







 本文详细介绍了链接在软件开发中的作用,包括链接器在编译、链接任务、目标文件的不同形式、符号解析、重定位以及可执行目标文件的结构。着重讲解了编译器驱动程序的工作流程和链接器如何处理符号和重定位以生成可执行文件。
本文详细介绍了链接在软件开发中的作用,包括链接器在编译、链接任务、目标文件的不同形式、符号解析、重定位以及可执行目标文件的结构。着重讲解了编译器驱动程序的工作流程和链接器如何处理符号和重定位以生成可执行文件。
目录
一、链接
链接是将各种内存代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。链接可以执行于
(1)编译时,源代码被翻译成机器代码时
(2)加载时,程序被加载器加载到内存并执行时
(3)运行时,应用程序来执行。
在早期的计算机系统中,链接是手动执行的,在现代系统中,链接是由链接器自动执行的。
链接器在软件开发总扮演一个关键的角色,使分离编译成为可能。大型的应用程序不用被组织为一个巨大的源文件,而是可以被分解为更小的、更好管理的模块,从而可以分模块地被修改和编译。当改变其中的一个或多个模块时,只需要简单地重新编译并链接改变地模块,而不用重新编译其它文件。
理解链接器的作用:
- 帮助构造大型程序:理解、解决构造大型程序时遇到的缺少模块、缺少库或者不兼容的库版本引起的链接器错误。
- 帮助避免一些危险的编程错误:Linux链接器解析符号引用时做的决定可以影响程序的正确性。
- 帮助理解语言的作用域规则的实现:更好地理解全局变量、局部变量和静态变量与静态函数。
- 帮助理解重要的系统概念:链接器产生的可执行目标文件在系统功能中扮演着关键角色,比如加载和运行程序、虚拟内存、分页和内存映射。
- 帮助利用共享库:掌握共享库和动态链接。
1.1 编译器驱动程序
大多数编译系统提供编译器驱动程序,代表用户在需要时调用语言预处理器、编译器、汇编器和链接器。例如,要用GNU编译系统构造示例程序,就要通过在shell中输入下列命令来调用GCC驱动程序。
linux> gcc -Og -o prog main.c sum.c
(1)预处理器(cpp)将ASCII码的源程序文件(.c)翻译成一个ASCII码的中间文件(.i);
(2)编译器(ccl)将中间文件(.i)翻译成一个ASCII码的汇编文件(.s);
(3)汇编器(as)将源程序(.s)翻译成一个可重定位目标文件(.o);
(4)链接器(ld)将目标文件main.o和sum.o以及一些必要的系统目标文件组合起来,创建一个可执行目标文件prog。
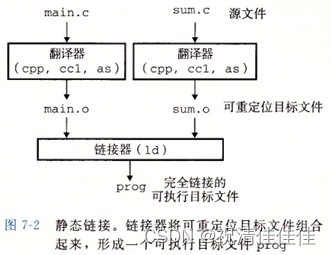
shell调用操作系统中一个叫做加载器的函数,加载器将可执行文件prog中的代码和数据复制到内存,然后将控制转移到这个程序的开始位置。
linux> ./prog
1.2 链接任务
LD作为静态链接器,以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的、可以加载和运行的可执行目标文件作为输出。输入的可重定位目标文件由各种不同的代码和数据节组成,每一节都是一个连续的字节序列。指令、初始化全局变量、未初始化变量在不同的数据节中。
为了构造可执行文件,链接器必须完成两个主要任务:
(1)符号解析。目标文件定义和引用符号,每个符号对应于一个函数、一个全局变量或一个静态变量。符号解析的目的是将每个符号引用正好和一个符号定义关联起来。
(2)重定位。编译器和汇编器生成从地址0开始的代码和数据节,链接器通过把每个符号定义与一个内存位置关联起来,从而重定位这些节,然后修改所有对这些符号的引用,使其指向这个内存位置。
二、目标文件
2.1 目标文件三种形式
目标文件有三种形式,编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。一个目标模块就是一个字节序列,而一个目标文件就是一个以文件形式存放在磁盘中的目标模块。
- 可重定位目标文件(.o)。在编译过程中与其他可重定位目标文件合并起来,创建一个可执行目标文件。
- 共享目标文件(.dll/.so)。特殊的可重定位目标文件,可以在加载或者运行时被动态地加载进内存并链接。
