度单元,k8s 是通过定义一个 Pod 的资源,然后在 Pod 里面运行容器,容器需要指定一个镜像,这样就可以用来运行具体的服务。一个 Pod 封装一个容器(也可以封装多个容器),Pod 里的容器共享存储、网络等。也就是说,应该把整个 pod 看作虚拟机,然后每个容器相当于运行在虚拟机的进程。
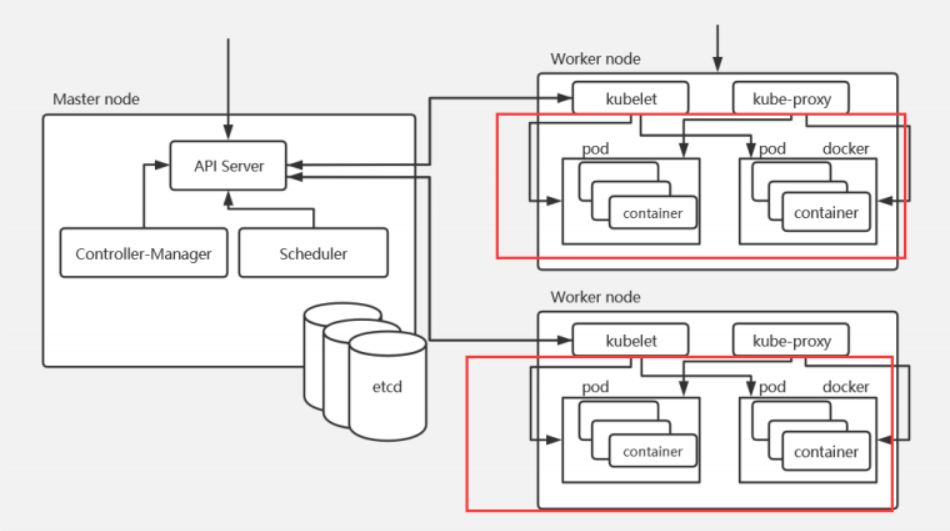
Pod 是需要调度到 k8s 集群的工作节点来运行的,具体调度到哪个节点,是根据 scheduler 调度器实现的。
白话解释:
可以把 pod 看成是一个“豌豆荚”,里面有很多“豆子”(容器)。一个豌豆荚里的豆子,它们吸收着共同的营养成分、肥料、水分等,Pod 和容器的关系也是一样,Pod 里面的容器共享 pod 的网络、存储等。

pod 相当于一个逻辑主机–比方说我们想要部署一个 tomcat 应用,如果不用容器,我们可能会部署到物理机、虚拟机或者云主机上,那么出现 k8s 之后,我们就可以定义一个 pod 资源,在 pod 里定义一个tomcat 容器,所以 pod 充当的是一个逻辑主机的角色。
pod如何管理多个容器
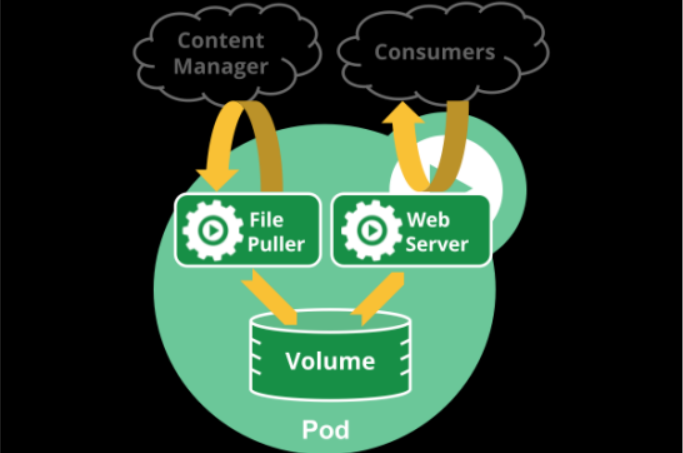
Pod 中可以同时运行多个容器。同一个 Pod 中的容器会自动的分配到同一个 node 上。同一个 Pod 中的容器共享资源、网络环境,它们总是被同时调度,在一个 Pod 中同时运行多个容器是一种比较高级的用法,只有当你的容器需要紧密配合协作的时候才考虑用这种模式。例如,你有一个容器作为 web 服务器运行,需要用到共享的 volume,有另一个“sidecar”容器来从远端获取资源更新这些文件。
一些 Pod 有 init 容器和应用容器。 在应用程序容器启动之前,运行初始化容器。
Pod网络
Pod 是有 IP 地址的,每个 pod 都被分配唯一的 IP 地址(IP 地址是靠网络插件 calico、flannel、weave 等分配的),POD 中的容器共享网络名称空间,包括 IP 地址和网络端口。 Pod 内部的容器可以使用 localhost 相互通信。 Pod 中的容器也可以通过网络插件 calico 与其他节点的 Pod 通信。
Pod存储
创建 Pod 的时候可以指定挂载的存储卷。 POD 中的所有容器都可以访问共享卷,允许这些容器共享数据。 Pod 只要挂载持久化数据卷,Pod 重启之后数据还是会存在的
Pod工作方式
在 K8s 中,所有的资源都可以使用一个 yaml 文件来创建,创建 Pod 也可以使用 yaml 配置文件。或者使用 kubectl run 在命令行创建 Pod(不常用)。
自主式Pod
所谓的自主式 Pod,就是直接定义一个 Pod 资源,如下:
pod-tomcat.yaml
apiVersion: v1
kind: Pod
metadata:
name: tomcat-test
namespace: default
labels:
app: tomcat
spec:
containers:
- name: tomcat-java
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
使用资源清单文件
[root@k8s01 pod]# kubectl apply -f pod-tomcat.yaml
pod/tomcat-test created
[root@k8s01 pod]# kubectl get pods -o wide -l app=tomcat
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tomcat-test 1/1 Running 0 16s 10.244.236.132 k8s02 <none> <none>
但是自主式 Pod 是存在一个问题的,假如我们不小心删除了 pod:
[root@k8s01 pod]# kubectl delete pods tomcat-test
pod "tomcat-test" deleted
[root@k8s01 pod]# kubectl get pods -o wide -l app=tomcat
No resources found in default namespace.
#结果是空,说明 pod 已经被删除了
通过上面可以看到,如果直接定义一个 Pod 资源,那 Pod 被删除,就彻底被删除了,不会再创建一个新的 Pod,这在生产环境还是具有非常大风险的,所以今后我们接触的 Pod,都是控制器管理的。
控制器管理的Pod
常见的管理 Pod 的控制器:Replicaset、Deployment、Job、CronJob、Daemonset、Statefulset。控制器管理的 Pod 可以确保 Pod 始终维持在指定的副本数运行。
如,通过 Deployment 管理 Pod
把ajie-nginx.tar.gz 上传到 k8s02 和 k8s03 节点
[root@k8s02 ~]# docker load -i ajie-nginx.tar.gz
[root@k8s03 ~]# docker load -i ajie-nginx.tar.gz
#创建一个资源清单文件
nginx-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-test
labels:
app: nginx-deploy
spec:
selector:
matchLabels:
app: nginx
replicas: 2
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: my-nginx
image: ajie/nginx:v1
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
# 应用资源清单文件
[root@k8s01 pod]# kubectl apply -f nginx-deply.yaml
deployment.apps/nginx-test created
# 查看Deployment
[root@k8s01 pod]# kubectl get deploy -l app=nginx-deploy
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-test 2/2 2 2 22s
# 查看Replicaset
[root@k8s01 pod]# kubectl get rs -l app=nginx
NAME DESIRED CURRENT READY AGE
nginx-test-75c685fdb7 2 2 2 41s
# 查看pod
[root@k8s01 pod]# kubectl get pods -o wide -l app=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-test-75c685fdb7-fwnk8 1/1 Running 0 89s 10.244.235.132 k8s03 <none> <none>
nginx-test-75c685fdb7-md7rg 1/1 Running 0 89s 10.244.235.133 k8s03 <none> <none>
# 删除 nginx-test-75c685fdb7-fwnk8这个pod
[root@k8s01 pod]# kubectl delete pods nginx-test-75c685fdb7-fwnk8
pod "nginx-test-75c685fdb7-fwnk8" deleted
# 发现重新创建一个新的 pod 是 nginx-test-75c685fdb7-xvbtx
[root@k8s01 pod]# kubectl get pods -o wide -l app=nginx
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-test-75c685fdb7-md7rg 1/1 Running 0 3m20s 10.244.235.133 k8s03 <none> <none>
nginx-test-75c685fdb7-xvbtx 1/1 Running 0 10s 10.244.236.133 k8s02 <none> <none>
通过上面可以发现通过 deployment 管理的 pod,可以确保 pod 始终维持在指定副本数量
创建Pod方式
K8s 创建 Pod 流程
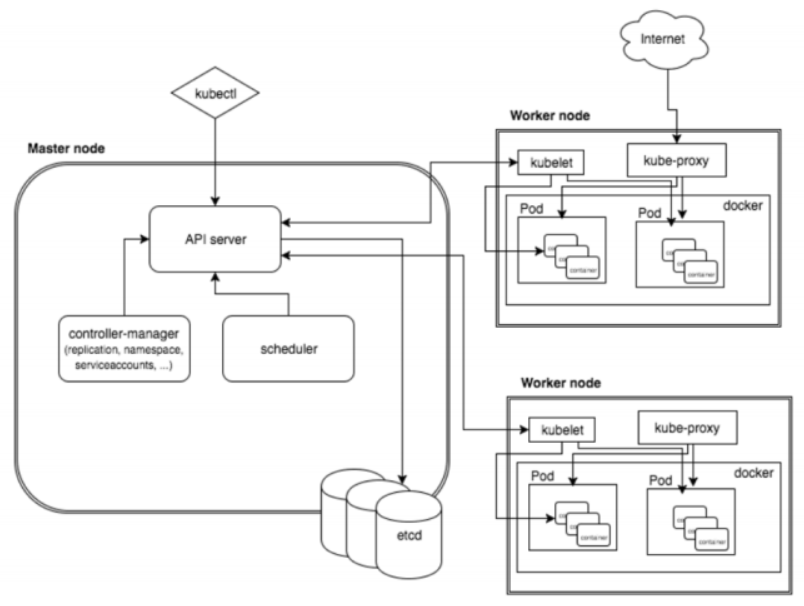
Pod 是 Kubernetes 中最基本的部署调度单元,可以包含 container,逻辑上表示某种应用的一个实例。例如一个 web 站点应用由前端、后端及数据库构建而成,这三个组件将运行在各自的容器中,那么我们可以创建包含三个 container 的 pod。
创建 pod 流程:
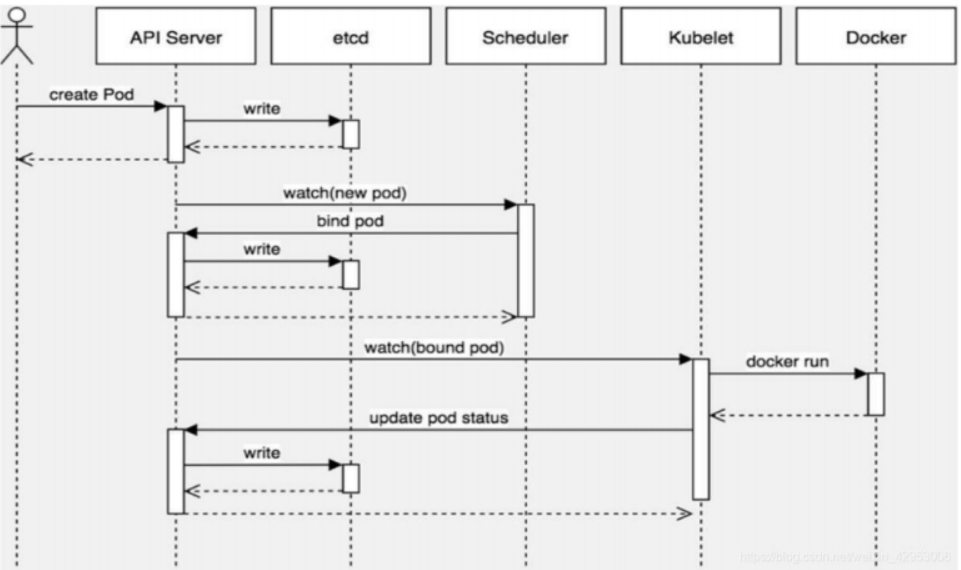
master 节点:kubectl -> kube-api -> kubelet -> CRI 容器环境初始化
第一步:
客户端提交创建 Pod 的请求,可以通过调用 API Server 的 Rest API 接口,也可以通过 kubectl 命令行工具。如 kubectl apply -f filename.yaml(资源清单文件)
第二步:
apiserver 接收到 pod 创建请求后,会将 yaml 中的属性信息(metadata)写入 etcd。
第三步:
apiserver 触发 watch 机制准备创建 pod,信息转发给调度器 scheduler,调度器使用调度算法选择node,调度器将 node 信息给 apiserver,apiserver 将绑定的 node 信息写入 etcd
调度器用一组规则过滤掉不符合要求的主机。比如 Pod 指定了所需要的资源量,那么可用资源比 Pod 需要的资源量少的主机会被过滤掉。
scheduler 查看 k8s api ,类似于通知机制。
**首先判断:pod.spec.Node == null? **
若为 null,表示这个 Pod 请求是新来的,需要创建;因此先进行调度计算,找到最“闲”的 node。
然后将信息在 etcd 数据库中更新分配结果:pod.spec.Node = nodeA (设置一个具体的节点)
ps:同样上述操作的各种信息也要写到 etcd 数据库中中
第四步:
apiserver 又通过 watch 机制,调用 kubelet,指定 pod 信息,调用 Docker API 创建并启动 pod 内的容器。
第五步:
创建完成之后反馈给 kubelet, kubelet 又将 pod 的状态信息给 apiserver,apiserver 又将 pod 的状态信息写入 etcd。
YAML书写技巧:
如下:
apiVersion: v1 # api版本
kind: Pod #创建的资源
metadata:
name: tomcat-test # Pod的名字
namespace: default # Pod所在的名称空间
labels:
app: tomcat #Pod具有的标签
spec:
containers:
- name: tomcat-java # Pod里容器的名字
ports:
- containerPort: 8080 # 容器暴露的端口
image: tomcat-8.5-jre8:v1 # 容器使用的镜像
imagePullPolicy: IfNotPresent #镜像拉取策略
Pod 资源清单编写技巧
通过 kubectl explain 查看定义 Pod 资源包含哪些字段。
[root@k8s01 pod]# kubectl explain pod
KIND: Pod
VERSION: v1
DESCRIPTION:
Pod is a collection of containers that can run on a host. This resource is
created by clients and scheduled onto hosts.
