







Java小白开始每日刷题,并记录刷题遇到的一些知识点,大佬们多多包涵,内容可能会比较杂乱,如果不太详细尽情谅解!!!希望对一些人有所帮助!!!
本次更新了与多态、Collection集合、数据结构相关的知识点
上期链接牛客Java专项练习笔记(6)
本次更新内容
24. 多态相关
24.1 多态的形式
多态是继封装、继承之后,面向对象的第三大特征。
多态是出现在继承或者实现关系中的
多态体现的格式:
父类类型 变量名 = new 子类/实现类构造器;
变量名.方法名();多态的前提:
有继承关系,子类对象是可以赋值给父类类型的变量。例如Animal是一个动物类型,而Cat是一个猫类型。Cat继承了Animal,Cat对象也是Animal类型,自然可以赋值给父类类型的变量。
有父类引用指向子类对象
有方法重写
24.2 多态调用成员的特点
变量调用:编译看左边,运行也看左边
方法调用:编译看左边,运行看右边
/**
*理解:
*Animal a = new Dog();
*现在是a去调用变量和方法,a是Animal类型的,所以默认都会去Animal这个类中去找
*
*变量:在子类的对象中,会把父类的成员变量也继承下来。父:name,子:name
*方法:如果子类对方法进行了重写,那么在虚方法表中是会把父类的方法进行覆盖的
*/
class Test{
public static void main(String[] args){
//创建对象
//Fu f = new Zi();
Animal a = new Dog();
/**
*成员变量调用:编译看左边,运行也看左边
*编译看左边:javac编译代码的时候,会看左边父类中有没有这个变量,如果有,编译成功;如果没有,编译失败
*运行看左边:java运行代码的时候,实际获取的就是左边父类中的成员变量的值
*/
System.out.println("a.name") //输出:动物
/**
*方法调用:编译看左边,运行看右边
*编译看左边:javac编译代码的时候,会看左边父类中有没有这个方法,如果有,编译成功;如果没有,编译失败
*运行看右边:java运行代码的时候,实际获取的就是右边子类中的方法
*/
a.eat(); //输出:狗吃骨头
}
}
class Animal{
String name = "动物";
public void eat(){
System.out.println("动物吃东西!")
}
}
class Cat extends Animal {
String name = "狗";
public void eat() {
System.out.println("狗吃骨头");
}
}
class Dog extends Animal {
String name = "猫";
public void eat() {
System.out.println("猫吃鱼");
}
}动画演示:

24.3 引用类型转换
多态的弊端:多态的写法无法访问子类的独有功能
当使用多态方式调用方法时,首先检查父类中是否有该方法,如果没有,则编译错误。也就是说,不能调用子类拥有,而父类没有的方法。编译都错误,更别说运行了。所以,想要调用子类特有的方法,必须做向下转型。
回顾基本数据类型转换
自动转换: 范围小的赋值给范围大的.自动完成:double d = 5;
强制转换: 范围大的赋值给范围小的,强制转换:int i = (int)3.14
多态的转型分为向上转型(自动转换)与向下转型(强制转换)两种。
24.3.1 向上转型(自动转换)
向上转型:多态本身是子类类型向父类类型向上转换(自动转换)的过程,这个过程是默认的
当父类引用指向一个子类对象时,便是向上转型
格式:
父类类型 变量名 = new 子类类型();
如:Animal a = new Cat();24.3.2 向下转型(强制转换)
向下转型:父类类型向子类类型向下转换的过程,这个过程是强制的
一个已经向上转型的子类对象,将父类引用转为子类引用,可以使用强制类型转换的格式,便是向下转型
格式:
子类类型 变量名 = (子类类型) 父类变量名;
如:Aniaml a = new Cat();
Cat c =(Cat) a; 案例:
abstract class Animal {
abstract void eat();
}
class Cat extends Animal {
public void eat() {
System.out.println("吃鱼");
}
public void catchMouse() {
System.out.println("抓老鼠");
}
}
class Dog extends Animal {
public void eat() {
System.out.println("吃骨头");
}
public void watchHouse() {
System.out.println("看家");
}
}
public class Test {
public static void main(String[] args) {
// 向上转型
Animal a = new Cat();
a.eat(); // 调用的是 Cat 的 eat
// 向下转型
Cat c = (Cat)a;
c.catchMouse(); // 调用的是 Cat 的 catchMouse
}
}24.3.3 转型的异常
public class Test {
public static void main(String[] args) {
// 向上转型
Animal a = new Cat();
a.eat(); // 调用的是 Cat 的 eat
// 向下转型
Dog d = (Dog)a;
d.watchHouse(); // 调用的是 Dog 的 watchHouse 【运行报错】
}
}这段代码可以通过编译,但是运行时,却报出了 ClassCastException ,类型转换异常!这是因为,明明创建了Cat类型对象,运行时,当然不能转换成Dog对象的。
24.3.4 instanceof关键字
为了避免ClassCastException的发生,Java提供了instanceof关键字,给引用变量做类型的校验
格式:
变量名 instanceof 数据类型
如果变量属于该数据类型或者其子类类型,返回true。
如果变量不属于该数据类型或者其子类类型,返回false。案例:转型前,最好做一个判断
public class Test {
public static void main(String[] args) {
// 向上转型
Animal a = new Cat();
a.eat(); // 调用的是 Cat 的 eat
// 向下转型
if (a instanceof Cat){
Cat c = (Cat)a;
c.catchMouse(); // 调用的是 Cat 的 catchMouse
} else if (a instanceof Dog){
Dog d = (Dog)a;
d.watchHouse(); // 调用的是 Dog 的 watchHouse
}
}
}instanceof新特性:把判断和强转合并成了一行
//新特性
//先判断a是否为Dog类型,如果是,则强转成Dog类型,转换之后变量名为d
//如果不是,则不强转,结果直接是false
if(a instanceof Dog d){
d.lookHome();
}else if(a instanceof Cat c){
c.catchMouse();
}else{
System.out.println("没有这个类型,无法转换");
}24.4 多态案例