- 可执行目标文件(.exe/.out)。可以被直接复制到内存并执行。
2.2 可重定位目标文件
ELF头以一个16字节的序列开始,该序列描述了生成文件的系统的字大小和字节顺序。ELF头剩下的部分包含帮助链接器语法分析和解释目标文件的信息。其中包含ELF头的大小、目标文件的类型(可重定位、共享的、可执行的)、机器类型(如x86-64)、节头部表的文件偏移,以及头部表中条目的大小和数量。不同节的位置和大小是由节头部表描述的,目标文件中每个节都有一个固定大小的条目。
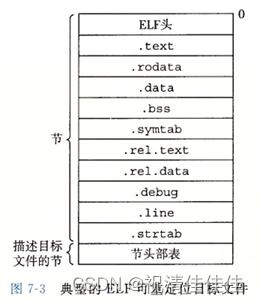
ELF头和节头部表之间的都是节,一个典型的ELF可重定位目标文件包含下面几个节:
- .text,已编译程序的机器代码。
- .rodata,只读数据,比如switch语句的跳转表。
- .data,已初始化的全局和静态C变量,局部C变量在运行时被保存在栈中,不出现在节中。
- .bss,未初始化的全局和静态C变量,以及所有被初始化为0的全局或静态变量。在目标文件中这个节不占据实际的空间,仅仅是一个占位符。在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。运行时,在内存中分配这些变量,初始值为0。目标文件格式区分已初始化和未初始化的变量是为了空间效率。
- .symtab,一个符号表,存放在程序中定义和引用的函数和全局变量的信息。和编译器中的符号表不同,.symtab符号表不包含局部变量的条目。
- .rel.text,一个.text节中位置的列表,当链接器把这个目标文件和其它文件组合时,需要修改这些位置。一般而言,任何调用外部函数或引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。可执行目标文件中不需要重定位信息,因此通常省略。
- .rel.data,被模块引用或定义的所有全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果初始值是一个全局变量地址,或者外部定义函数的地址,都需要修改。
- .debug,一个调试符号表,条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的C源文件。
- .line,原始C源程序中的行号和.text节中机器指令之间的映射。
- .strtab,一个字符串表,内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。
三、符号
3.1 符号表
每个可重定位目标模块m都有一个符号表,包含m定义和引用的符号信息,在链接器的上下文中,有三种不同的符号。
- 由模块m定义的、并能被其它模块引用的全局符号。全局链接器符号对应于非静态的C函数和全局变量。
- 由其它模块定义的、并被模块m引用的全局符号,这些符号称为外部符号,对应于在其它模块中定义的非静态C函数和全局变量。
- 只被模块m定义和引用的局部符号,对应于静态函数和静态全局变量,这些符号通过static属性被隐藏,不能被其它文件使用。
.symtab中的符号表不包含对应于本地非静态程序变量的任何符号,这些符号在运行时在栈中被管理,链接器对此类符号不感兴趣。
符号表是由汇编器构造的,使用编译器输出到汇编语言.s文件中的符号。.symtab节中包含ELF符号表,这张符号表包含一个条目的数组,条目是一个结构体。
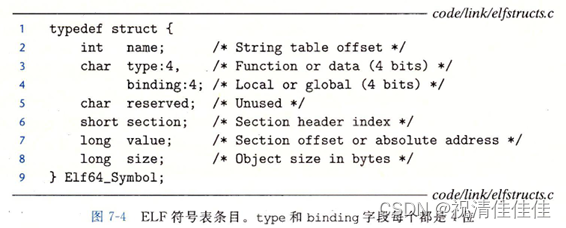
name是字符串表中的字节偏移,指向符号的以null结尾的字符串名字;value是符号的地址,对于可重定位的模块来说,value是距定义目标的节的起始位置的偏移,对于可执行目标文件来说,该值是一个绝对运行时地址;size是目标的大小;type是类型,数据或函数;bounding字段表示符号是本地的还是全局的;section表示符号被分配到的节。
3.2 符号解析
链接器解析符号引用的方法是将每个引用与输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。
