







目录
机器学习中使用np.loadtxt()可以高效的导入数据,np.loadtxt()适合.txt文件和.csv文件。但是它默认读取float类型的值。
1、基础参数
numpy.loadtxt(
fname, dtype=, comments='#',
delimiter=None, converters=None,
skiprows=0, usecols=None,
unpack=False, ndmin=0)2、参数详解
- fname要读取的文件、文件名、或生成器。
- dtype数据类型,默认float。
- comments注释。
- delimiter分隔符,默认是空格。
- skiprows跳过前几行读取,默认是0,必须是int整型。
- usecols要读取哪些列,0是第一列。例如,usecols = (1,4,5)将提取第2,第5和第6列。默认读取所有列。
- unpack如果为True,将分列读取。
3、应用参数示例
文件的存储路径为:'./data.txt', 文件内容如下:
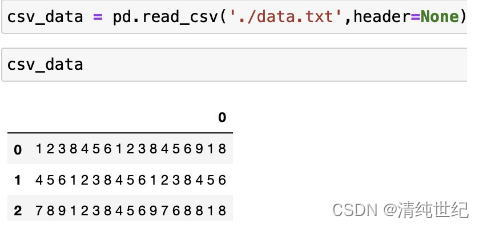
- dtype
#设置dtype
data = np.loadtxt('./data/data.csv',dtype=np.float32)
#设置dtype
data = np.loadtxt('./data/data.csv',dtype=int)
- comments
comment的是指, 如果行的开头为comment的值,那在读取时就会跳过该行。示例代码中comment = '1',则在读取数据时,会跳过开头为1的行。
data = np.loadtxt('./data.txt',dtype = int,comments='1')
- skiprows
skiprows跳过前几行读取,默认是0,必须是int整型。skiprows = 2则表示跳过前两行读取数据。
data = np.loadtxt('./data.txt',dtype = int,delimiter=',',skiprows=2)读取数据时,设定 skiprows = 2,则将前两行跳过,从第三行开始读取。

- usecols
usecols要读取哪些列,0是第一列。例如,usecols = (1,4,5)将提取第2,第5和第6列。默认读取所有列。
读取第2列数据。
data = np.loadtxt('./data.txt',dtype = int,delimiter=',',usecols = 1)
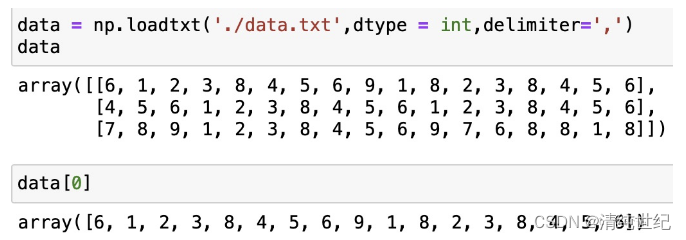
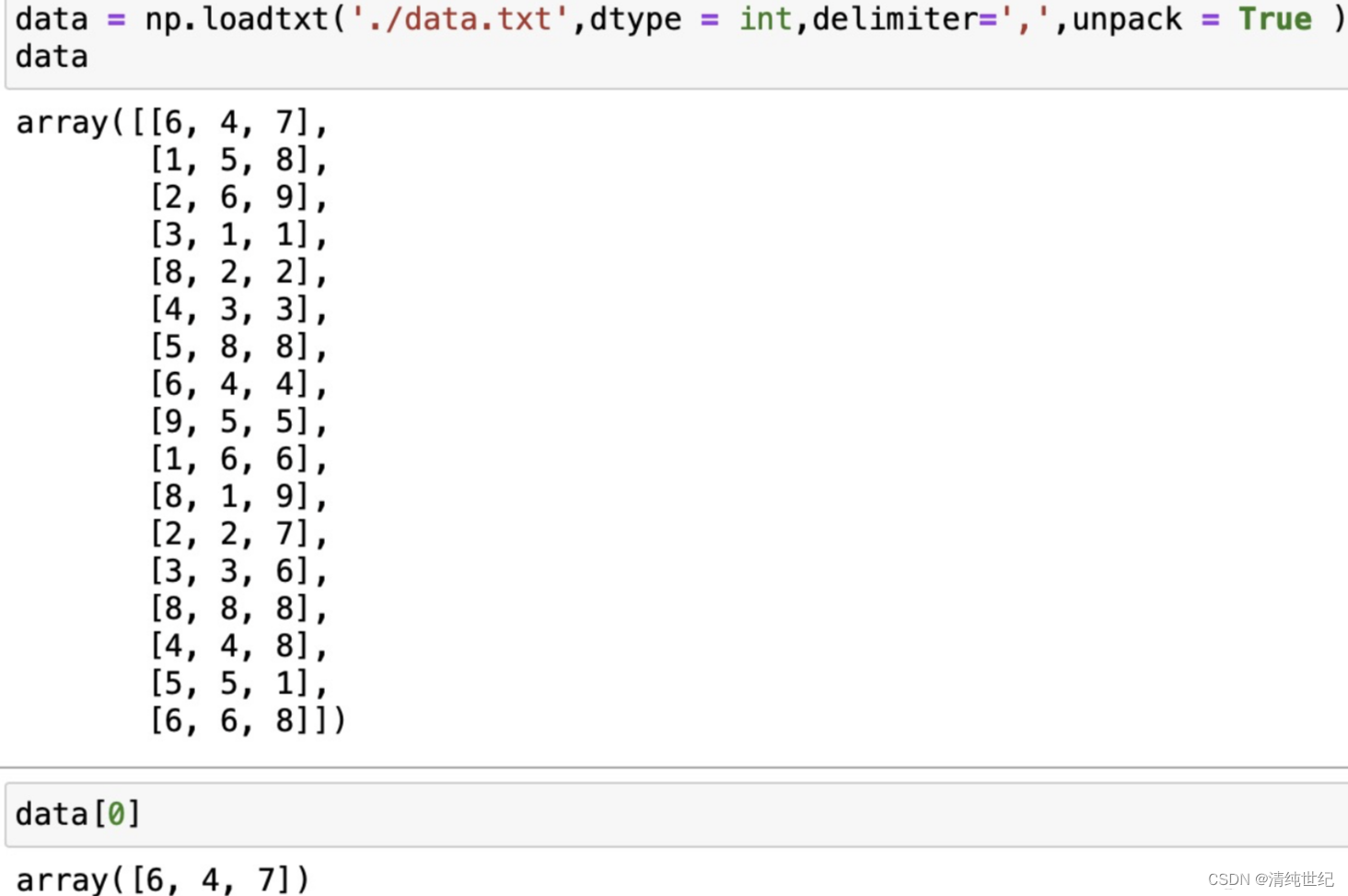
- unpack
unpack如果设置为Ture,将分列读取,类似于矩阵的转置。
未设置之前,数据读取时是以行为单位进行读取。
设置unpack=Ture之后再次读取,矩阵的列变为了行。
- np.loadtxt()读取csv文件
读取csv文件与读取txt文件的参数一致,需要注意的是csv文件的分隔符一般是“,”并且含有表头,所以需要使用delimiter=','作为分隔符,以及使用skiprows=1跳过表头。
#根据data_path读取文件内容
train_XY = np.loadtxt(data_path, delimiter=',', skiprows = 1,dtype=np.float32)
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