try...catch...finally...体系中,再return之前始终会执行finally里面的代码,如果fianlly里面右return,则数据跟着finally改变;如果没有return,则原始数据不跟随finally里改变的数据改变
class Test {
public static void main(String[] args) {
System.out.println(new B().getValue());
}
static class A {
protected int value;
public A (int v) {
setValue(v);
}
public void setValue(int value) {
this.value= value;
}
public int getValue() {
try {
value ++;
return value;
} finally {
this.setValue(value);
System.out.println(value);
}
}
}
static class B extends A {
public B () {
super(5);
setValue(getValue()- 3);
}
public void setValue(int value) {
super.setValue(2 * value);
}
}
}运行过程:
new B() 构造一个B类的实例
此时super(5)语句,显示调用父类A的带参构造函数,该构造函数调用setValue(v),注意:1. 虽然构造函数是A类的,但此刻正在初始化的对象是B的一个实例,因此实际调用的是B类的setValue()方法,,而B类的setValue()方法,显示调用父类的setValue()方法,将B实例的value设置为:2 * 5 = 10。
接着,B类的构造函数还没有执行完,继续执行setValue(getValue() - 3) //①
先执行getValue()方法,B类中没有重写getVale()方法,因此**调用父类A的getVale()**方法。
调用getVale()方法之前,B的成员变量value值为10,value++执行后,value = 11,由于getValue()语句被try...finally...块包围,因此finally中的语句无论如何都将被执行,所以value = 11将会暂存起来,到finally语句块执行完毕后再真正的返回出去。
注意:finally语句块中this.setValue(value)方法调用的是B类的setValue方法。因为此刻正在初始化的是B类的一个对象(运行时多态),而且此刻使用了this关键字显示的指明了调用当前对象的方法。因此。此处会再次调用B类的setValue()方法,同上,super关键字显式调用A类的setValue()方法,将value的值设为了2 * 11 = 22,因此第一个打印项为22
finally语句执行完毕,会把刚刚暂存的11返回出去,最终getValue()方法的返回值是11,所以①处的语句结果为setValue(11 - 3) ---> setValue(8),而这里执行的setValue()f=方法将会是B类的,之后value的值变成了2 * 8 = 16;
new B().getValue()
B类中没有getValue()方法,所以此处调用的是A的getValue(),此时value = 16,value++执行后value = 17,类似步骤一中的finally语句块,value = 17会先被暂存, 然后此处会再次调用B类的setValue()方法,同上,super关键字显式调用A类的setValue()方法,将value的值设为了2 * 17 = 34,因此第二个打印项为34。执行结束后将暂存的value = 17返回出去。
main函数将value = 17输出出去,第三项为17
26. Collection集合相关
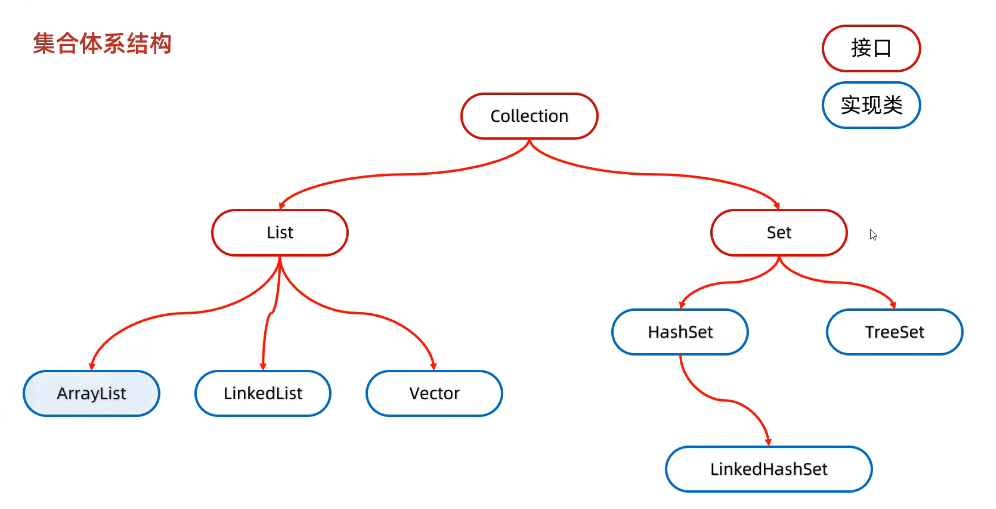
26.1 集合体系结构
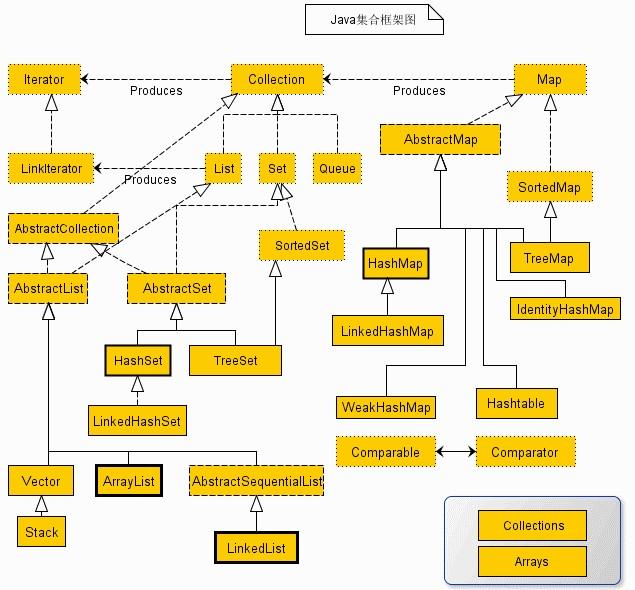
26.2 Collection
List系列集合:添加的元素是有序(存和取的顺序)、可重复、有索引
Set系列集合:添加的元素是无序、不重复、无索引
Collection:Collection是单列集合的祖宗接口,它的功能是全部单列集合都可以继承使用的
Collection集合常用方法:
方法名 | 说明 |
boolean add(E e) | 添加元素 |
boolean remove(Object o) | 从集合中移除指定元素 |
boolean removeIf(Object o) | 根据条件进行移除 |
void clear() | 清空集合中的元素 |
boolean contains(Object o) | 判断集合中是否存在指定元素 |
boolean isEmpty() | 判断集合是否为空 |
int size() | 集合的长度,也就是集合中元素的个数 |
细节:
contains方法底层依赖equals方法进行判断是否存在的,所以如果集合中存的是自定义对象,也想通过contains方法来判断是否包含,那么在JavaBean类中,一定要重写equals方法
26.3 迭代器
迭代器:再Java中的类是Iterator,是集合的专用遍历方式
Iterator<E> iterator() //返回此集合中元素的迭代器,默认指向当前集合的0索引Iterator中的常用方法
boolean hasNext() //判断当前位置是否有元素,有元素返回true,没有元素返回false
E next() //获取当前位置的元素,并将迭代器对象移向下一个位置
void remove() //删除迭代器对象当前指向的元素Collection集合的遍历
public class IteratorDemo1 {
public static void main(String[] args) {
//创建集合对象
Collection<String> c = new ArrayList<>();
//添加元素
c.add("hello");
c.add("world");
//Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到
Iterator<String> it = c.iterator();
//用while循环改进元素的判断和获取
while (it.hasNext()) { //创建指针
String s = it.next(); //判断是否有元素
System.out.println(s); //获取元素,移动指针
}
}
}细节点:
如果当前指针指向最后没有元素的位置,如果再次强行调用,则会报错NoSuchElementException
迭代器遍历完毕,指针不会复位(重新获取一个迭代器对象)
循环中只能用一次next方法
迭代器遍历时,不能用集合的方法进行增加或删除,如果需要删除,需要使用迭代器提供的remove()方法
迭代器中删除的方法
public class IteratorDemo2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("b");
list.add("c");
list.add("d");
Iterator<String> it = list.iterator();
while(it.hasNext()){
String s = it.next();
if("b".equals(s)){
//指向谁,那么此时就删除谁.