[Pod 是可以在主机上运行的容器的集合。此资源是由客户端创建并安排到主机上。]
FIELDS:
apiVersion <string>
APIVersion defines the versioned schema of this representation of an
object. Servers should convert recognized schemas to the latest internal
value, and may reject unrecognized values. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources
[APIVersion 定义了对象,代表了一个版本。]
kind <string>
Kind is a string value representing the REST resource this object
represents. Servers may infer this from the endpoint the client submits
requests to. Cannot be updated. In CamelCase. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds
[Kind 是字符串类型的值,代表了要创建的资源。服务器可以从客户端提交的请求推断出这个资源。]
metadata <Object>
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
[metadata 是对象,定义元数据属性信息的]
spec <Object>
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
[spec 制定了定义 Pod 的规格,里面包含容器的信息]
status <Object>
Most recently observed status of the pod. This data may not be up to date.
Populated by the system. Read-only. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
[status 表示状态,这个不可以修改,定义 pod 的时候也不需要定义这个字段]
查看 pod.metadata 字段如何定义
[root@k8s01 pod]# kubectl explain pod.metadata
KIND: Pod
VERSION: v1
RESOURCE: metadata <Object>
# metadata 是对象<Object>,下面可以有多个字段
DESCRIPTION:
Standard object's metadata. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
ObjectMeta is metadata that all persisted resources must have, which
includes all objects users must create.
FIELDS:
annotations <map[string]string>
Annotations is an unstructured key value map stored with a resource that
may be set by external tools to store and retrieve arbitrary metadata. They
are not queryable and should be preserved when modifying objects. More
info: http://kubernetes.io/docs/user-guide/annotations
# annotations 是注解,map 类型表示对应的值是 key-value 键值对,<string,string>表示 key 和value 都是 String 类型的
clusterName <string>
The name of the cluster which the object belongs to. This is used to
distinguish resources with same name and namespace in different clusters.
This field is not set anywhere right now and apiserver is going to ignore
it if set in create or update request.
#对象所属群集的名称。这是用来区分不同集群中具有相同名称和命名空间的资源。此字段现在未设置在任何位置,apiserver 将忽略它,如果设置了就使用设置的值
creationTimestamp <string>
Populated by the system. Read-only. Null for lists. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata
deletionGracePeriodSeconds <integer>
Number of seconds allowed for this object to gracefully terminate before it
will be removed from the system. Only set when deletionTimestamp is also
set. May only be shortened. Read-only.
deletionTimestamp <string>
finalizers <[]string>
generateName <string>
generation <integer>
A sequence number representing a specific generation of the desired state.
Populated by the system. Read-only.
labels <map[string]string>
Map of string keys and values that can be used to organize and categorize
(scope and select) objects. May match selectors of replication controllers
and services. More info: http://kubernetes.io/docs/user-guide/labels
#创建的资源具有的标签
#labels 是标签,labels 是 map 类型,map 类型表示对应的值是 key-value 键值对,<string,string>表示 key 和 value 都是 String 类型的
managedFields <[]Object>
name <string>
Name must be unique within a namespace. Is required when creating
resources, although some resources may allow a client to request the
generation of an appropriate name automatically. Name is primarily intended
for creation idempotence and configuration definition. Cannot be updated.
More info: http://kubernetes.io/docs/user-guide/identifiers#names
#创建的资源的名字
namespace <string>
Namespace defines the space within which each name must be unique. An empty
namespace is equivalent to the "default" namespace, but "default" is the
canonical representation. Not all objects are required to be scoped to a
namespace - the value of this field for those objects will be empty.
Must be a DNS_LABEL. Cannot be updated. More info:
http://kubernetes.io/docs/user-guide/namespaces
#创建的资源所属的名称空间
# namespaces 划分了一个空间,在同一个 namesace 下的资源名字是唯一的,默认的名称空间是default。
ownerReferences <[]Object>
resourceVersion <string>
selfLink <string>
SelfLink is a URL representing this object. Populated by the system.
Read-only.
DEPRECATED Kubernetes will stop propagating this field in 1.20 release and
the field is planned to be removed in 1.21 release.
uid <string>
查看 pod.spec 字段如何定义
[root@k8s01 pod]# kubectl explain pod.spec
KIND: Pod
VERSION: v1
RESOURCE: spec <Object>
DESCRIPTION:
Specification of the desired behavior of the pod. More info:
https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#spec-and-status
PodSpec is a description of a pod.
#Pod 的 spec 字段是用来描述 Pod 的
FIELDS:
activeDeadlineSeconds <integer>
Optional duration in seconds the pod may be active on the node relative to
StartTime before the system will actively try to mark it failed and kill
associated containers. Value must be a positive integer.
#表示 Pod 可以运行的最长时间,达到设置的值后,Pod 会自动停止。
affinity <Object>
If specified, the pod's scheduling constraints
#定义亲和性的
automountServiceAccountToken <boolean>
AutomountServiceAccountToken indicates whether a service account token
should be automatically mounted.
containers <[]Object> -required-
List of containers belonging to the pod. Containers cannot currently be
added or removed. There must be at least one container in a Pod. Cannot be
updated.
#containers 是对象列表,用来定义容器的,是必须字段。对象列表 表示下面有很多对象,对象列表下面的内容用 - 连接。
dnsConfig <Object>
Specifies the DNS parameters of a pod. Parameters specified here will be
merged to the generated DNS configuration based on DNSPolicy.
dnsPolicy <string>
enableServiceLinks <boolean>
ephemeralContainers <[]Object>
hostAliases <[]Object>
HostAliases is an optional list of hosts and IPs that will be injected into
the pod's hosts file if specified. This is only valid for non-hostNetwork
pods.
hostIPC <boolean>
Use the host's ipc namespace. Optional: Default to false.
hostNetwork <boolean>
Host networking requested for this pod. Use the host's network namespace.
If this option is set, the ports that will be used must be specified.
Default to false.
hostPID <boolean>
Use the host's pid namespace. Optional: Default to false.
hostname <string>
Specifies the hostname of the Pod If not specified, the pod's hostname will
be set to a system-defined value.
imagePullSecrets <[]Object>
initContainers <[]Object>
nodeName <string>
NodeName is a request to schedule this pod onto a specific node. If it is
non-empty, the scheduler simply schedules this pod onto that node, assuming
that it fits resource requirements.
nodeSelector <map[string]string>
NodeSelector is a selector which must be true for the pod to fit on a node.
Selector which must match a node's labels for the pod to be scheduled on
that node. More info:
https://kubernetes.io/docs/concepts/configuration/assign-pod-node/
overhead <map[string]string>
preemptionPolicy <string>
priority <integer>
priorityClassName <string>
readinessGates <[]Object>
restartPolicy <string>
Restart policy for all containers within the pod. One of Always, OnFailure,
Never. Default to Always. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle/#restart-policy
runtimeClassName <string>
schedulerName <string>
If specified, the pod will be dispatched by specified scheduler. If not
specified, the pod will be dispatched by default scheduler.
securityContext <Object>
SecurityContext holds pod-level security attributes and common container
settings. Optional: Defaults to empty. See type description for default
values of each field.
serviceAccount <string>
DeprecatedServiceAccount is a depreciated alias for ServiceAccountName.
Deprecated: Use serviceAccountName instead.
serviceAccountName <string>
ServiceAccountName is the name of the ServiceAccount to use to run this
pod. More info:
https://kubernetes.io/docs/tasks/configure-pod-container/configure-service-account/
setHostnameAsFQDN <boolean>
shareProcessNamespace <boolean>
subdomain <string>
If specified, the fully qualified Pod hostname will be
"<hostname>.<subdomain>.<pod namespace>.svc.<cluster domain>". If not
specified, the pod will not have a domainname at all.
terminationGracePeriodSeconds <integer>
tolerations <[]Object>
If specified, the pod's tolerations.
topologySpreadConstraints <[]Object>
volumes <[]Object>
List of volumes that can be mounted by containers belonging to the pod.
More info: https://kubernetes.io/docs/concepts/storage/volumes
查看 pod.spec.containers 字段如何定义
[root@k8s01 pod]# kubectl explain pod.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object>
DESCRIPTION:
List of containers belonging to the pod. Containers cannot currently be
added or removed. There must be at least one container in a Pod. Cannot be
updated.
