







 文章讨论了多种机器学习模型的可解释性技术,包括树类模型自带的importance属性,SHAP的全局和局部解释性,LIME的模型无关局部解释性,以及排列重要性。这些方法可用于理解和解析模型预测背后的逻辑。
文章讨论了多种机器学习模型的可解释性技术,包括树类模型自带的importance属性,SHAP的全局和局部解释性,LIME的模型无关局部解释性,以及排列重要性。这些方法可用于理解和解析模型预测背后的逻辑。
对于可解释性,应该不会陌生,但是,要往深入的说,这里头名堂可不少。下面,就一起结合这篇文献中的几张图,谈谈各种可解释性。
图1:自带可解释性方法
这种可解释性最常见,也是最好用的,即在python或R语言中,模型都有自带的importance属性,尤其是"树类模型"。例如下图,作者给出了随机森林的importance排序结果。

图2:SHAP可解释性
这种技术也不会陌生了,近些年是主流,应用得很多,并且可视化效果很好。如下图,作者给出了全局可解释性和某个变量的可解释性。当然,SHAP还有更全面的技能,那就是局部可解释性和交互作用分析。
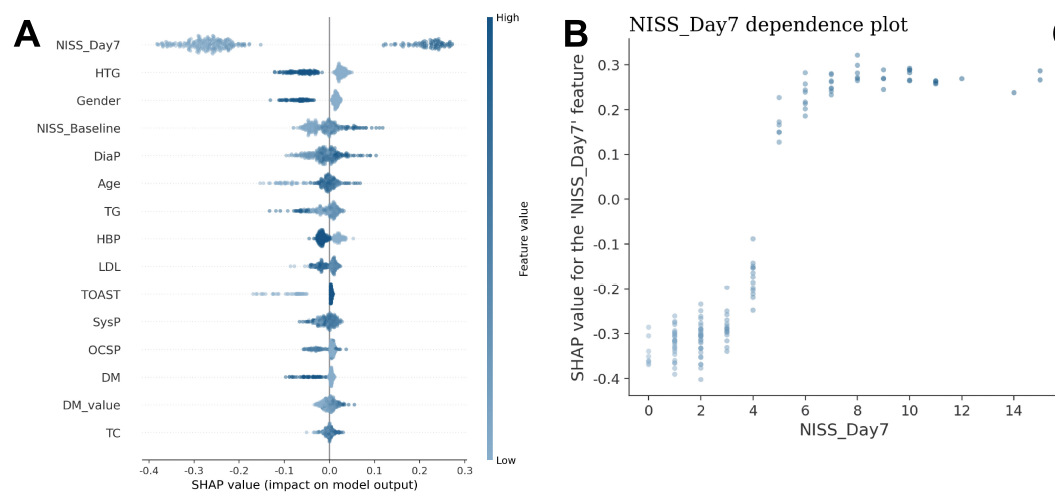
图3:局部可解释性LIME
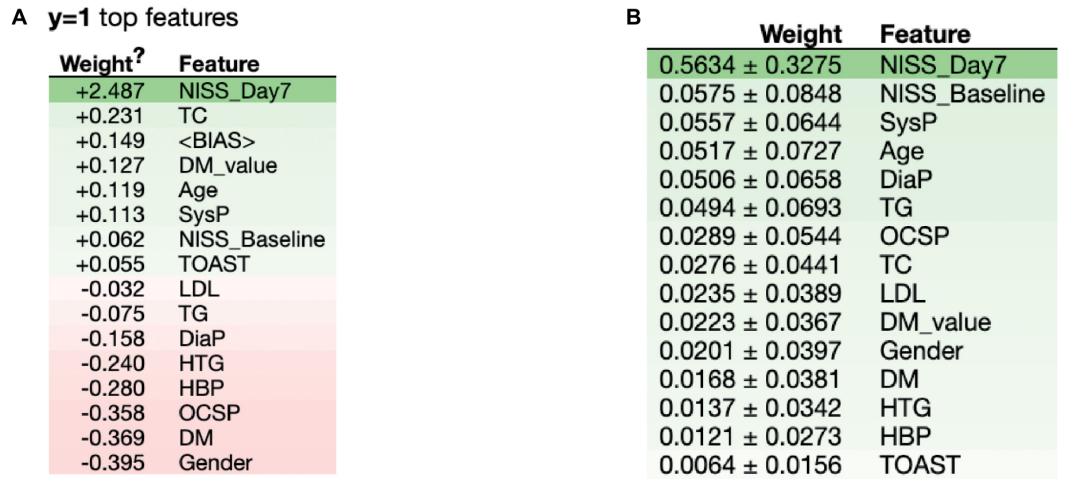
除了SHAP中带有局部可解释性外,还有一种相对常用的局部可解释性方法是LIME。但LIME有个优势,在于其对模型没有限制,无论是简单或复杂模型,其都能开展局部可解释性,应用很广。如下图,展示了每个类别的预测概率,各个变量的具体数值以及其对最终预测的贡献大小。

图4:排列重要性
全局可解释性除了常用的importance和SHAP技术外,还有这种排列重要性(permutation importance),这种技术的好处与上面一样,即不认模型,无论是简单或复杂模型,都能给出重要性。一般而言,将排列重要性中权重>0的视为重要预测变量。而权重为0或<0的变量对预测贡献很小。
可解释性技术这么多,选择不同方法结果也往往不多,因此,可以都试试,或许能发现一些意想不到的结果。方法给大家点出来了,实现方式网上都有现成代码,可做针对性学习~



















 2548
2548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