it.remove();
}
}
System.out.println(list);
}
}26.4 List集合
26.4.1 List集合的特点
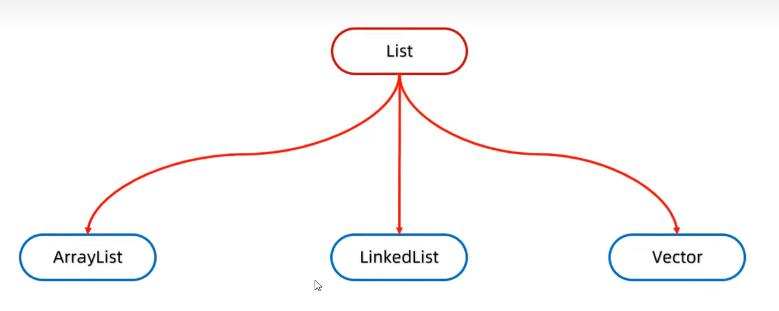
List集合的概述
有序集合,这里的有序指的是存取顺序
用户可以精确控制列表中每个元素的插入位置,用户可以通过整数索引访问元素,并搜索列表中的元素
与Set集合不同,列表通常允许重复的元素
List集合的特点
存取有序
可以重复
有索引
26.4.2 List集合的特有方法
Collection的方法List都继承了
多了很多有索引的方法
方法名称 | 说明 |
void add(int index, E element) | 在此集合中的指定位置插入指定元素 |
E remove(int index) | 删除指定索引处的元素,返回被删除的元素 |
E set(int index, E element) | 修改指定索引处的元素,返回被修改的元素 |
E get(int index) | 返回指定索引处的元素 |
26.4.3 ArrayList集合
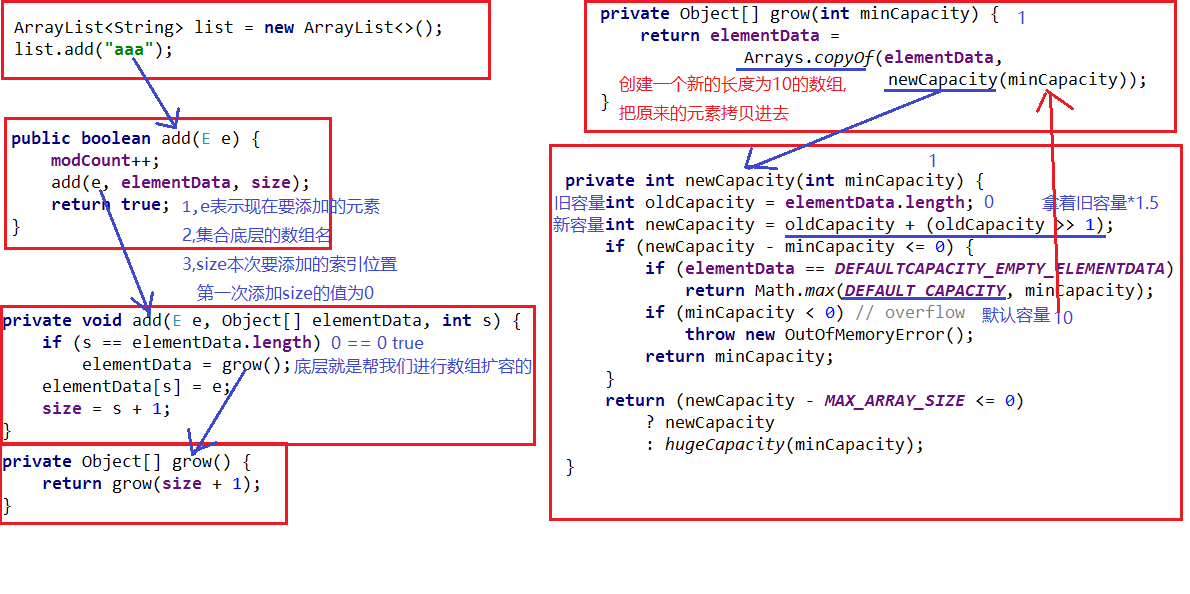
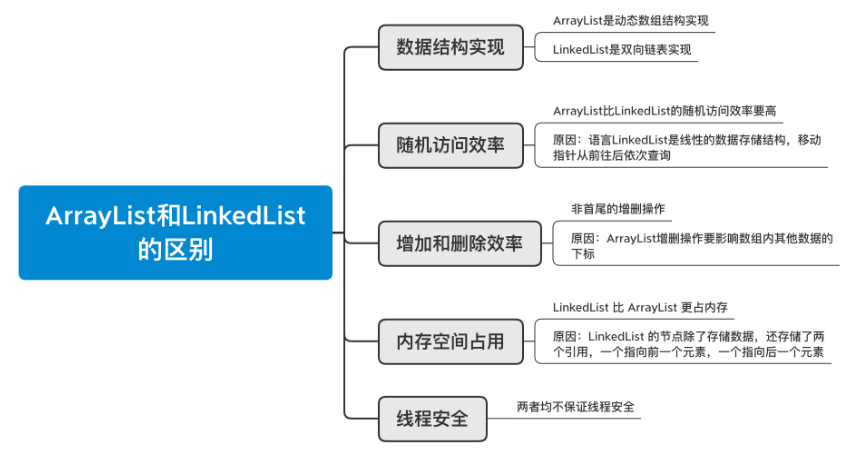
底层是数组结构实现,查询快、增删慢
利用空参构造创建的集合,在底层创建一个默认长度为0的数组
添加第一个元素时,底层会创建一个新的长度为10的数组
存满时,会扩容1.5倍
如果依次添加多个元素,1.5倍还放不下,则新创建数组长度以实际为准
ArrayList第一次添加元素源码分析
26.4.4 LinkedList集合
底层数据结构是双向链表,查询慢,增删快,但是如果操作的是首尾元素,速度也是极快的
方法:
方法名 | 说明 |
public void addFirst(E e) | 在该列表开头插入指定元素 |
public void addLast(E e) | 将指定的元素追加到此列表的末尾 |
public E getFirst() | 返回此列表的第一个元素 |
public E getLast() | 返回此列表的最后一个元素 |
public E removeFirst() | 从此列表中删除并返回第一个元素 |
public E removeLast() | 从此列表中删除并返回最后一个元素 |
26.4.5 ArrayList与LinkedList的区别
26.5 Set集合
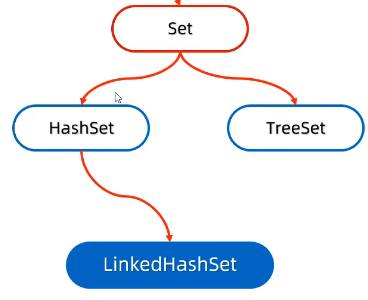
特点:无序,不重复,无索引
实现类
HashSet:无序、不重复、无索引
LinkedHashSet:有序、不重复、无索引
TreeSet:可排序、不重复、无索引
26.5.1 HashSet
HashSet底层采取哈希表存储结构
哈希表组成:
JDK8之前:数组+链表
JDK8开始:数组+链表+红黑树
哈希值:对象的整数表现形式
根据hashCode方法算出来的int类型的整数
该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算
一般情况下,会重写hashCode方法,利用对象内部的属性值计算哈希值
如果没有重写hashCode方法,不同对象计算出来的哈希值是不同的
如果重写hashCode方法,不同对象只要属性相同,计算出来的哈希值是相同的
在小部分情况下,不同属性值或者不同地址值计算出来的哈希值也有可能一样(哈希碰撞)