A single application container that you want to run within a pod.
#container 是定义在 pod 里面的,一个 pod 至少要有一个容器。
FIELDS:
args <[]string>
command <[]string>
env <[]Object>
List of environment variables to set in the container. Cannot be updated.
envFrom <[]Object>
image <string>
Docker image name. More info:
https://kubernetes.io/docs/concepts/containers/images This field is
optional to allow higher level config management to default or override
container images in workload controllers like Deployments and StatefulSets.
#image 是用来指定容器需要的镜像的
imagePullPolicy <string>
Image pull policy. One of Always, Never, IfNotPresent. Defaults to Always
if :latest tag is specified, or IfNotPresent otherwise. Cannot be updated.
More info:
https://kubernetes.io/docs/concepts/containers/images#updating-images
#镜像拉取策略,pod 是要调度到 node 节点的,那 pod 启动需要镜像,可以根据这个字段设置镜像拉取策略,支持如下三种:
#Always:不管本地是否存在镜像,都要重新拉取镜像
#Never: 从不拉取镜像
#IfNotPresent:如果本地存在,使用本地的镜像,本地不存在,从官方拉取镜像
lifecycle <Object>
Actions that the management system should take in response to container
lifecycle events. Cannot be updated.
livenessProbe <Object>
Periodic probe of container liveness. Container will be restarted if the
probe fails. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes
name <string> -required-
Name of the container specified as a DNS_LABEL. Each container in a pod
must have a unique name (DNS_LABEL). Cannot be updated.
#name 是必须字段,用来指定容器名字的
ports <[]Object>
List of ports to expose from the container. Exposing a port here gives the
system additional information about the network connections a container
uses, but is primarily informational. Not specifying a port here DOES NOT
prevent that port from being exposed. Any port which is listening on the
default "0.0.0.0" address inside a container will be accessible from the
network. Cannot be updated.
#port 是端口,属于对象列表
readinessProbe <Object>
resources <Object>
securityContext <Object>
startupProbe <Object>
stdin <boolean>
stdinOnce <boolean>
terminationMessagePath <string>
terminationMessagePolicy <string>
tty <boolean>
Whether this container should allocate a TTY for itself, also requires
'stdin' to be true. Default is false.
volumeDevices <[]Object>
volumeDevices is the list of block devices to be used by the container.
volumeMounts <[]Object>
Pod volumes to mount into the container's filesystem. Cannot be updated.
workingDir <string>
Container's working directory. If not specified, the container runtime's
default will be used, which might be configured in the container image.
查看 pod.spec.container.ports 字段如何定义
[root@k8s01 pod]# kubectl explain pod.spec.containers.ports
KIND: Pod
VERSION: v1
RESOURCE: ports <[]Object>
DESCRIPTION:
List of ports to expose from the container. Exposing a port here gives the
system additional information about the network connections a container
uses, but is primarily informational. Not specifying a port here DOES NOT
prevent that port from being exposed. Any port which is listening on the
default "0.0.0.0" address inside a container will be accessible from the
network. Cannot be updated.
ContainerPort represents a network port in a single container.
FIELDS:
containerPort <integer> -required-
Number of port to expose on the pod's IP address. This must be a valid port
number, 0 < x < 65536.
#containerPort 是必须字段, pod 中的容器需要暴露的端口。
hostIP <string>
What host IP to bind the external port to.
#将容器中的服务暴露到宿主机的端口上时,可以指定绑定的宿主机 IP。
hostPort <integer>
Number of port to expose on the host. If specified, this must be a valid
port number, 0 < x < 65536. If HostNetwork is specified, this must match
ContainerPort. Most containers do not need this.
#容器中的服务在宿主机上映射的端口
name <string>
If specified, this must be an IANA_SVC_NAME and unique within the pod. Each
named port in a pod must have a unique name. Name for the port that can be
referred to by services.
#端口的名字
protocol <string>
Protocol for port. Must be UDP, TCP, or SCTP. Defaults to "TCP".
通过资源清单创建Pod
pod-first.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod-first
labels:
app: tomcat-pod-first
spec:
containers:
- name: tomcat-first
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
# 应用资源清单文件
[root@k8s01 pod]# kubectl apply -f pod-first.yaml
pod/pod-first created
# 查看pod是否创建成功
[root@k8s01 pod]# kubectl get pods -o wide -l app=tomcat-pod-first
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 44s 10.244.236.134 k8s02 <none> <none>
#查看 pod 日志
[root@k8s01 pod]# kubectl logs pod-first
#查看 pod 里指定容器的日志
[root@k8s01 pod]# kubectl logs pod-first -c tomcat-first
#进入到刚才创建的 pod,刚才创建的 pod 名字是 pod-firs
[root@k8s01 pod]# kubectl exec -it pod-first -- /bin/bash
bash-4.4#
#假如 pod 里有多个容器,进入到 pod 里的指定容器,按如下命令:
[root@k8s01 pod]# kubectl exec -it pod-first -c tomcat-first -- /bin/bash
bash-4.4# eixt
我们上面创建的 pod 是一个自主式 pod,也就是通过 pod 创建一个应用程序,如果 pod 出现故障停掉,那么我们通过 pod 部署的应用也就会停掉,不安全, 还有一种控制器管理的 pod,通过控制器创建pod,可以对 pod 的生命周期做管理,可以定义 pod 的副本数,如果有一个 pod 意外停掉,那么会自动起来一个 pod 替代之前的 pod
通过 kubectl run 创建 Pod
[root@k8s01 pod]# kubectl run tomcat --image=tomcat:8.5-jre8-alpine --image-pull-policy='IfNotPresent' --port=8080
pod/tomcat created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
tomcat 1/1 Running 0 7s 10.244.236.135 k8s02 <none> <none>
命名空间
-
什么事命名空间
Kubernetes 支持多个虚拟集群,它们底层依赖于同一个物理集群。 这些虚拟集群被称为命名空间。
命名空间 namespace 是 k8s 集群级别的资源,可以给不同的用户、租户、环境或项目创建对应的命名空间,例如,可以为 test、devlopment、production 环境分别创建各自的命名空间。
-
namespace应用场景
命名空间适用于存在很多跨多个团队或项目的用户的场景。对于只有几到几十个用户的集群,根本不需要创建或考虑命名空间。
-
查看名称空间及其资源对象
k8s 集群默认提供了几个名称空间用于特定目的,例如,kube-system 主要用于运行系统级资源,存放 k8s 一些组件的。而 default 则为那些未指定名称空间的资源操作提供一个默认值。
使用 kubectl get namespace 可以查看 namespace 资源,使用 kubectl describe namespace $NAME 可以查看特定的名称空间的详细信息。
-
管理 namespace 资源
namespace 资源属性较少,通常只需要指定名称即可创建,如“kubectl create namespace qa”。namespace 资源的名称仅能由字母、数字、下划线、连接线等字符组成。删除 namespace 资源会级联删除其包含的所有其他资源对象。
-
-
namespacs 使用案例分享
# 创建一个test 命名空间
[root@k8s01 pod]# kubectl create ns test
namespace/test created
# 切换命名空间
#切换命名空间后,kubectl get pods 如果不指定-n,查看的就是 kube-system 命名空间的资源了。
[root@k8s01 pod]# kubectl config set-context --current --namespace=kube-system
Context "kubernetes-admin@kubernetes" modified.
#查看哪些资源属于命名空间级别的
[root@k8s01 pod]# kubectl api-resources --namespaced=true
NAME SHORTNAMES APIVERSION NAMESPACED KIND
bindings v1 true Binding
configmaps cm v1 true ConfigMap
endpoints ep v1 true Endpoints
events ev v1 true Event
limitranges limits v1 true LimitRange
persistentvolumeclaims pvc v1 true PersistentVolumeClaim
pods po v1 true Pod
podtemplates v1 true PodTemplate
replicationcontrollers rc v1 true ReplicationController
resourcequotas quota v1 true ResourceQuota
secrets v1 true Secret
serviceaccounts sa v1 true ServiceAccount
services svc v1 true Service
controllerrevisions apps/v1 true ControllerRevision
daemonsets ds apps/v1 true DaemonSet
deployments deploy apps/v1 true Deployment
replicasets rs apps/v1 true ReplicaSet
statefulsets sts apps/v1 true StatefulSet
localsubjectaccessreviews authorization.k8s.io/v1 true LocalSubjectAccessReview
horizontalpodautoscalers hpa autoscaling/v1 true HorizontalPodAutoscaler
cronjobs cj batch/v1beta1 true CronJob
jobs batch/v1 true Job
leases coordination.k8s.io/v1 true Lease
networkpolicies crd.projectcalico.org/v1 true NetworkPolicy
networksets crd.projectcalico.org/v1 true NetworkSet
endpointslices discovery.k8s.io/v1beta1 true EndpointSlice
events ev events.k8s.io/v1 true Event
ingresses ing extensions/v1beta1 true Ingress
ingresses ing networking.k8s.io/v1 true Ingress
networkpolicies netpol networking.k8s.io/v1 true NetworkPolicy
poddisruptionbudgets pdb policy/v1beta1 true PodDisruptionBudget
rolebindings rbac.authorization.k8s.io/v1 true RoleBinding
roles rbac.authorization.k8s.io/v1 true Role
-
namespace资源限额
namespace 是命名空间,里面有很多资源,那么我们可以对命名空间资源做个限制,防止该命名空间部署的资源超过限制。
如何对 namespace 资源做限额呢?
创建namespace-quota.yaml
apiVersion: v1 kind: ResourceQuota metadata: name: mem-cpu-quota namespace: test spec: hard: requests.cpu: '2' requests.memory: 2Gi limits.cpu: '4' limits.memory: 4Gi#创建的 ResourceQuota 对象将在 test 名字空间中添加以下限制:
每个容器必须设置内存请求(memory request),内存限额(memory limit),cpu 请求(cpu
request)和 cpu 限额(cpu limit)。
所有容器的内存请求总额不得超过 2GiB。
所有容器的内存限额总额不得超过 4 GiB。
所有容器的 CPU 请求总额不得超过 2 CPU。
所有容器的 CPU 限额总额不得超过 4CPU。
#创建 pod 时候必须设置资源限额,否则创建失败,如下:
pod-test.yaml
apiVersion: v1 kind: Pod metadata: name: pod-test namespace: test labels: app: tomcat-pod-test spec: containers: - name: tomcat-test ports: - containerPort: 8080 image: tomcat:8.5-jre8-alpine imagePullPolicy: IfNotPresent resources: requests: memory: '100Mi' cpu: '500m' limits: memory: '2Gi' cpu: '2'
标签
- 什么是标签?