(1)对于定义在相同模块中的局部符号的引用,编译器只允许每个模块中每个局部符号有一个定义,静态局部变量也会有本地链接器符号,编译器还要确保其拥有唯一的名字。
(2)对于全局符号的引用解析,当编译器遇到一个不是在当前模块中定义的符号(函数或函数名)时,会假设该符号是在其它某个模块中定义的,生成一个链接器符号表条目,并把它交给链接器处理。如果链接器在任何输入模块中都找不到这个被引用符号的定义,就输出一条错误信息并终止。
C++中的链接器符号的重整:对于重载函数,编译器将每个唯一的方法和参数列表组合编码成一个对链接器来说唯一的名字,这种编码过程为重整,相反的过程为恢复。一个被重整的类名字是由名字中字符的整数数量,后面跟原始名字组成的。比如,类Foo被编码成3Foo,方法被编码为原始方法名,后面加上__,加上被重整的类名,再加上每个参数的单字母编码。比如,Foo::bar(int, long)被编码为bar__3Fooil。重整全局变量和模板名字的策略是类似的。
3.3 链接器解析多重定义的全局符号
在编译时,编译器向汇编器输出每个全局符号,分类为强符号和弱符号,汇编器将该信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量是强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Linux链接器使用下面的规则来处理多重定义的符号名:
- 不允许有多个同名的强符号。如果有,链接器会生成一条错误信息。
- 如果有一个强符号和多个弱符号同名,那么选择强符号。
- 如果有多个弱符号同名,从这些弱符号中任意选择一个。

在运行时,函数f将x的值由15213改为15212,bar3.c中的f函数改变的是foo3.c中定义并初始化为15213的x,而不是bar3.c中的未初始化的x。也就是说,链接器在强符号和弱符号中选择了强符号(即使两个同名的符号类型不同也遵循该规则)。
四、重定位
链接器通过符号解析将代码中的每个符号引用和符号定义关联起来,此时,链接器知道输入目标模块中的代码节和数据节的确切大小。在符号解析之后开始重定位:合并输入模块,并为每个符号分配运行时地址。重定位由两步组成。
(1)重定位节和符号定义:链接器将所有相同类型的节全部合并为同一类型的新的聚合节。例如,将所有输入模块的.data节全部合并为一个节,即输出的可执行目标文件的.data节。然后,链接器将运行时内存地址赋给新的聚合节,同时赋给输入模块定义的每个节和定义的每个符号。此时,程序中的每条指令和全局变量都有唯一的运行时内存地址。
(2)重定位节中的符号引用:链接器根据可重定位条目修改代码节和数据节中对每个符号的引用,使其指向正确的运行时地址。
4.1 重定位条目
当汇编器生成一个目标模块时,数据和代码最终存放在内存中的位置是未知的,引用的任何外部定义的函数或者全局变量的位置也是未知的。所以,汇编器会对最终位置未知的目标引用生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码的重定位条目放在.rel.text中,已初始化数据的重定位条目放在.rel.data中。
ELF重定位条目中,offset是需要被修改的引用的节偏移,symbol表示被修改引用应该指向的符号,type告知链接器如何修改新的引用,addend是一个有符号常数,一些类型的重定位要使用addend对修改引用的值做偏移调整。

ELF定义了32种不同的重定位类型,最基本的两种重定位类型是R_X86_64_PC32和R_X86_64_32。
- R_X86_64_PC32:重定位一个使用32位PC相对地址的引用。即距程序计数器(PC)的当前运行时值的偏移量。当CPU执行一条使用PC相对地址的指令时,就将在指令中编码的32位值加上PC的当前运行时值,得到有效地址。
- R_X86_64_32:重定位一个使用32位绝对地址的引用。通过绝对寻址,CPU直接使用在指令中编码的32位值作为有效地址,不需要进行进一步修改。
4.2 重定位符号引用
链接器在重定位过程中,在每个节s以及与每个节相关联的重定位条目r上迭代执行。ADDR表示节s和符号(r.symbol)的地址。
(1)重定位PC相对引用