JDK8之前的HashSet:
默认创建一个长度为16,默认加载因子为0.75的数组
扩容机制:
当链表长度大于16*0.75=12时,列表扩容成原先的两倍
当前链表长度大于8而且数组长度大于等于64时,链表会自动转成红黑树
根据元素的哈希值跟数组的长度计算应存入的位置
判断当前位置是否为null,如果是null直接存入
如果位置不为null,表示有元素,则调用equals方法比较属性值
一样:不存 不一样:存入数组,形成链表
JDK8之前:新元素存入数组,老元素挂在新元素下面(头插法)
JDK8之前:新元素直接挂在老元素下面(尾插法)
利用hashCode和equals方法保证数据去重
26.5.2 LinkedHashSet
特点:有序(存储和取出的元素顺序一致)、不重复、无索引
原理:底层数据结构依然是哈希表,知识每个元素又多了一个双链表的机制记录存储的顺序
26.5.3 TreeSet
特点:不重复、无索引、可排序
TreeSet集合底层时基于红黑树的数据结构实现排序的,增删改查性能都比较好
默认的规则:
对于数值类型:Integer,Double,默认按照从小到大的顺序进行排序
对于字符、字符串类型:按照字符在ASCII码表中的数组升序进行排序
指定规则:
默认排序/自然排序:JavaBean类实现Comparable接口指定比较规则
public class Student implements Comparable<Student>{
private String name;
private int age;
public Student() {
}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
@Override
public int compareTo(Student o) {
//按照对象的年龄进行排序
//主要判断条件: 按照年龄从小到大排序
int result = this.age - o.age; //this:当前要添加的元素 o:已经在红黑树存在的元素
//次要判断条件: 年龄相同时,按照姓名的字母顺序排序
result = result == 0 ? this.name.compareTo(o.getName()) : result;
return result;
}
}比较器排序:创建TreeSet对象的时候,自定义Comparable比较器对象指定规则(默认使用第一种方式,如果第一种不能满足当前要求,就使用第二种)
//要求:按照年龄从小到大排序,年龄相同时,按照姓名的字母顺序排序
public class MyTreeSet4 {
public static void main(String[] args) {
//创建集合对象
TreeSet<Teacher> ts = new TreeSet<>(new Comparator<Teacher>() {
@Override
public int compare(Teacher o1, Teacher o2) {
//o1表示现在要存入的那个元素
//o2表示已经存入到集合中的元素
//主要条件
int result = o1.getAge() - o2.getAge();
//次要条件
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
});
//创建老师对象
Teacher t1 = new Teacher("zhangsan",23);