标签其实就一对 key/value ,被关联到对象上,比如 Pod,标签的使用我们倾向于能够表示对象的特殊特点,就是一眼就看出了这个 Pod 是干什么的,标签可以用来划分特定的对象(比如版本,服务类型等),标签可以在创建一个对象的时候直接定义,也可以在后期随时修改,每一个对象可以拥有多个标签,但是,key 值必须是唯一的。创建标签之后也可以方便我们对资源进行分组管理。如果对 pod 打标签,之后就可以使用标签来查看、删除指定的 pod。
在 k8s 中,大部分资源都可以打标签。
-
给 pod 资源打标签
# 对已经存在的 pod 打标签 [root@k8s01 pod]# kubectl label pods pod-first release=v1 pod/pod-first labeled # 查看标签是否打成功 [root@k8s01 pod]# kubectl get pods pod-first --show-labels NAME READY STATUS RESTARTS AGE LABELS pod-first 1/1 Running 0 47s app=tomcat-pod-first,release=v1 -
查看资源标签
# 查看默认名称空间下所有 pod 资源的标签 [root@k8s01 pod]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS pod-first 1/1 Running 0 2m5s app=tomcat-pod-first,release=v1 # 查看默认名称空间下指定 pod 具有的所有标签 [root@k8s01 pod]# kubectl get pods pod-first --show-labels NAME READY STATUS RESTARTS AGE LABELS pod-first 1/1 Running 0 2m34s app=tomcat-pod-first,release=v1 # 列出默认名称空间下标签 key 是 release 的 pod,不显示标签 [root@k8s01 pod]# kubectl get pods -l release NAME READY STATUS RESTARTS AGE pod-first 1/1 Running 0 2m59s #列出默认名称空间下标签 key 是 release、值是 v1 的 pod,不显示标签 [root@k8s01 pod]# kubectl get pods -l release=v1 NAME READY STATUS RESTARTS AGE pod-first 1/1 Running 0 3m15s #列出默认名称空间下标签 key 是 release 的所有 pod,并打印对应的标签值 [root@k8s01 pod]# kubectl get pods -L release NAME READY STATUS RESTARTS AGE RELEASE pod-first 1/1 Running 0 3m38s v1 #查看所有名称空间下的所有 pod 的标签 [root@k8s01 pod]# kubectl get pods --all-namespaces --show-labels NAMESPACE NAME READY STATUS RESTARTS AGE LABELS default pod-first 1/1 Running 0 8m2s app=tomcat-pod-first,release=v1 kube-system calico-kube-controllers-6949477b58-vpvbz 1/1 Running 0 6h30m k8s-app=calico-kube-controllers,pod-template-hash=6949477b58 kube-system calico-node-fw9q4 1/1 Running 0 6h30m controller-revision-hash=8595d65b74,k8s-app=calico-node,pod-template-generation=1 kube-system calico-node-jqfpf 1/1 Running 0 6h30m controller-revision-hash=8595d65b74,k8s-app=calico-node,pod-template-generation=1 kube-system calico-node-tgl5k 1/1 Running 0 6h30m controller-revision-hash=8595d65b74,k8s-app=calico-node,pod-template-generation=1 kube-system coredns-7f89b7bc75-c5246 1/1 Running 0 6h37m k8s-app=kube-dns,pod-template-hash=7f89b7bc75 kube-system coredns-7f89b7bc75-j9nlr 1/1 Running 0 6h37m k8s-app=kube-dns,pod-template-hash=7f89b7bc75 kube-system etcd-k8s01 1/1 Running 0 6h37m component=etcd,tier=control-plane kube-system kube-apiserver-k8s01 1/1 Running 0 6h37m component=kube-apiserver,tier=control-plane kube-system kube-controller-manager-k8s01 1/1 Running 0 6h37m component=kube-controller-manager,tier=control-plane kube-system kube-proxy-b7bvs 1/1 Running 0 6h37m controller-revision-hash=6fb4b4fd8f,k8s-app=kube-proxy,pod-template-generation=1 kube-system kube-proxy-gr9f8 1/1 Running 0 6h33m controller-revision-hash=6fb4b4fd8f,k8s-app=kube-proxy,pod-template-generation=1 kube-system kube-proxy-m7jzg 1/1 Running 0 6h35m controller-revision-hash=6fb4b4fd8f,k8s-app=kube-proxy,pod-template-generation=1 kube-system kube-scheduler-k8s01 1/1 Running 0 6h37m component=kube-scheduler,tier=control-plane #列出默认名称空间下标签 key 是 release、值是 v1 的 pod,显示标签 [root@k8s01 pod]# kubectl get pods -l release=v1 -L release NAME READY STATUS RESTARTS AGE RELEASE pod-first 1/1 Running 0 8m45s v1
Pod资源清单详细解读
apiVersion: v1 #版本号,例如 v1
kind: Pod #资源类型,如 Pod
metadata:
name: string # Pod 名字
namespace: string # Pod 所属的命名空间
labels: #自定义标签
name: string #自定义标签名字
annotations: #自定义注释列表
name: string
spec: # Pod 中容器的详细定义
containers: # Pod 中容器列表
- name: string #容器名称
image: string #容器的镜像名称
imagePullPolicy: [Always | Never | IfNotPresent] #获取镜像的策略 Alawys 表示下载镜像 IfnotPresent 表示优先使用本地镜像,否则下载镜像,Nerver 表示仅使用本地镜像
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器的启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器内部的存储卷配置
- mountPath: string #存储卷在容器内 mount 的绝对路径,应少于 512 字符
name: string #引用 pod 定义的共享存储卷的名称,需用 volumes[]部分定义的的卷名
readOnly: boolean #是否为只读模式
ports: #需要暴露的端口号
- containerPort: int #容器需要监听的端口号
name: string #端口号名称
hostIP: string
hostPort: int #容器所在主机需要监听的端口号,默认与 Container 相同
protocol: string #端口协议,支持 TCP 和 UDP,默认 TCP
env: #容器运行前需设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #资源限制的设置
cpu: string #cpu 的限制,单位为 core 数
memory: string #内存限制,单位可以为 Mib/Gib
requests: #资源请求的设置
cpu: string #cpu 请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的初始可用内存
livenessProbe: #对 Pod 内个容器健康检查的设置,当探测无响应几次后将自动重启该容器,检查方法有 exec、httpGet 和 tcpSocket,对一个容器只需设置其中一种方法即可
exec: #对 Pod 容器内检查方式设置为 exec 方式
command: [string] #exec 方式需要制定的命令或脚本
httpGet: #对 Pod 内个容器健康检查方法设置为 HttpGet,需要制定 Path、port
port: number
path: string
host: string
scheme: string
httpHeaders:
- name: string
value: string
tcpSocket: #对 Pod 内个容器健康检查方式设置为 tcpSocket 方式
port: number
initialDelaySeconds: 0 #容器启动完成后首次探测的时间,单位为秒
timeoutSeconds: 0 #对容器健康检查探测等待响应的超时时间,单位秒,默认 1 秒
periodSeconds: 0 #对容器监控检查的定期探测时间设置,单位秒,默认 10 秒一次
successThreshold: 0
failureThreshold: 0
securityContext:
privileged: false
restartPolicy: [Always | Never | OnFailure] #Pod 的重启策略,Always 表示一旦不管以何种方式终止运行,kubelet 都将重启,OnFailure 表示只有 Pod 以非 0 退出码退出才重启,Nerver 表示不再重启该 Pod
nodeSelector: object #设置 NodeSelector 表示将该 Pod 调度到包含这个 label 的 node上,以 key:value 的格式指定
imagePullSecrets: #Pull 镜像时使用的 secret 名称,以 key:secretkey 格式指定
- name: string
hostNetwork: false #是否使用主机网络模式,默认为 false,如果设置为 true,表示使用宿主机网络
volumes: #在该 pod 上定义共享存储卷列表
- name: string #共享存储卷名称 (volumes 类型有很多种)
emptyDir: {} #类型为 emtyDir 的存储卷,与 Pod 同生命周期的一个临时目录。为空值
hostPath: #类型为 hostPath 的存储卷,表示挂载 Pod 所在宿主机的目录
path: string #Pod 所在宿主机的目录,将被用于同期中 mount 的目录
secret: #类型为 secret 的存储卷,挂载集群与定义的 secre 对象到容器内部
secretName: string
items:
- key: string
path: string
configMap: #类型为 configMap 的存储卷,挂载预定义的 configMap 对象到容器内部
name: string
items:
- key: string
path: string
Node节点选择器
我们在创建 pod 资源的时候,pod 会根据 schduler 进行调度,那么默认会调度到随机的一个工作节点,如果我们想要 pod 调度到指定节点或者调度到一些具有相同特点的 node 节点,怎么办呢?可以使用 pod 中的 nodeName 或者 nodeSelector 字段指定要调度到的 node 节点
-
nodeName
指定 pod 节点运行在哪个具体 node 上
编写pod-node.yaml
apiVersion: v1 kind: Pod metadata: name: demo-pod namespace: default labels: app: myapp env: dev spec: nodeName: k8s02 containers: - name: tomcat-pod-java image: tomcat:8.5-jre8-alpine imagePullPolicy: IfNotPresent - name: busybox image: busybox:latest command: - "/bin/sh" - "-c" - "sleep 3600"# 应用资源清单文件 [root@k8s01 pod]# kubectl apply -f pod-node.yaml pod/demo-pod created # 查看pod调度到了哪个节点 [root@k8s01 pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES demo-pod 2/2 Running 0 14s 10.244.236.137 k8s02 <none> <none> -
nodeSelector
指定 pod 调度到具有哪些标签的 node 节点上
#给 node 节点打标签,打个具有 disk=ceph 的标签 [root@k8s01 pod]# kubectl label nodes k8s03 disk=ceph node/k8s03 labeled#定义 pod 的时候指定要调度到具有 disk=ceph 标签的 node 上
pod-1.yaml
apiVersion: v1 kind: Pod metadata: name: demo-pod-1 namespace: default labels: app: myapp env: dev spec: nodeSelector: disk: ceph containers: - name: tomcat-pod-java ports: - containerPort: 8080 image: tomcat:8.5-jre8-alpine imagePullPolicy: IfNotPresent# 应用资源清单文件 [root@k8s01 pod]# kubectl apply -f pod-1.yaml pod/demo-pod-1 created # 查看pod调度到了哪个节点 [root@k8s01 pod]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES demo-pod-1 1/1 Running 0 10s 10.244.235.134 k8s03 <none> <none>
亲和性
[root@k8s01 pod]# kubectl explain pods.spec.affinity
KIND: Pod
VERSION: v1
RESOURCE: affinity <Object>
DESCRIPTION:
If specified, the pod's scheduling constraints
Affinity is a group of affinity scheduling rules.
FIELDS:
nodeAffinity <Object>
Describes node affinity scheduling rules for the pod.
podAffinity <Object>
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
podAntiAffinity <Object>
Describes pod anti-affinity scheduling rules (e.g. avoid putting this pod
in the same node, zone, etc. as some other pod(s)).
node 节点亲和性
node 节点亲和性调度:nodeAffinity
[root@k8s01 pod]# kubectl explain pods.spec.affinity.nodeAffinity
KIND: Pod
VERSION: v1
RESOURCE: nodeAffinity <Object>
DESCRIPTION:
Describes node affinity scheduling rules for the pod.
Node affinity is a group of node affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
The scheduler will prefer to schedule pods to nodes that satisfy the
affinity expressions specified by this field, but it may choose a node that
violates one or more of the expressions. The node that is most preferred is
the one with the greatest sum of weights, i.e. for each node that meets all
of the scheduling requirements (resource request, requiredDuringScheduling
affinity expressions, etc.), compute a sum by iterating through the
elements of this field and adding "weight" to the sum if the node matches
the corresponding matchExpressions; the node(s) with the highest sum are
the most preferred.
#prefered 表示有节点尽量满足这个位置定义的亲和性,这不是一个必须的条件,软亲和性
requiredDuringSchedulingIgnoredDuringExecution <Object>
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to an update), the system may or may not try
to eventually evict the pod from its node.