ADDR(r.symbol) + r.addend - ( ADDR(s) + r.offset)
假设r.symbol为一个函数,地址为0x4004e8,计算结果为0x5,.o文件中的call 13<main+0x13>,callq指令调用函数。在可执行目标文件内的已重定位的.text节中该指令为callq 4004e8<sum>。callq指令的目标等于PC的当前运行时值和0x5的和。
(2)重定位绝对引用
ADDR(r.symbol) + r.addend
假设r.symbol为一个全局数组,计算结果为0x601018,.o文件中的mov $0x0,%edi,mov指令将全局数组的地址复制到寄存器中。在可执行目标文件内的已重定位的.text节中该指令为mov $0x601018,%edi。
五、可执行目标文件
5.1 可执行文件结构
链接器将多个目标文件合并成一个可执行目标文件。示例C程序开始是一组ASCII文本文件,被转化为一个二进制文件,且这个二进制文件包含加载程序到内存并运行所需的所有信息。
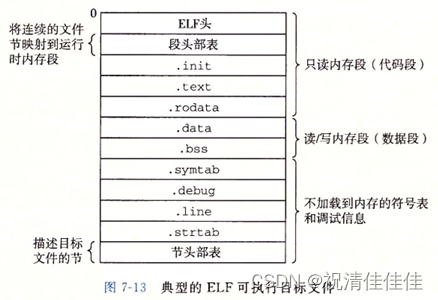
可执行目标文件的格式类似于可重定位目标文件的格式。
- ELF头描述文件的总体格式,还包括程序的入口点,也就是当程序运行时要执行的第一条指令的地址。
- .text、.rodata和.data节与可重定位目标文件中的节是相似的。
- .init节定义了一个小函数,叫做_init,程序的初始化代码会调用_init。
- 可执行文件中没有rel节,因为可执行文件是完全链接的,即已被重定位。
- ELF可执行文件被设计得很容易加载到内存,可执行文件的连续的片被映射到连续的内存段。程序头部表描述了这种映射关系。

程序头部表根据可执行目标文件的内容初始化两个内存段,第一行、第二行表示代码段有读/执行访问权限,开始于内存地址0x400000处,总共的内存大小是0x69c字节,并且被初始化为可执行目标文件的头0x69c个字节,其中包括ELF头、程序头部表以及.init、.text和.rodata节。
第三行、第四行表示数据段有读/写访问权限,开始于内存地址0x600df8处,总共的内存大小是0x230字节,并且从目标文件中偏移0xdf8处开始的.data节中的Ox228个字节初始化,该段中剩下的8个字节对应于运行时将被初始化为0的.bss数据。
5.2 加载可执行目标文件
可执行目标文件通过调用某个驻留在存储器中称为加载器的操作系统代码来运行,任何Linux程序都可以通过execve函数来调用加载器。加载器将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序,这个将程序复制到内存并运行的过程叫做加载。
当加载器运行时,创建内存映像。在程序头部表的引导下,加载器将可执行文件的片复制到代码段和数据段。然后,加载器跳转到程序的入口点,也就是_start函数的地址。这个函数是在系统目标文件ctrl.o中定义的,对所有的C语言都是一样的,_start函数调用系统启动函数__libc_start_main,该函数定义在libc.so中。该函数初始化执行环境,调用用户层的main函数,处理main函数的返回值,并且在需要的时候把控制返回给内核。
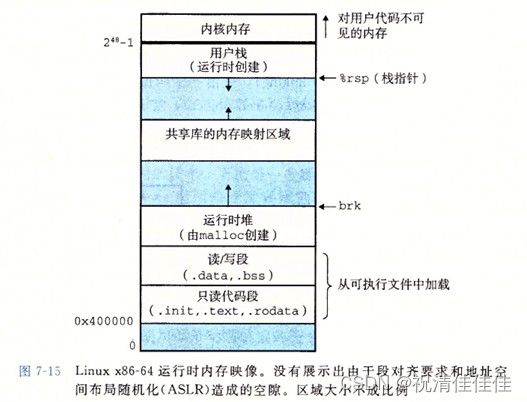
在Linux x86-64系统中,代码段总是从地址0x400000处开始,后面是数据段。运行时堆在数据段之后,通过调用malloc库往上增长。堆后面的区域是为共享模块保留的。用户栈总是从最大的合法地址(248-1)开始,向较小内存地址增长。栈的上方的区域,从地址248开始,是为内核中的代码和数据保留的,所谓内核就是操作系统驻留在内存的部分。
在加载过程中没有任何从磁盘到内存的数据复制,只是通过将虚拟地址空间的页映射到可执行文件的页大小的片,虚拟地址中的栈和堆段被初始化为可执行文件的内容。直到CPU引用一个被映射的虚拟页时才进行复制,此时操作系统利用页面调度机制自动将页面从磁盘传送到内存。















 4404
4404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