Teacher t2 = new Teacher("lisi",22);
Teacher t3 = new Teacher("wangwu",24);
Teacher t4 = new Teacher("zhaoliu",24);
//把老师添加到集合
ts.add(t1);
ts.add(t2);
ts.add(t3);
ts.add(t4);
//遍历集合
for (Teacher teacher : ts) {
System.out.println(teacher);
}
}
}两种比较器的对比:
自然排序: 自定义类实现Comparable接口,重写compareTo方法,根据返回值进行排序
比较器排序: 创建TreeSet对象的时候传递Comparator的实现类对象,重写compare方法,根据返回值进行排序
在使用的时候,默认使用自然排序,当自然排序不满足现在的需求时,必须使用比较器排序
两种比较器的返回值规则:
负数:添加的元素是小的,存左边 升序
正数:添加的元素是大的,存右边 降序
0:添加的元素已经存在,舍弃
27. 数据结构
常见的数据结构
栈、队列、数组、链表、二叉树、二叉查找树、平衡二叉树、红黑树
27.1 栈
特点:后进先出,先进后出

方法:
方法名 | 说明 |
Stack() | 创建Stack对象 |
public boolean isEmpty() | 判断栈是否为空 |
public int size() | 获取栈中元素的个数 |
public T pop() | 弹出栈顶元素 |
public void push(T t) | 向栈中压入元素t |
27.2 队列
特点:先进先出,后进后出

方法:
方法名 | 说明 |
Queue | 创建Queue对象 |
public boolean isEmpty() | 判断队列是否为空 |
public int size() | 获取队列中元素的个数 |
public T dequeue() | 从队列中拿出一个元素 |
public void enqueue(T t) | 往队列中插入一个元素 |
27.3 数组
查询速度快:查询数据通过地址值和索引定位,查询任意数据耗时相同
删除慢:要将原始数据删除,同时后面的每个数据前移
添加慢:添加位置后的每个数据后移,在添加元素

27.4 链表
链表是一种物理存储单元上非连续、非顺序的存储结构,其物理结构不能只管的表示数据元素的逻辑顺序,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。每个节点包含数据值和下一个结点的地址
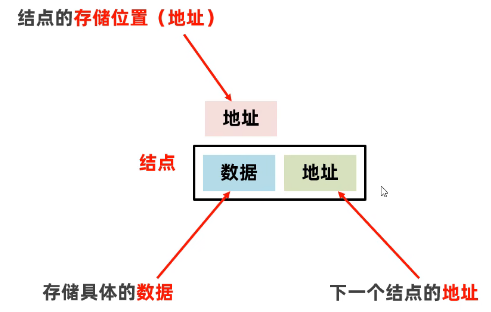
创建一个链表

链表查询慢,无论查询哪个数据都要从头开始
链表增删快
增加
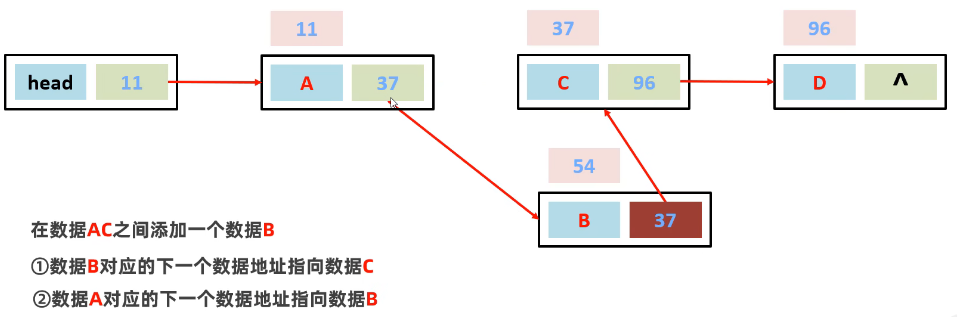
删除
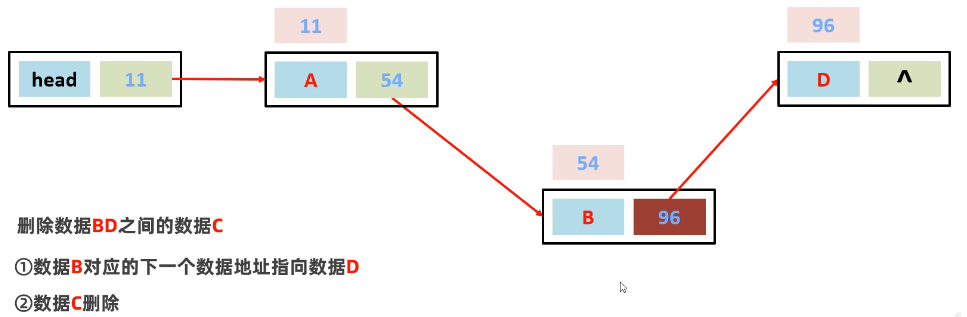
结点类实现
public class Node<T> {
//存储元素
public T item;
//指向下一个结点
public Node next;
public Node(T item, Node next) {
this.item = item;
this.next = next;
}
}生成链表
public static void main(String[] args) throws Exception {
//构建结点
Node<Integer> first = new Node<Integer>(11, null);