# require 表示必须有节点满足这个位置定义的亲和性,这是个硬性条件,硬亲和性
preferredDuringSchedulingIgnoredDuringExecution
[root@k8s01 pod]# kubectl explain pods.spec.affinity.nodeAffinity.preferredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: preferredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
The scheduler will prefer to schedule pods to nodes that satisfy the
affinity expressions specified by this field, but it may choose a node that
violates one or more of the expressions. The node that is most preferred is
the one with the greatest sum of weights, i.e. for each node that meets all
of the scheduling requirements (resource request, requiredDuringScheduling
affinity expressions, etc.), compute a sum by iterating through the
elements of this field and adding "weight" to the sum if the node matches
the corresponding matchExpressions; the node(s) with the highest sum are
the most preferred.
An empty preferred scheduling term matches all objects with implicit weight
0 (i.e. it's a no-op). A null preferred scheduling term matches no objects
(i.e. is also a no-op).
FIELDS:
preference <Object> -required-
A node selector term, associated with the corresponding weight.
weight <integer> -required-
Weight associated with matching the corresponding nodeSelectorTerm, in the
range 1-100.
requiredDuringSchedulingIgnoredDuringExecution
[root@k8s01 pod]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <Object>
DESCRIPTION:
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to an update), the system may or may not try
to eventually evict the pod from its node.
A node selector represents the union of the results of one or more label
queries over a set of nodes; that is, it represents the OR of the selectors
represented by the node selector terms.
FIELDS:
nodeSelectorTerms <[]Object> -required-
Required. A list of node selector terms. The terms are ORed.
nodeSelectorTerms
[root@k8s01 pod]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms
KIND: Pod
VERSION: v1
RESOURCE: nodeSelectorTerms <[]Object>
DESCRIPTION:
Required. A list of node selector terms. The terms are ORed.
A null or empty node selector term matches no objects. The requirements of
them are ANDed. The TopologySelectorTerm type implements a subset of the
NodeSelectorTerm.
FIELDS:
matchExpressions <[]Object>
A list of node selector requirements by node's labels.
#匹配表达式的
matchFields <[]Object>
A list of node selector requirements by node's fields.
# 匹配字段的
matchExpressions
[root@k8s01 pod]# kubectl explain pods.spec.affinity.nodeAffinity.requiredDuringSchedulingIgnoredDuringExecution.nodeSelectorTerms.matchExpressions
KIND: Pod
VERSION: v1
RESOURCE: matchExpressions <[]Object>
DESCRIPTION:
A list of node selector requirements by node's labels.
A node selector requirement is a selector that contains values, a key, and
an operator that relates the key and values.
FIELDS:
key <string> -required-
The label key that the selector applies to.
# 检查 label
operator <string> -required-
Represents a key's relationship to a set of values. Valid operators are In,
NotIn, Exists, DoesNotExist. Gt, and Lt.
# 做等值选则还是不等值选则
values <[]string>
An array of string values. If the operator is In or NotIn, the values array
must be non-empty. If the operator is Exists or DoesNotExist, the values
array must be empty. If the operator is Gt or Lt, the values array must
have a single element, which will be interpreted as an integer. This array
is replaced during a strategic merge patch.
# 给定值
例 1:使用 requiredDuringSchedulingIgnoredDuringExecution 硬亲和性
#把 myapp-v1.tar.gz 上传到 k8s02 和 k8s03 上,手动解压:
pod-nodeaffinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: zone
operator: In
values:
- foo
- bar
我们检查当前节点中有任意一个节点拥有 zone 标签的值是 foo 或者 bar,就可以把 pod 调度到这个 node 节点上
[root@k8s01 pod]# kubectl apply -f pod-nodeaffinity-demo.yaml
pod/pod-node-affinity-demo created
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-node-affinity-demo 0/1 Pending 0 23s
status 的状态是 pending,上面说明没有完成调度,因为没有一个拥有 zone 的标签的值是 foo 或者 bar,而且使用的是硬亲和性,必须满足条件才能完成调度
[root@k8s01 pod]# kubectl label nodes k8s03 zone=bar
node/k8s03 labeled
# 给这个 xianchaonode1 节点打上标签 zone=bar,在查看
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-node-affinity-demo 1/1 Running 0 4m32s
例 2:使用 preferredDuringSchedulingIgnoredDuringExecution 软亲和性
pod-nodeaffinity-demo-2.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-node-affinity-demo-2
namespace: default
labels:
app: myapp
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- preference:
matchExpressions:
- key: zone
operator: In
values:
- bar1
- foo1
weight: 60
[root@k8s01 pod]# kubectl apply -f pod-nodeaffinity-demo-2.yaml
pod/pod-node-affinity-demo-2 created
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
pod-node-affinity-demo-2 1/1 Running 0 3s
上面说明软亲和性是可以运行这个 pod 的,尽管没有运行这个 pod 的节点定义的 zone1 标签
Node 节点亲和性针对的是 pod 和 node 的关系,Pod 调度到 node 节点的时候匹配的条件
pod 节点亲和性
pod 自身的亲和性调度有两种表示形式
podaffinity:pod 和 pod 更倾向腻在一起,把相近的 pod 结合到相近的位置,如同一区域,同一机架,这样的话 pod 和 pod 之间更好通信,比方说有两个机房,这两个机房部署的集群有 1000 台主机,那么我们希望把 nginx 和 tomcat 都部署同一个地方的 node 节点上,可以提高通信效率;
podunaffinity:pod 和 pod 更倾向不腻在一起,如果部署两套程序,那么这两套程序更倾向于反亲和性,这样相互之间不会有影响。
第一个 pod 随机选则一个节点,做为评判后续的 pod 能否到达这个 pod 所在的节点上的运行方式,这就称为 pod 亲和性;我们怎么判定哪些节点是相同位置的,哪些节点是不同位置的;我们在定义 pod 亲和性时需要有一个前提,哪些 pod 在同一个位置,哪些 pod 不在同一个位置,这个位置是怎么定义的,标准是什么?以节点名称为标准,这个节点名称相同的表示是同一个位置,节点名称不相同的表示不是一个位置。
podAffinity
[root@k8s01 pod]# kubectl explain pods.spec.affinity.podAffinity
KIND: Pod
VERSION: v1
RESOURCE: podAffinity <Object>
DESCRIPTION:
Describes pod affinity scheduling rules (e.g. co-locate this pod in the
same node, zone, etc. as some other pod(s)).
Pod affinity is a group of inter pod affinity scheduling rules.
FIELDS:
preferredDuringSchedulingIgnoredDuringExecution <[]Object>
The scheduler will prefer to schedule pods to nodes that satisfy the
affinity expressions specified by this field, but it may choose a node that
violates one or more of the expressions. The node that is most preferred is
the one with the greatest sum of weights, i.e. for each node that meets all
of the scheduling requirements (resource request, requiredDuringScheduling
affinity expressions, etc.), compute a sum by iterating through the
elements of this field and adding "weight" to the sum if the node has pods
which matches the corresponding podAffinityTerm; the node(s) with the
highest sum are the most preferred.
requiredDuringSchedulingIgnoredDuringExecution <[]Object>
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to a pod label update), the system may or
may not try to eventually evict the pod from its node. When there are
multiple elements, the lists of nodes corresponding to each podAffinityTerm
are intersected, i.e. all terms must be satisfied.
requiredDuringSchedulingIgnoredDuringExecution: 硬亲和性
preferredDuringSchedulingIgnoredDuringExecution:软亲和性
requiredDuringSchedulingIgnoredDuringExecution
[root@k8s01 pod]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution
KIND: Pod
VERSION: v1
RESOURCE: requiredDuringSchedulingIgnoredDuringExecution <[]Object>
DESCRIPTION:
If the affinity requirements specified by this field are not met at
scheduling time, the pod will not be scheduled onto the node. If the
affinity requirements specified by this field cease to be met at some point
during pod execution (e.g. due to a pod label update), the system may or
may not try to eventually evict the pod from its node. When there are
multiple elements, the lists of nodes corresponding to each podAffinityTerm
are intersected, i.e. all terms must be satisfied.
Defines a set of pods (namely those matching the labelSelector relative to
the given namespace(s)) that this pod should be co-located (affinity) or
not co-located (anti-affinity) with, where co-located is defined as running
on a node whose value of the label with key <topologyKey> matches that of
any node on which a pod of the set of pods is running
FIELDS:
labelSelector <Object>
A label query over a set of resources, in this case pods.
# 我们要判断 pod 跟别的 pod 亲和,跟哪个 pod 亲和,需要靠 labelSelector,通过 labelSelector选则一组能作为亲和对象的 pod 资源
namespaces <[]string>
namespaces specifies which namespaces the labelSelector applies to (matches
against); null or empty list means "this pod's namespace"
#labelSelector 需要选则一组资源,那么这组资源是在哪个名称空间中呢,通过 namespace 指定,如果不指定 namespaces,那么就是当前创建 pod 的名称空间
topologyKey <string> -required-
This pod should be co-located (affinity) or not co-located (anti-affinity)
with the pods matching the labelSelector in the specified namespaces, where
co-located is defined as running on a node whose value of the label with
key topologyKey matches that of any node on which any of the selected pods
is running. Empty topologyKey is not allowed.
#位置拓扑的键,这个是必须字段 ,怎么判断是不是同一个位置:
#rack=rack1
#row=row1
#使用 rack 的键是同一个位置 ,使用 row 的键是同一个位置
labelSelector
[root@k8s01 pod]# kubectl explain pods.spec.affinity.podAffinity.requiredDuringSchedulingIgnoredDuringExecution.labelSelector
KIND: Pod
VERSION: v1
RESOURCE: labelSelector <Object>
DESCRIPTION:
A label query over a set of resources, in this case pods.
A label selector is a label query over a set of resources. The result of
matchLabels and matchExpressions are ANDed. An empty label selector matches
all objects. A null label selector matches no objects.
FIELDS:
matchExpressions <[]Object>
matchExpressions is a list of label selector requirements. The requirements
are ANDed.
matchLabels <map[string]string>
matchLabels is a map of {key,value} pairs. A single {key,value} in the
matchLabels map is equivalent to an element of matchExpressions, whose key
field is "key", the operator is "In", and the values array contains only
"value". The requirements are ANDed.