Node<Integer> second = new Node<Integer>(13, null);
Node<Integer> third = new Node<Integer>(12, null);
//生成链表
first.next = second;
second.next = third;
}27.4.1 单向链表
单向链表是链表的一种,它由多个结点组成,每个结点都由一个数据域和一个指针域组成,数据域用来存储数据,指针域用来指向其后继结点。链表的头结点的数据域不存储数据,指针域指向第一个真正存储数据的结点。

27.4.2 双向链表
双向链表也叫双向表,是链表的一种,它由多个结点组成,每个结点都由一个数据域和两个指针域组成,数据域用来存储数据,其中一个指针域用来指向其后继结点,另一个指针域用来指向前驱结点。链表的头结点的数据域不存储数据,指向前驱结点的指针域值为null,指向后继结点的指针域指向第一个真正存储数据的结点。

27.5 树
27.5.1 二叉树的概述
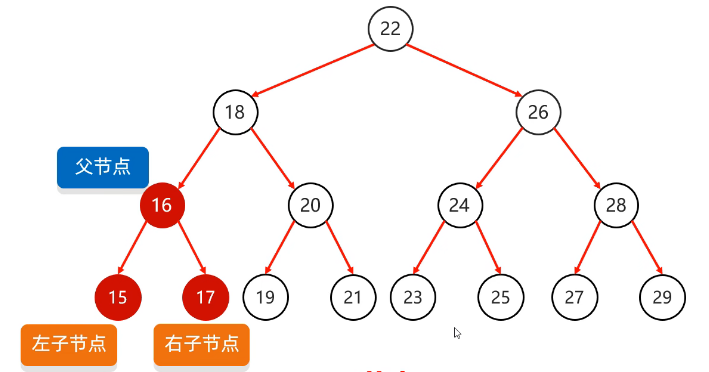
节点的度:每一个节点的子节点数量
二叉树:任意节点的度 <= 2
树高:树的总层数
27.5.2 二叉查找树
二叉查找树又叫二叉搜索树
特点:
每一个节点上最多右两个子节点
任意节点左子树上的值都小于当前节点
任意节点右子树上的值都大于当前节点
中序遍历是有序的
代码实现:
public class TreeNode {
int val;
TreeNode left;
TreeNode right;
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}添加节点:
如果当前树中没有任何一个结点,则直接把新结点当做根结点使用
如果当前不为空,则从根结点开始:
2.1如果新结点的value小于当前结点的value,则继续找当前结点的左子结点;
2.2如果新结点的value大于当前结点的value,则继续找当前结点的右子结点;
2.3如果新结点的value等于当前结点的value,则树中已经存在这样的结点,替换该结点的value值即可。
查询节点:从根节点开始:
如果要查询的value小于当前结点的value,则继续找当前结点的左子结点;
如果要查询的value大于当前结点的value,则继续找当前结点的右子结点;
如果要查询的value等于当前结点的value,则树中返回当前结点的value。
27.5.3 二叉树的遍历方式
按照根节点什么时候被访问,可以把二叉树的遍历分为以下三种方式:
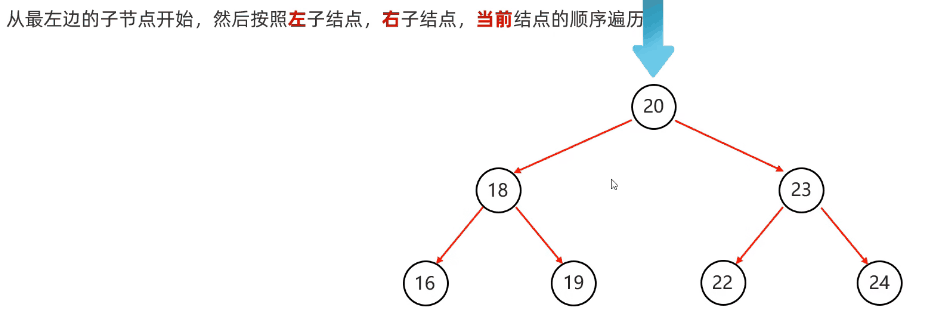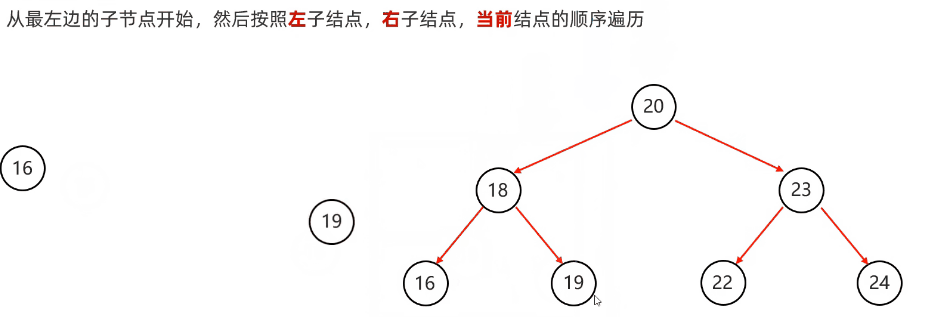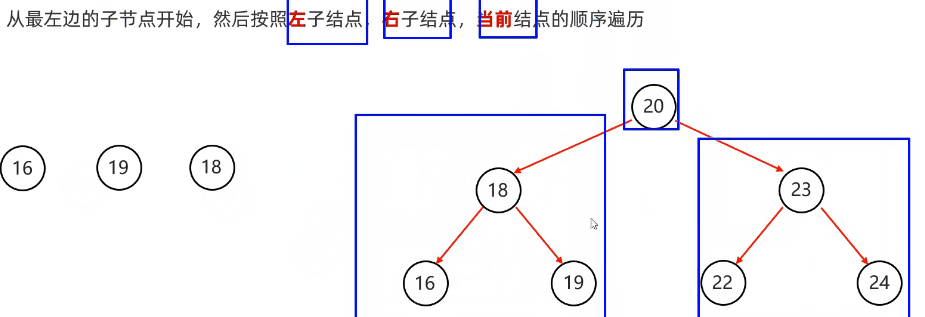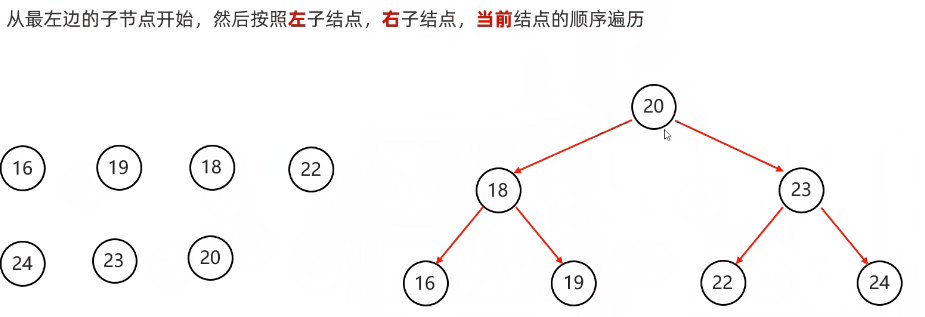
前序遍历:从根节点开始,然后按照当前节点,左子节点,右子节点的顺序遍历
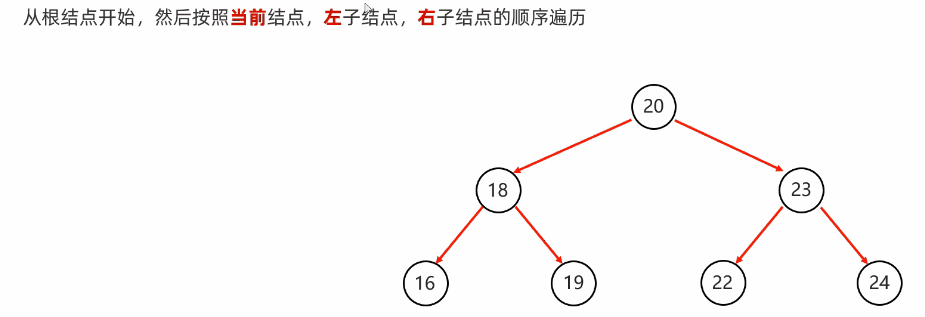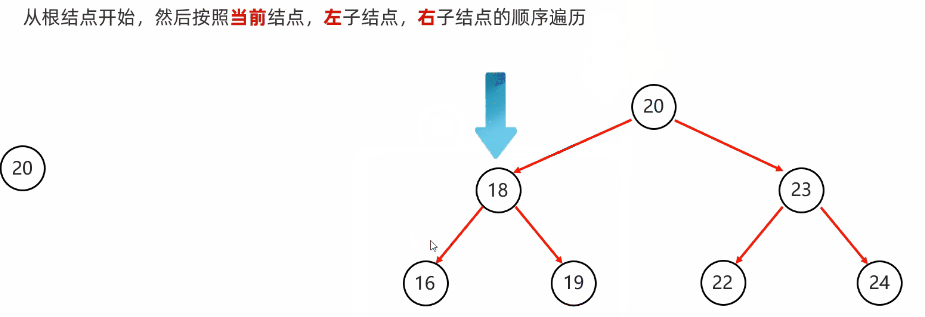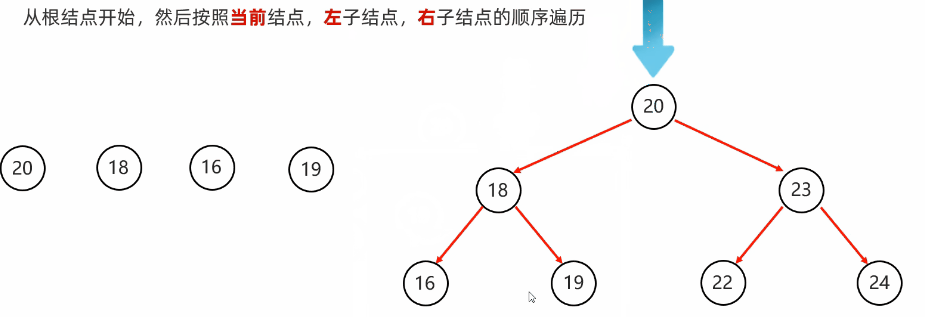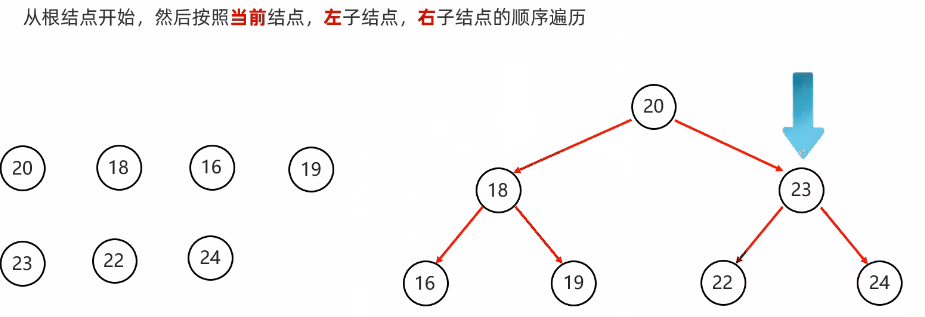
代码实现
public List<Integer> preorderTraversal(TreeNode root) {
List<Integer> result = new ArrayList<Integer>();
preorder(root, result);
return result;
}
public void preorder(TreeNode root, List<Integer> result) {
if (root == null) {
return;
}
result.add(root.val); //中
preorder(root.left, result); //左
preorder(root.right, result); //右
}中序遍历:从根节点开始,然后按照左子节点,当前节点,右子节点的顺序遍历
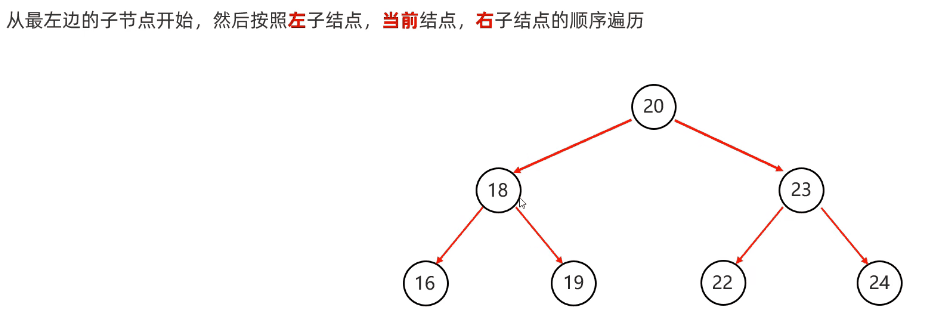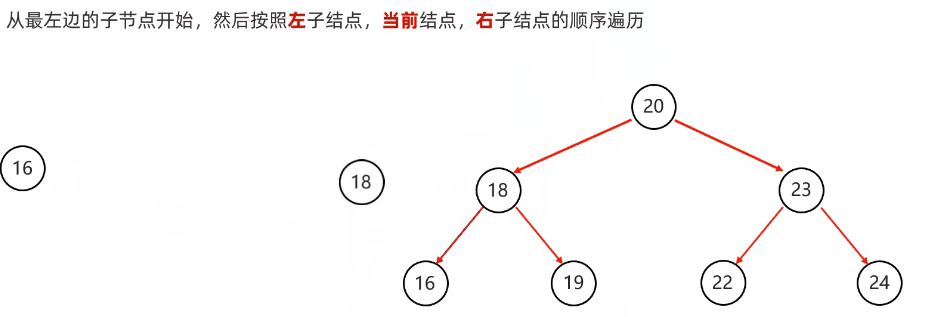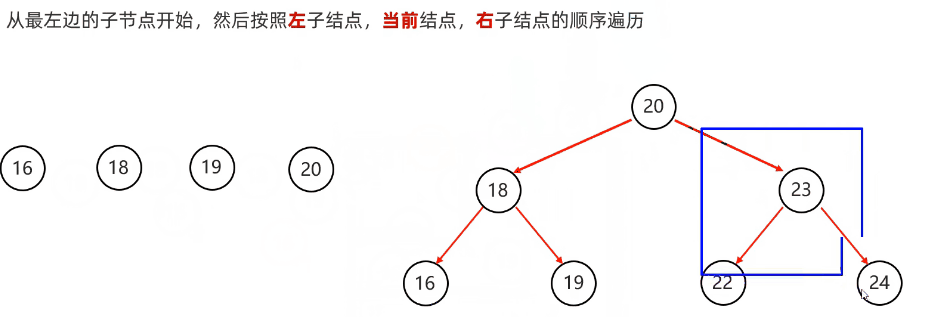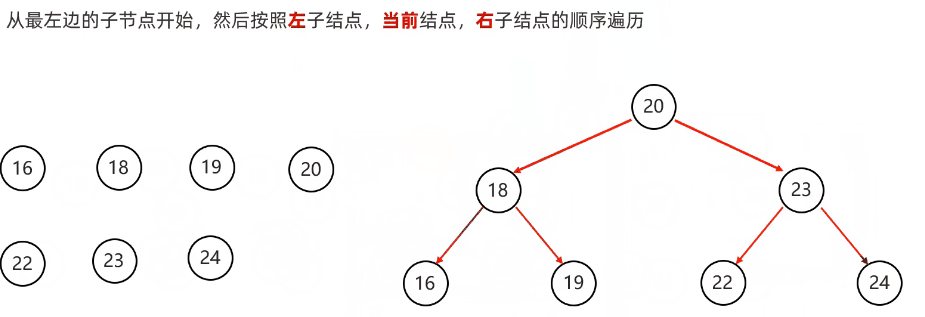
代码实现:
public List<Integer> inorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
inorder(root, res);
return res;
}
void inorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
inorder(root.left, list);
list.add(root.val); // 注意这一句
inorder(root.right, list);
}后序遍历:从根节点开始,然后按照左子节点,右子节点,当前节点的顺序遍历
代码实现:
public List<Integer> postorderTraversal(TreeNode root) {
List<Integer> res = new ArrayList<>();
postorder(root, res);
return res;
}
void postorder(TreeNode root, List<Integer> list) {
if (root == null) {
return;
}
postorder(root.left, list);
postorder(root.right, list);
list.add(root.val); // 注意这一句
}层序遍历:一层一层的去遍历

代码实现:
public List<List<Integer>> resList = new ArrayList<List<Integer>>();
public List<List<Integer>> levelOrder(TreeNode root) {
checkFun01(root,0);
return resList;
}
//DFS--递归方式
public void checkFun01(TreeNode node, Integer deep) {
if (node == null) return;
deep++;
if (resList.size() < deep) {
//当层级增加时,list的Item也增加,利用list的索引值进行层级界定
List<Integer> item = new ArrayList<Integer>();