例 1:pod 节点亲和性
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟着它走
pod-required-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod-first
labels:
app2: myapp2
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
---
apiVersion: v1
kind: Pod
metadata:
name: pod-second
namespace: default
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command: [ 'sh','-c','sleep 3600' ]
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app2
operator: In
values:
- myapp2
#上面表示创建的 pod 必须与拥有 app2=myapp2 标签的 pod 在一个节点上
[root@k8s01 pod]# kubectl apply -f pod-required-affinity-demo.yaml
pod/pod-first created
pod/pod-second created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 11s 10.244.236.139 k8s02 <none> <none>
pod-second 1/1 Running 0 11s 10.244.236.140 k8s02 <none> <none>
上面说明第一个 pod 调度到哪,第二个 pod 也调度到哪,这就是 pod 节点亲和性
例 2:pod 节点反亲和性
定义两个 pod,第一个 pod 做为基准,第二个 pod 跟它调度节点相反
pod-required-anti-affinity-demo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
namespace: default
labels:
app1: myapp1
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
---
apiVersion: v1
kind: Pod
metadata:
namespace: default
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: busybox
image: busybox:latest
imagePullPolicy: IfNotPresent
command:
- 'sh'
- '-c'
- 'sleep 3600'
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchExpressions:
- key: app1
operator: In
values:
- myapp1
[root@k8s01 pod]# kubectl apply -f pod-required-anti-affinity-demo.yaml
pod/pod-first created
pod/pod-second created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 18s 10.244.236.141 k8s02 <none> <none>
pod-second 1/1 Running 0 18s 10.244.235.136 k8s03 <none> <none>
显示两个 pod 不在一个 node 节点上,这就是 pod 节点反亲和性
例 3:换一个 topologykey
[root@k8s01 pod]# kubectl label nodes k8s02 zone=foo --overwrite
node/k8s02 labeled
[root@k8s01 pod]# kubectl label nodes k8s03 zone=foo --overwrite
node/k8s03 labeled
pod-first-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-first
labels:
app3: myapp3
tier: frontend
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
imagePullPolicy: IfNotPresent
pod-second-required-anti-affinity-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-second
labels:
app: backend
tier: db
spec:
containers:
- name: myapp
image: busybox:latest
imagePullPolicy: IfNotPresent
command:
- 'sh'
- '-c'
- 'sleep 3600'
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: zone
labelSelector:
matchExpressions:
- key: app3
operator: In
values:
- myapp3
[root@k8s01 pod]# kubectl apply -f pod-first-required-anti-affinity-demo-1.yaml
pod/pod-first created
[root@k8s01 pod]# kubectl apply -f pod-second-required-anti-affinity-demo-1.yaml
pod/pod-second created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
pod-first 1/1 Running 0 117s 10.244.236.142 k8s02 <none> <none>
pod-second 0/1 Pending 0 111s <none> <none> <none> <none>
第二个节点现是 pending,因为两个节点是同一个位置,现在没有不是同一个位置的了,而且我们要求反亲和性,所以就会处于 pending 状态,如果在反亲和性这个位置把 required 改成preferred,那么也会运行。
podaffinity:pod 节点亲和性,pod 倾向于哪个 pod
nodeaffinity:node 节点亲和性,pod 倾向于哪个 node
污点和容忍度
给了节点选则的主动权,我们给节点打一个污点,不容忍的 pod 就运行不上来,污点就是定义在节点上的键值属性数据,可以定决定拒绝那些 pod;
taints 是键值数据,用在节点上,定义污点;
tolerations 是键值数据,用在 pod 上,定义容忍度,能容忍哪些污点
pod 亲和性是 pod 属性;但是污点是节点的属性,污点定义在 nodeSelector 上
[root@k8s01 pod]# kubectl describe nodes k8s01
......
Taints: node-role.kubernetes.io/master:NoSchedule
......
[root@k8s01 pod]# kubectl explain node.spec.taints
KIND: Node
VERSION: v1
RESOURCE: taints <[]Object>
DESCRIPTION:
If specified, the node's taints.
The node this Taint is attached to has the "effect" on any pod that does
not tolerate the Taint.
FIELDS:
effect <string> -required-
Required. The effect of the taint on pods that do not tolerate the taint.
Valid effects are NoSchedule, PreferNoSchedule and NoExecute.
key <string> -required-
Required. The taint key to be applied to a node.
timeAdded <string>
TimeAdded represents the time at which the taint was added. It is only
written for NoExecute taints.
value <string>
The taint value corresponding to the taint key
taints 的 effect 用来定义对 pod 对象的排斥等级(效果):
NoSchedule:
仅影响 pod 调度过程,当 pod 能容忍这个节点污点,就可以调度到当前节点,后来这个节点的污点改了,加了一个新的污点,使得之前调度的 pod 不能容忍了,那这个 pod 会怎么处理,对现存的 pod 对象不产生影响
NoExecute:
既影响调度过程,又影响现存的 pod 对象,如果现存的 pod 不能容忍节点后来加的污点,这个 pod就会被驱逐
PreferNoSchedule:
最好不,也可以,是 NoSchedule 的柔性版本
在 pod 对象定义容忍度的时候支持两种操作:
-
等值密钥:key 和 value 上完全匹配
-
存在性判断:key 和 effect 必须同时匹配,value 可以是空
在 pod 上定义的容忍度可能不止一个,在节点上定义的污点可能多个,需要琢个检查容忍度和污点能否匹配,每一个污点都能被容忍,才能完成调度,如果不能容忍怎么办,那就需要看 pod 的容忍度了
查看 master 这个节点是否有污点,显示如下:
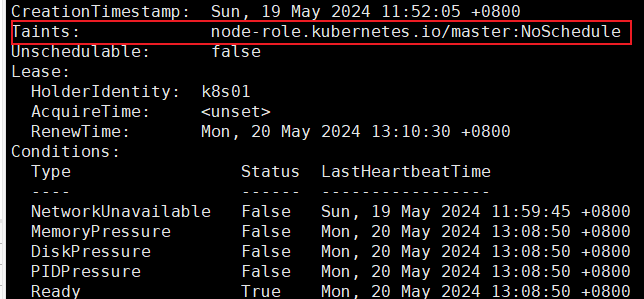
上面可以看到 master 这个节点的污点是 Noschedule
所以我们创建的 pod 都不会调度到 master 上,因为我们创建的 pod 没有容忍度
[root@k8s01 pod]# kubectl describe pods kube-apiserver-k8s01 -n kube-system

可以看到这个 pod 的容忍度是 NoExecute,则可以调度到 k8s01上
管理节点污点
[root@k8s01 pod]# kubectl taint --help
例 1:把 k8s03 当成是生产环境专用的,其他 node 是测试的
[root@k8s01 pod]# kubectl taint node k8s03 node-type=production:NoSchedule
node/k8s03 tainted
给 k8s03 打污点,pod 如果不能容忍就不会调度过来)
pod-taint.yaml
apiVersion: v1
kind: Pod
metadata:
name: taint-pod
namespace: default
labels:
tomcat: tomcat-pod
spec:
containers:
- name: taint-pod
ports:
- containerPort: 8080
image: tomcat:8.5-jre8-alpine
imagePullPolicy: IfNotPresent
[root@k8s01 pod]# kubectl apply -f pod-taint.yaml
pod/taint-pod created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-pod 1/1 Running 0 7s 10.244.236.144 k8s02 <none> <none>
可以看到都被调度到 k8s02 上了,因为 k8s03 这个节点打了污点,而我们在创建 pod 的时候没有容忍度,所以 k8s03 上不会有 pod 调度上去的
例 2:给 xianchaonode1 也打上污点
[root@k8s01 pod]# kubectl taint node k8s02 node-type=dev:NoExecute
node/k8s02 tainted
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
taint-pod 0/1 Terminating 0 30s 10.244.236.145 k8s02 <none> <none>
上面可以看到已经存在的 pod 节点都被撵走了
pod-demo-1.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-deploy
namespace: default
labels:
app: myapp
release: canary
spec:
containers:
- name: myapp
image: ikubernetes/myapp:v1
ports:
- containerPort: 80
name: http
tolerations:
- key: node-type
operator: Equal
value: production
effect: NoExecute
tolerationSeconds: 3600
[root@k8s01 pod]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-deploy 0/1 Pending 0 3s
还是显示 pending,因为我们使用的是 equal(等值匹配),所以 key 和 value,effect 必须和node 节点定义的污点完全匹配才可以,把上面配置 effect: "NoExecute"变成effect: “NoSchedule”;tolerationSeconds: 3600 这行去掉
[root@k8s01 pod]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 1/1 Running 0 5s 10.244.235.137 k8s03 <none> <none>
上面就可以调度到 k8s03上了,因为在 pod 中定义的容忍度能容忍 node 节点上的污点
例 3:再次修改
修改如下部分:
tolerations:
- key: node-type
operator: Exists
value: ""
effect: NoExecute
只要对应的键是存在的,exists,其值被自动定义成通配符
[root@k8s01 pod]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 1/1 Running 0 6s 10.244.235.138 k8s03 <none> <none>
发现还是调度到 xianchaonode2 上
再次修改:
tolerations:
- key: node-type
operator: Exists
value: ''
effect: ''
有一个 node-type 的键,不管值是什么,不管是什么效果,都能容忍
[root@k8s01 pod]# kubectl apply -f pod-demo-1.yaml
pod/myapp-deploy created
[root@k8s01 pod]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
myapp-deploy 1/1 Running 0 7s 10.244.236.146 k8s02 <none> <none>
可以看到 k8s03 和 k8s02 节点上都有可能有 pod 被调度
删除污点:
[root@k8s01 pod]# kubectl taint nodes k8s02 node-type:NoExecute-
node/k8s02 untainted
[root@k8s01 pod]# kubectl taint nodes k8s03 node-type-
node/k8s03 untainted
Pod 常见的状态和重启策略
常见的 pod 状态
Pod 的 status 定义在 PodStatus 对象中,其中有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。熟悉 Pod 的各种状态对我们理解如何设置 Pod 的调度策略、重启策略是很有必要的。下面是 phase 可能的值,也就是 pod 常见的状态:
挂起(Pending):我们在请求创建 pod 时,条件不满足,调度没有完成,没有任何一个节点能满足调度条件,已经创建了 pod 但是没有适合它运行的节点叫做挂起,调度没有完成,处于 pending的状态会持续一段时间:包括调度 Pod 的时间和通过网络下载镜像的时间。