resList.add(item);
}
resList.get(deep - 1).add(node.val);
checkFun01(node.left, deep);
checkFun01(node.right, deep);
}27.5.4 平衡二叉树
规则:任意节点左右子树高度差不超过1
平衡化:从添加的结点开始,不断地往父节点找不平衡的节点
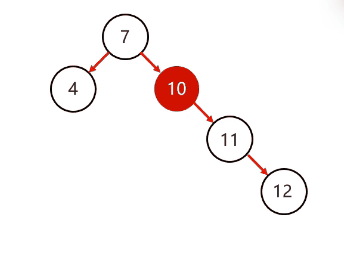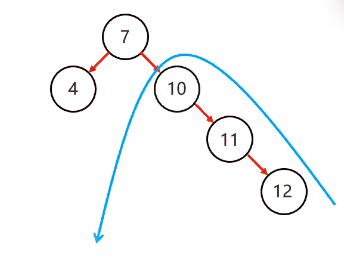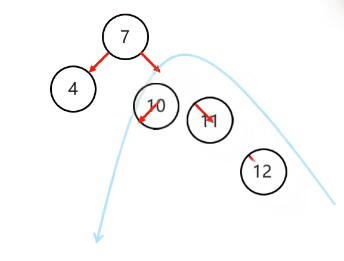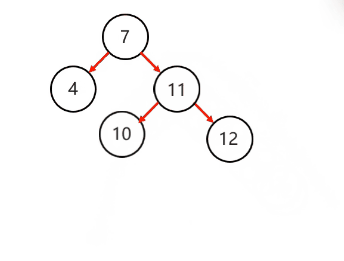
左旋步骤:
简单情况:
以不平衡的点作为支点
把支点左旋降级,变成左子节点
晋升原来的右子节点
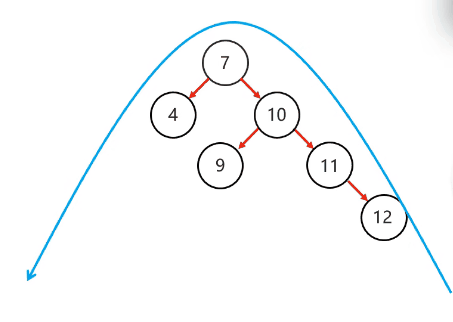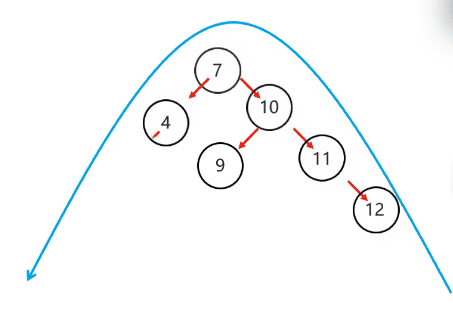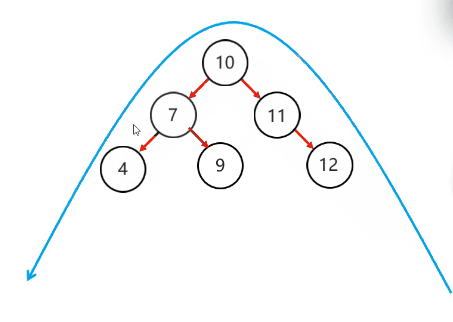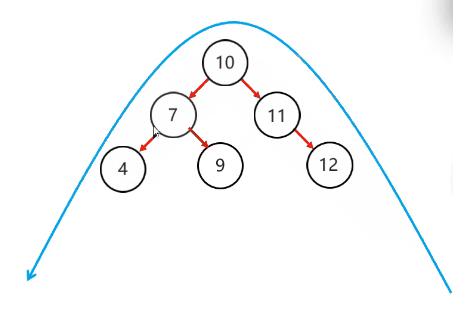
复杂情况:
以不平衡的点作为支点
将根节点的右侧往左拉
原先的右子节点变成新的父节点,并把多余的左子节点出让,给已经降级的根节点当右子节点
右旋步骤:
简单情况:
以不平衡的点为支点
把支点右旋降级,变成右子节点
晋升原来的左子节点
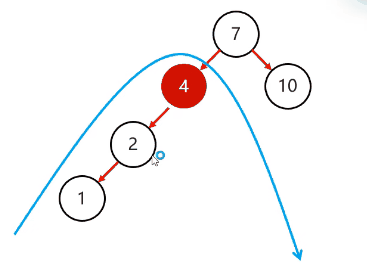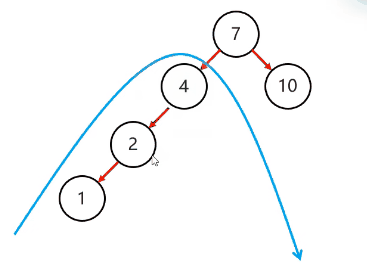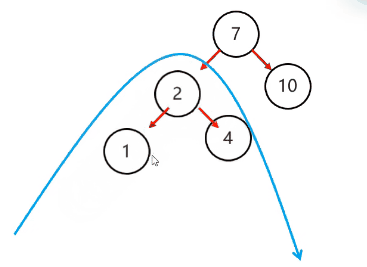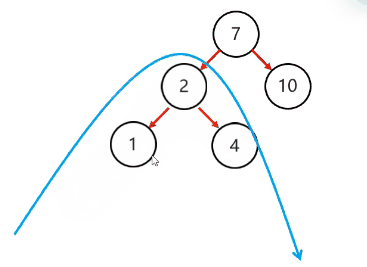
复杂情况:
以不平衡的点作为支点
将根节点的左侧往右拉
原先的左子节点变成新的父节点,并把多余的右子节点出让,给已经降级的根节点当左子节点
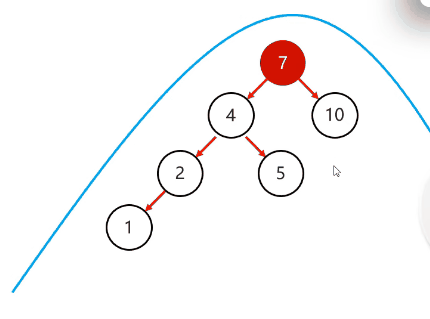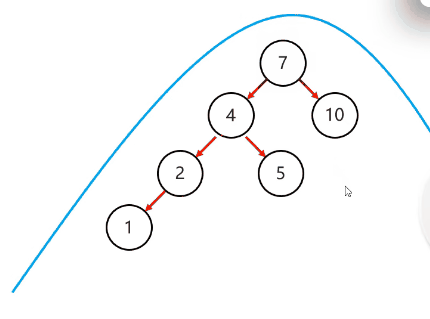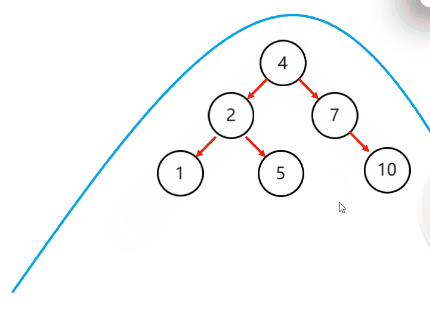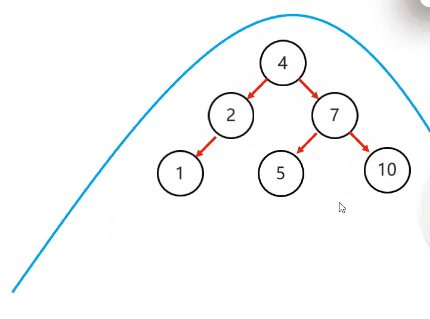
需要旋转的四种情况:
左左:一次右旋
左右:先局部左旋,再整体右旋
右右:一次左旋
右左:先局部右旋,再整体左旋
27.5.5 红黑树
红黑树是一种自平衡的二叉查找树
每个节点可以是红或者黑;红黑树不是高度平衡的,它是通过”红黑规则“进行实现的
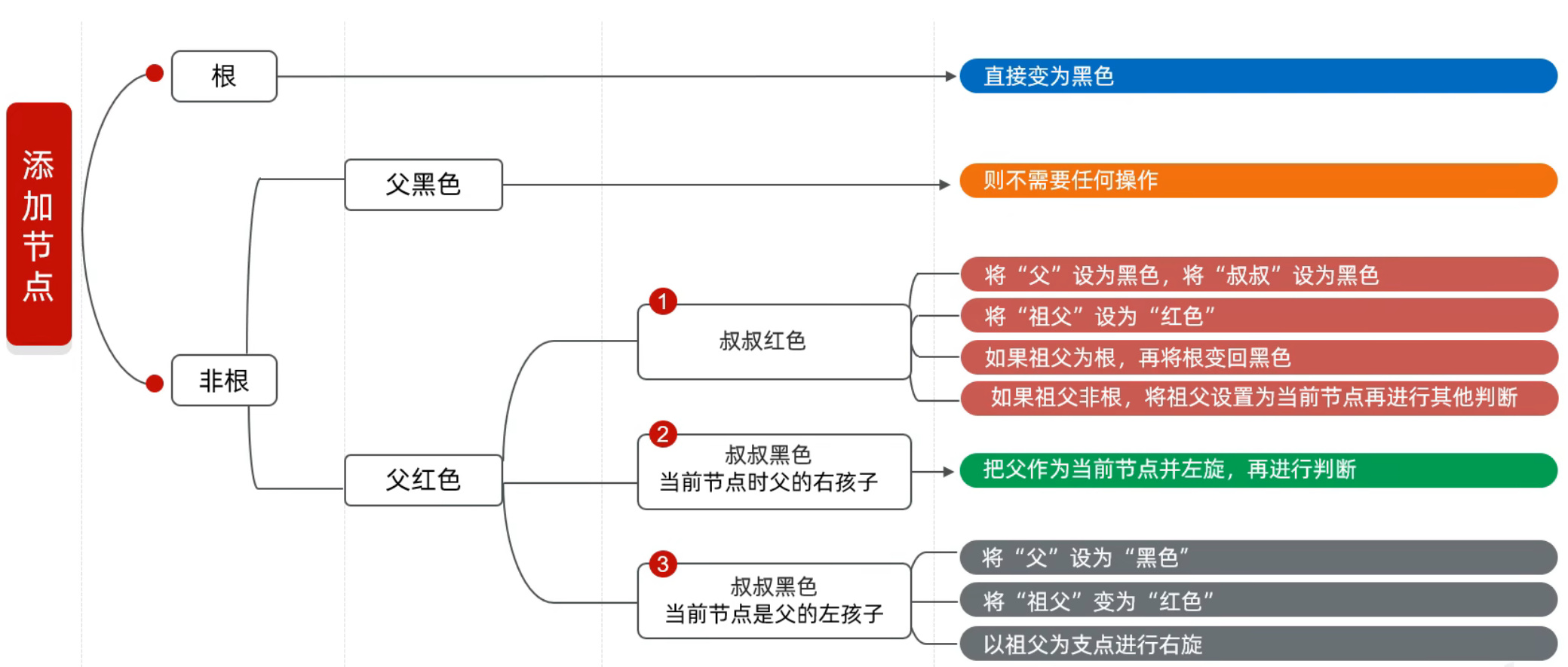
红黑规则:
每一个节点只能是黑色或者红色
根节点必须是黑色的
如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这鞋Nil视为叶节点,每个Nil是黑色的
如果某一个节点是红色的,那么它的子节点必须是黑色的(不能出现两个红色节点相连的情况)
对每一个节点,从该节点到其左右后代子叶上的简单路径上,均包含相同数目的黑色节点
添加节点默认是红色的(效率高)
添加规则:















 138
138











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