运行中(Running):Pod 已经绑定到了一个节点上,Pod 中所有的容器都已被创建。至少有一个容器正在运行,或者正处于启动或重启状态。
成功(Succeeded):Pod 中的所有容器都被成功终止,并且不会再重启。
失败(Failed):Pod 中的所有容器都已终止了,并且至少有一个容器是因为失败终止。也就是说,容器以非 0 状态退出或者被系统终止
未知(Unknown):未知状态,所谓 pod 是什么状态是 apiserver 和运行在 pod 节点的 kubelet 进行通信获取状态信息的,如果节点之上的 kubelet 本身出故障,那么 apiserver 就连不上kubelet,得不到信息了,就会看 Unknown
扩展:还有其他状态,如下:
Evicted 状态:出现这种情况,多见于系统内存或硬盘资源不足,可 df-h 查看 docker 存储所在目录的资源使用情况,如果百分比大于 85%,就要及时清理下资源,尤其是一些大文件、docker 镜像。
CrashLoopBackOff:容器曾经启动了,但可能又异常退出了
Error 状态:Pod 启动过程中发生了错误
pod 重启策略
Pod 的重启策略(RestartPolicy)应用于 Pod 内的所有容器,并且仅在 Pod 所处的 Node 上由kubelet 进行判断和重启操作。当某个容器异常退出或者健康检查失败时,kubelet 将根据RestartPolicy 的设置来进行相应的操作。
Pod 的重启策略包括 Always、OnFailure 和 Never,默认值为 Always。
Always:当容器失败时,由 kubelet 自动重启该容器。
OnFailure:当容器终止运行且退出码不为 0 时,由 kubelet 自动重启该容器。
Never:不论容器运行状态如何,kubelet 都不会重启该容器。
pod.yaml
apiVersion: v1
kind: Pod
metadata:
name: demo-pod
namespace: default
labels:
app: myapp
spec:
restartPolicy: Always
containers:
- name: tomcat-pod-java
image: tomcat:8.5-jre8-alpine
ports:
- containerPort: 8080
imagePullPolicy: IfNotPresent
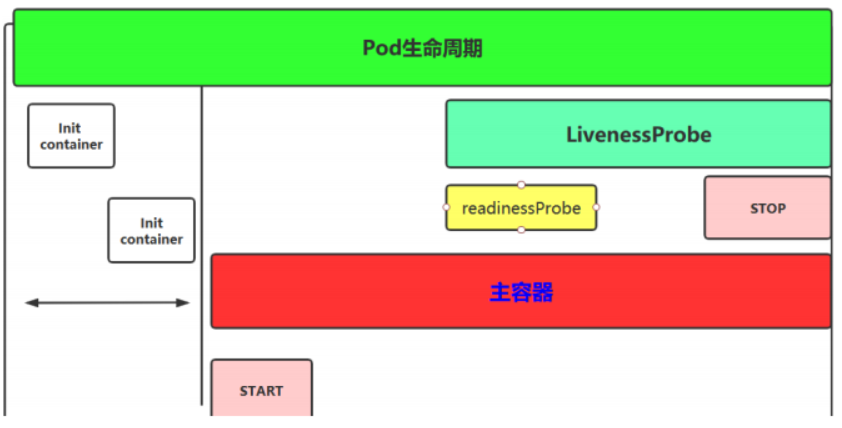
Pod 生命周期
Init 容器
Pod 里面可以有一个或者多个容器,部署应用的容器可以称为主容器,在创建 Pod 时候,Pod 中可以有一个或多个先于主容器启动的 Init 容器,这个 init 容器就可以成为初始化容器,初始化容器一旦执行完,它从启动开始到初始化代码执行完就退出了,它不会一直存在,所以在主容器启动之前执行初始化,初始化容器可以有多个,多个初始化容器是要串行执行的,先执行初始化容器 1,在执行初始化容器 2 等,等初始化容器执行完初始化就退出了,然后再执行主容器,主容器一退出,pod 就结束了,主容器退出的时间点就是 pod 的结束点,它俩时间轴是一致的;
Init 容器就是做初始化工作的容器。可以有一个或多个,如果多个按照定义的顺序依次执行,只有所有的初始化容器执行完后,主容器才启动。由于一个 Pod 里的存储卷是共享的,所以 Init Container 里产生的数据可以被主容器使用到,Init Container 可以在多种 K8S 资源里被使用到,如 Deployment、DaemonSet, StatefulSet、Job 等,但都是在 Pod 启动时,在主容器启动前执行,做初始化工作。
Init 容器与普通的容器区别是:
- Init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成
- 每个 Init 容器必须运行成功,下一个才能够运行
- 如果 Pod 的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止,然而,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动。
初始化容器的官方地址:
https://kubernetes.io/docs/concepts/workloads/pods/init-containers/#init-containers-in-use
init.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox:1.28
command:
- 'sh'
- '-c'
- 'echo The app is running! && sleep 3600'
initContainers:
- name: init-myservice
image: busybox:1.28
command:
- 'sh'
- '-c'
- 'until nslookup myservice.$(cat
/var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do
echo waiting for myservice; sleep 2; done'
- name: init-mydb
image: busybox:1.28
command:
- 'sh'
- '-c'
- 'until nslookup mydb.$(cat
/var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do
echo waiting for mydb; sleep 2; done'
[root@k8s01 pod]# kubectl apply -f init.yaml
pod/myapp-pod created
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-pod 0/1 Init:0/2 0 4s
上面需要进行service才能运行成功
service.yaml
apiVersion: v1
kind: Service
metadata:
name: myservice
spec:
ports:
- port: 80
protocol: TCP
targetPort: 9376
---
apiVersion: v1
kind: Service
metadata:
name: mydb
spec:
ports:
- port: 80
protocol: TCP
targetPort: 9377
[root@k8s01 pod]# kubectl apply -f service.yaml
service/myservice created
service/mydb created
[root@k8s01 pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
myapp-pod 1/1 Running 0 3m20s
主容器
容器钩子
初始化容器启动之后,开始启动主容器,在主容器启动之前有一个 post start hook(容器启动后钩子)和 pre stop hook(容器结束前钩子),无论启动后还是结束前所做的事我们可以把它放两个钩子,这个钩子就表示用户可以用它来钩住一些命令,来执行它,做开场前的预设,结束前的清理,如 awk 有 begin,end,和这个效果类似;
postStart:该钩子在容器被创建后立刻触发,通知容器它已经被创建。如果该钩子对应的 hook handler 执行失败,则该容器会被杀死,并根据该容器的重启策略决定是否要重启该容器,这个钩子不需要传递任何参数。
preStop:该钩子在容器被删除前触发,其所对应的 hook handler 必须在删除该容器的请求发送给 Docker daemon 之前完成。在该钩子对应的 hook handler 完成后不论执行的结果如何,Docker daemon 会发送一个 SGTERN 信号量给 Docker daemon 来删除该容器,这个钩子不需要传递任何参数。
在 k8s 中支持两类对 pod 的检测,第一类叫做 livenessprobe(pod 存活性探测):
存活探针主要作用是,用指定的方式检测 pod 中的容器应用是否正常运行,如果检测失败,则认为容器不健康,那么 Kubelet 将根据 Pod 中设置的 restartPolicy 来判断 Pod 是否要进行重启操作,如果容器配置中没有配置 livenessProbe,Kubelet 将认为存活探针探测一直为成功状态。
第二类是状态检 readinessprobe(pod 就绪性探测):
用于判断容器中应用是否启动完成,当探测成功后才使 Pod 对外提供网络访问,设置容器 Ready 状态为 true,如果探测失败,则设置容器的Ready 状态为 false。
创建 pod 需要经过的阶段
当用户创建 pod 时,这个请求给 apiserver,apiserver 把创建请求的状态保存在 etcd 中;接下来 apiserver 会请求 scheduler 来完成调度,如果调度成功,会把调度的结果(如调度到哪个节点上了,运行在哪个节点上了,把它更新到 etcd 的 pod 资源状态中)保存在 etcd 中,一旦存到 etcd 中并且完成更新以后,如调度到 k8s02 上,那么 k8s02 节点上的kubelet 通过 apiserver 当中的状态变化知道有一些任务被执行了,所以此时此 kubelet 会拿到用户创建时所提交的清单,这个清单会在当前节点上运行或者启动这个 pod,如果创建成功或者失败会有一个当前状态,当前这个状态会发给 apiserver,apiserver 在存到 etcd 中;在这个过程中,etcd 和 apiserver 一直在打交道,不停的交互,scheduler 也参与其中,负责调度 pod 到合适的 node 节点上,这个就是 pod 的创建过程
pod 在整个生命周期中有非常多的用户行为:
- 初始化容器完成初始化
- 主容器启动后可以做启动后钩子
- 主容器结束前可以做结束前钩子
- 在主容器运行中可以做一些健康检测,如 liveness probe,readness probe
Pod 容器探测和钩子
postStart 和 preStop
postStart:容器创建成功后,运行前的任务,用于资源部署、环境准备等。
preStop:在容器被终止前的任务,用于优雅关闭应用程序、通知其他系统等。
演示 postStart 和 preStop 用法
......
containers:
- image: sample:v2
name: war
lifecycle:
postStart:
exec:
command:
- 'cp'
- '/sample.war'
- 'app'
preStop:
httpGet:
host: monitor.com
path: /waring
scheme: HTTP
port: 8080
......
以上示例中,定义了一个 Pod,包含一个 JAVA 的 web 应用容器,其中设置了 PostStart 和PreStop 回调函数。即在容器创建成功后,复制/sample.war 到/app 文件夹中。而在容器终止之前,发送 HTTP 请求到 http://monitor.com:8080/waring,即向监控系统发送警告。
优雅的删除资源对象
当用户请求删除含有 pod 的资源对象时(如 RC、deployment 等),K8S 为了让应用程序优雅关闭(即让应用程序完成正在处理的请求后,再关闭软件),K8S 提供两种信息通知:
-
默认:K8S 通知 node 执行 docker stop 命令,docker 会先向容器中 PID 为 1 的进程发送系统信号 SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认超时时间(30s),会继续发送 SIGKILL 的系统信号强行 kill 掉进程。
-
使用 pod 生命周期(利用 PreStop 回调函数),它执行在发送终止信号之前。默认情况下,所有的删除操作的优雅退出时间都在 30 秒以内。kubectl delete 命令支持–grace-period=的选项,以运行用户来修改默认值。0 表示删除立即执行,并且立即从 API 中删除 pod。在节点上,被设置了立即结束的的 pod,仍然会给一个很短的优雅退出时间段,才会开始被强制杀死。如下:
spec: containers: - name: nginx-demo image: centos:nginx lifecycle: preStop: exec: command: - '/usr/local/nginx/bin/nginx' - '-s' - 'quit' ports: - containerPort: 80 name: http
livenessProbe和readinessProbe
livenessProbe:存活性探测
许多应用程序经过长时间运行,最终过渡到无法运行的状态,除了重启,无法恢复。通常情况下,K8S 会发现应用程序已经终止,然后重启应用程序 pod。有时应用程序可能因为某些原因(后端服务故障等)导致暂时无法对外提供服务,但应用软件没有终止,导致 K8S 无法隔离有故障的pod,调用者可能会访问到有故障的 pod,导致业务不稳定。K8S 提供 livenessProbe 来检测容器是否正常运行,并且对相应状况进行相应的补救措施。
readinessProbe:就绪性探测
在没有配置 readinessProbe 的资源对象中,pod 中的容器启动完成后,就认为 pod 中的应用程序可以对外提供服务,该 pod 就会加入相对应的 service,对外提供服务。但有时一些应用程序启动后,需要较长时间的加载才能对外服务,如果这时对外提供服务,执行结果必然无法达到预期效果,影响用户体验。比如使用 tomcat 的应用程序来说,并不是简单地说 tomcat 启动成功就可以对外提供服务的,还需要等待 spring 容器初始化,数据库连接上等等。
startupProbe:启动探测
探测容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功 Success。
可以自定义在 pod 启动时是否执行这些检测,如果不设置,则检测结果均默认为通过,如果设置,则顺序为 startupProbe>readinessProbe=livenessProbe。
目前 LivenessProbe 和 ReadinessProbe 两种探针都支持下面三种探测方法:
- ExecAction:在容器中执行指定的命令,如果执行成功,退出码为 0 则探测成功。
- TCPSocketAction:通过容器的 IP 地址和端口号执行 TCP 检 查,如果能够建立 TCP 连接,则表明容器健康。
- HTTPGetAction:通过容器的 IP 地址、端口号及路径调用 HTTP Get 方法,如果响应的状态码大于等于 200 且小于 400,则认为容器健康
探针探测结果有以下值:
- Success:表示通过检测。
- Failure:表示未通过检测
- Unknown:表示检测没有正常进行。
Pod 探针相关的属性:
探针(Probe)有许多可选字段,可以用来更加精确的控制 Liveness 和 Readiness 两种探针的行为
- initialDelaySeconds: Pod 启动后首次进行检查的等待时间,单位“秒”。
- periodSeconds: 检查的间隔时间,默认为 10s,单位“秒”
- timeoutSeconds: 探针执行检测请求后,等待响应的超时时间,默认为 1s,单位“秒”
- successThreshold:连续探测几次成功,才认为探测成功,默认为 1,在 Liveness 探针中必须为 1,最小值为 1。
- failureThreshold: 探测失败的重试次数,重试一定次数后将认为失败,在 readiness 探针中,Pod 会被标记为未就绪,默认为 3,最小值为 1
两种探针区别:
ReadinessProbe 和 livenessProbe 可以使用相同探测方式,只是对 Pod 的处置方式不同:
- readinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
- livenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施。
Pod 探针使用示例:
-
LivenessProbe 探针使用示例
-
通过 exec 方式做健康探测
liveness-exec.yaml
apiVersion: v1 kind: Pod metadata: name: liveness-exec labels: app: liveness spec: containers: - name: liveness image: busybox:1.28 args: - /bin/bash - -c - touch /tmp/healthy;sleep 30;rm -rf /tmp/healthy;sleep 3600 livenessProbe: initialDelaySeconds: 10 # 延迟监测的时间 periodSeconds: 5 # 监测的时间间隔 exec: command: - cat - /tmp/healthy容器启动设置执行的命令:
/bin/sh -c “touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600”
容器在初始化后,首先创建一个 /tmp/healthy 文件,然后执行睡眠命令,睡眠 30 秒,到时间后执行删除 /tmp/healthy 文件命令。而设置的存活探针检检测方式为执行 shell 命令,用cat 命令输出 healthy 文件的内容,如果能成功执行这条命令,存活探针就认为探测成功,否则探测失败。在前 30 秒内,由于文件存在,所以存活探针探测时执行 cat /tmp/healthy 命令成功执行。30 秒后 healthy 文件被删除,所以执行命令失败,Kubernetes 会根据 Pod 设置的重启策略来判断,是否重启 Pod。
[root@k8s01 pod]# kubectl apply -f liveness-exec.yaml pod/liveness-exec created [root@k8s01 pod]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 0 28s # 过一会,容器会进行重启 [root@k8s01 pod]# kubectl get pods NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 1 97s -
通过 HTTP 方式做健康探测
liveness-http.yaml
apiVersion: v1 kind: Pod metadata: name: liveness-http labels: test: liveness spec: containers: - name: liveness image: mydlqclub/springboot-helloworld:0.0.1 livenessProbe: initialDelaySeconds: 20 # 延迟加载时间 periodSeconds: 5 # 重试时间间隔 timeoutSeconds: 10 # 超时时间设置 httpGet: port: 8081 scheme: HTTP path: /actuator/health 上面 Pod 中启动的容器是一个 SpringBoot 应用,其中引用了 Actuator 组件,提供了/actuator/health 健康检查地址,存活探针可以使用 HTTPGet 方式向服务发起请求,请求 8081端口的 /actuator/health 路径来进行存活判断:
任何大于或等于 200 且小于 400 的代码表示探测成功。任何其他代码表示失败。
如果探测失败,则会杀死 Pod 进行重启操作
httpGet 探测方式有如下可选的控制字段:
- scheme: 用于连接 host 的协议,默认为 HTTP。
- host:要连接的主机名,默认为 Pod IP,可以在 http request head 中设置 host 头部。
- port:容器上要访问端口号或名称。
- path:http 服务器上的访问 URI。
- httpHeaders:自定义 HTTP 请求 headers,HTTP 允许重复 headers
-
通过 TCP 方式做健康探测
liveness-tcp.yaml
apiVersion: v1 kind: Pod metadata: name: liveness-tcp labels: test: liveness spec: containers: - name: liveness image: nginx:latest livenessProbe: initialDelaySeconds: 15 periodSeconds: 20 tcpSocket: port: 80 TCP 检查方式和 HTTP 检查方式非常相似,在容器启动 initialDelaySeconds 参数设定的时间后,kubelet 将发送第一个 livenessProbe 探针,尝试连接容器的 80 端口,如果连接失败则将杀死 Pod 重启容器。
-
-
ReadinessProbe 探针使用示例
Pod 的 ReadinessProbe 探针使用方式和 LivenessProbe 探针探测方法一样,也是支持三种,只是一个是用于探测应用的存活,一个是判断是否对外提供流量的条件。这里用一个 Springboot项目,设置 ReadinessProbe 探测 SpringBoot 项目的 8081 端口下的 /actuator/health 接口,如果探测成功则代表内部程序以及启动,就开放对外提供接口访问,否则内部应用没有成功启动,暂不对外提供访问,直到就绪探针探测成功。
readiness-http.yaml
apiVersion: v1 kind: Service metadata: name: springboot labels: app: springboot spec: type: NodePort ports: - port: 8080 name: server targetPort: 8080 nodePort: 31180 - port: 8081 name: management targetPort: 8081 nodePort: 31181 selector: app: springboot --- apiVersion: v1 kind: Pod metadata: name: springboot labels: app: springboot spec: containers: - name: springboot image: mydlqclub/springboot-helloworld:0.0.1 ports: - containerPort: 8080 name: server - containerPort: 8081 name: management readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: port: 8081 scheme: HTTP path: /actuator/health -
ReadinessProbe + LivenessProbe 配合使用示例
一般程序中需要设置两种探针结合使用,并且也要结合实际情况,来配置初始化检查时间和检测间隔,下面列一个简单的 SpringBoot 项目的 Deployment 例子
liveness-readiness.yaml
apiVersion: v1 kind: Service metadata: name: springboot labels: app: springboot spec: type: NodePort ports: - port: 8080 name: server targetPort: 8080 nodePort: 31180 - port: 8081 name: management targetPort: 8081 nodePort: 31181 selector: app: springboot --- apiVersion: apps/v1 kind: Deployment metadata: name: springboot labels: app: springboot spec: replicas: 1 selector: matchLabels: app: springboot template: metadata: name: springboot labels: app: springboot spec: containers: - name: readiness image: mydlqclub/springboot-helloworld:0.0.1 ports: - containerPort: 8080 name: server - containerPort: 8081 name: management readinessProbe: initialDelaySeconds: 20 periodSeconds: 5 timeoutSeconds: 10 httpGet: port: 8081 scheme: HTTP path: /actuator/health livenessProbe: initialDelaySeconds: 30 periodSeconds: 10 timeoutSeconds: 5 httpGet: port: 8081 scheme: HTTP path: /actuator/health
为什么要用 startupProbe?
在 k8s 中,通过控制器管理 pod,如果更新 pod 的时候,会创建新的 pod,删除老的 pod,但是如果新的 pod 创建了,pod 里的容器还没完成初始化,老的 pod 就被删除了,会导致访问 service 或者ingress 时候,访问到的 pod 是有问题的,所以 k8s 就加入了一些存活性探针:livenessProbe、就绪性探针 readinessProbe 以及这节课要介绍的启动探针 startupProbe。
startupProbe 是在 k8s v1.16 加入了 alpha 版,官方对其作用的解释是:
判断容器内的应用程序是否已启动。如果提供了启动探测,则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器将服从其重启策略。如果容器没有提供启动探测,则默认状态为成功。
注意:不要将 startupProbe 和 readinessProbe 混淆。
什么时候会用 startupProbe 呢?
正常情况下,我们会在 pod template 中配置 livenessProbe 来探测容器是否正常运行,如果异常则会触发
restartPolicy 重启容器(因为默认情况下 restartPolicy 设置的是 always)。
如下:
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 1
initialDelay:10
periodSeconds: 10
上面配置的意思是容器启动 10s 后每 10s 检查一次,允许失败的次数是 1 次。如果失败次数超过 1 则会触发 restartPolicy。
但是有时候会存在特殊情况,比如服务 A 启动时间很慢,需要 60s。这个时候如果还是用上面的探针就会进入死循环,因为上面的探针 10s 后就开始探测,这时候我们服务并没有起来,发现探测失败就会触发restartPolicy。这时候有的人可能会想到把 initialDelay 调成 60s 不就可以了?但是我们并不能保证这个服务每次起来都是 60s,假如新的版本起来要 70s,甚至更多的时间,我们就不好控制了。有的人可能还会想到把失败次数增加,比如下面配置:
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 5
initialDelay:10
periodSeconds: 10
这在启动的时候是可以解决我们目前的问题,但是如果这个服务挂了呢?如果 failureThreshold=1 则10s 后就会报警通知服务挂了,如果设置了 failureThreshold=5,那么就需要 5*10s=50s 的时间,在现在大家追求快速发现、快速定位、快速响应的时代是不被允许的。
在这时候我们把 startupProbe 和 livenessProbe 结合起来使用就可以很大程度上解决我们的问题。
如下:
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 1
initialDelay:10
periodSeconds: 10
startupProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 10
initialDelay:10
periodSeconds: 10
上面的配置是只有 startupProbe 探测成功后再交给 livenessProbe。我们 startupProbe 配置的是10*10s,也就是说只要应用在 100s 内启动都是 OK 的,而且应用挂掉了 10s 就会发现问题。
tainers:
- name: readiness
image: mydlqclub/springboot-helloworld:0.0.1
ports:
- containerPort: 8080
name: server
- containerPort: 8081
name: management
readinessProbe:
initialDelaySeconds: 20
periodSeconds: 5
timeoutSeconds: 10
httpGet:
port: 8081
scheme: HTTP
path: /actuator/health
livenessProbe:
initialDelaySeconds: 30
periodSeconds: 10
timeoutSeconds: 5
httpGet:
port: 8081
scheme: HTTP
path: /actuator/health
**为什么要用 startupProbe?**
在 k8s 中,通过控制器管理 pod,如果更新 pod 的时候,会创建新的 pod,删除老的 pod,但是如果新的 pod 创建了,pod 里的容器还没完成初始化,老的 pod 就被删除了,会导致访问 service 或者ingress 时候,访问到的 pod 是有问题的,所以 k8s 就加入了一些存活性探针:livenessProbe、就绪性探针 readinessProbe 以及这节课要介绍的启动探针 startupProbe。
startupProbe 是在 k8s v1.16 加入了 alpha 版,官方对其作用的解释是:
判断容器内的应用程序是否已启动。如果提供了启动探测,则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器将服从其重启策略。如果容器没有提供启动探测,则默认状态为成功。
**注意:不要将 startupProbe 和 readinessProbe 混淆。**
**什么时候会用 startupProbe 呢?**
正常情况下,我们会在 pod template 中配置 livenessProbe 来探测容器是否正常运行,如果异常则会触发
restartPolicy 重启容器(因为默认情况下 restartPolicy 设置的是 always)。
如下:
```yaml
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 1
initialDelay:10
periodSeconds: 10
上面配置的意思是容器启动 10s 后每 10s 检查一次,允许失败的次数是 1 次。如果失败次数超过 1 则会触发 restartPolicy。
但是有时候会存在特殊情况,比如服务 A 启动时间很慢,需要 60s。这个时候如果还是用上面的探针就会进入死循环,因为上面的探针 10s 后就开始探测,这时候我们服务并没有起来,发现探测失败就会触发restartPolicy。这时候有的人可能会想到把 initialDelay 调成 60s 不就可以了?但是我们并不能保证这个服务每次起来都是 60s,假如新的版本起来要 70s,甚至更多的时间,我们就不好控制了。有的人可能还会想到把失败次数增加,比如下面配置:
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 5
initialDelay:10
periodSeconds: 10
这在启动的时候是可以解决我们目前的问题,但是如果这个服务挂了呢?如果 failureThreshold=1 则10s 后就会报警通知服务挂了,如果设置了 failureThreshold=5,那么就需要 5*10s=50s 的时间,在现在大家追求快速发现、快速定位、快速响应的时代是不被允许的。
在这时候我们把 startupProbe 和 livenessProbe 结合起来使用就可以很大程度上解决我们的问题。
如下:
livenessProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 1
initialDelay:10
periodSeconds: 10
startupProbe:
httpGet:
path: /test
prot: 80
failureThreshold: 10
initialDelay:10
periodSeconds: 10
上面的配置是只有 startupProbe 探测成功后再交给 livenessProbe。我们 startupProbe 配置的是10*10s,也就是说只要应用在 100s 内启动都是 OK 的,而且应用挂掉了 10s 就会发现问题。















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









