







 本文深入解析了EDVR视频恢复框架,它使用金字塔、级联和可变形(PCD)对齐模块处理大运动,并通过时间空间注意力(TSA)融合模块有效融合特征。这一通用架构适用于视频超分辨率、去模糊、去噪等任务,通过学习对齐和融合,实现出色的视频恢复效果。
本文深入解析了EDVR视频恢复框架,它使用金字塔、级联和可变形(PCD)对齐模块处理大运动,并通过时间空间注意力(TSA)融合模块有效融合特征。这一通用架构适用于视频超分辨率、去模糊、去噪等任务,通过学习对齐和融合,实现出色的视频恢复效果。
EDVR: Video Restoration with Enhanced Deformable Convolutional Networks
(这篇文章当时写的时候还没入门视频超分,只是粗略的记录了当时的阅读经历,现在重新写了一篇细致的EDVR,欢迎阅读 2022.5.4)
论文地址:https://arxiv.org/abs/1905.02716
代码地址:https://github.com/xinntao/EDVR.
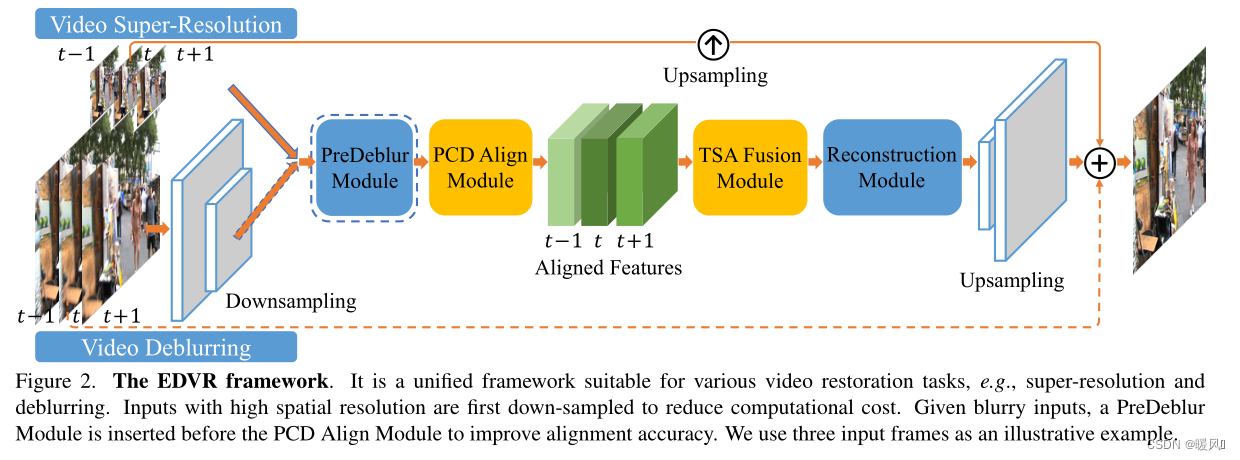
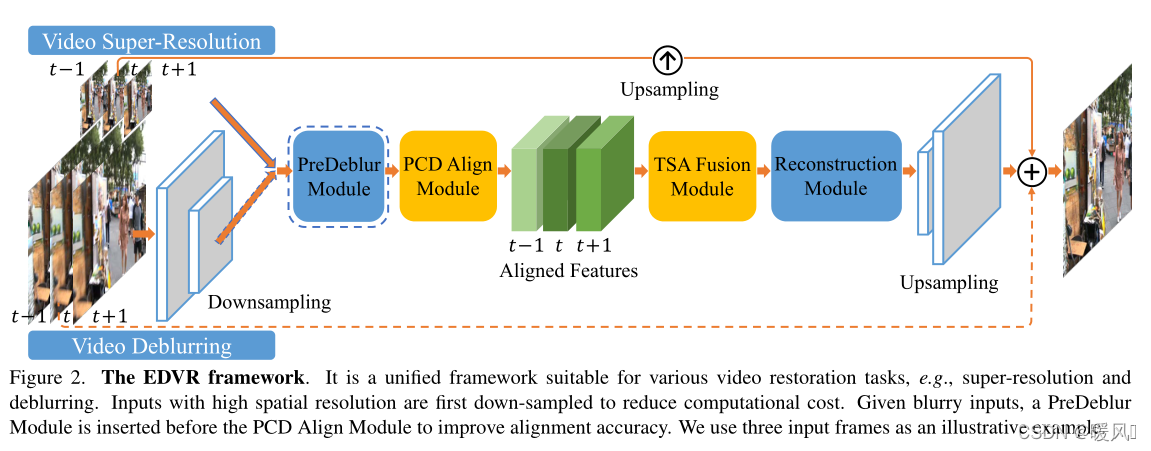
文章提出了一种新的具有增强可变形卷积的视频恢复框架,称为EDVR。是适用于多种视频恢复任务的通用体系结构,包括超分辨率、去模糊、去噪、去块等。
从两个方向提出了本方法:
(1)如何在给定大运动的情况下对齐多个帧;
(2)如何有效地融合具有不同运动和模糊的不同帧。
这两方面具体是:
- 为了处理大的运动,设计了一个金字塔、级联和可变形(PCD)对齐模块,在该模块中,帧对齐是在特征级别上以从粗到精的方式使用可变形卷积进行的。
- 提出了一个时间和空间注意(TSA)融合模块,在该模块中,注意在时间和空间上都被应用,以便强调后续恢复的重要特征。
使用“真实和多样场景数据集”(REDS),其中包含更大,更复杂的运动。
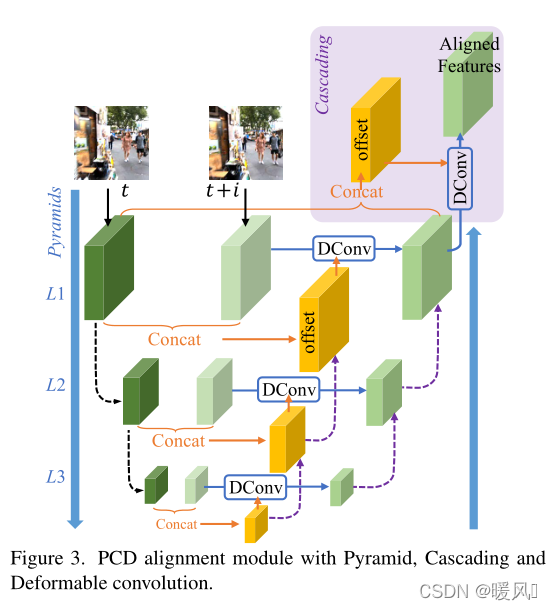
金字塔、级联和可变形卷积的对齐
1、金字塔、级联和可变形卷积的对齐:
大多数现有方法通过明确估计参考帧与其相邻帧之间的光流场来执行对齐。另一个研究分支通过动态滤波或可变形卷积实现隐式运动补偿。对于基于流的方法来说,精确的流估计和精确的翘曲可能具有挑战性且耗时。在大运动的情况下,很难在单个分辨率范围内显式或隐式执行运动补偿。
EDVR使用金字塔、级联和可变形卷积。以从粗到精的方式执行对齐,以处理大型和复杂的运动。具体来说,使用金字塔结构,首先将较低尺度的特征与粗略估计对齐,然后将偏移和对齐的特征传播到较高尺度,以促进精确的运动补偿,类似于光流估计中采用的概念。此外,在金字塔对齐操作之后级联了额外的可变形卷积,以进一步提高对齐的鲁棒性。
具体实现:
如下图3中的黑色虚线所示,为了在第
l
l
l 级生成特征
F
t
+
i
l
F^l_{t+i}
Ft+il,使用跨步卷积滤波器在金字塔
(
l
−
1
)
(l-1)
(l−1) 层对特征进行down scale factor=2的降采样,获得特征表示的
l
l
l 级金字塔。在第
l
l
l 级,偏移和对齐特征也分别使用
(
l
+
1
)
(l+1)
(l+1)级的
×
2
×2
×2 上采样偏移和对齐特征进行预测。
在金字塔结构之后,随后的可变形对齐被层叠,以进一步细化粗略对齐的特征(图3中浅紫色背景的部分)。PCD模块以这种从粗到精的方式改进对准到亚像素精度。 值得注意的是,PCD对准模块与整个框架一起学习,没有额外的监督,也没有对光流等其他任务进行预培训。
时间空间注意力融合
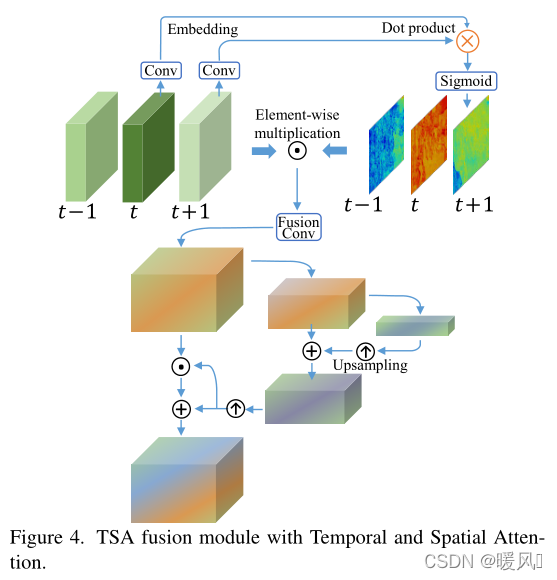
2、时间空间注意力融合:
融合对齐帧的特征是视频恢复任务中的另一个关键步骤。大多数现有方法要么使用卷积对所有帧进行早期融合,要么采用递归网络逐步融合多个帧。这些现有的方法都不考虑每一帧的基础视觉信息——不同的框架和位置不一定是有益的或有益于重建,因为一些帧或区域受到不完美的对齐和模糊的影响。
EDVR提出的TSA是一个融合模块,有助于跨多个对齐特征聚合信息。为了更好地考虑每个帧上的视觉信息量,通过计算参考帧和每个相邻帧的特征之间的元素相关性来引入时间注意。其次,相关系数对每个位置的每个相邻特征进行加权,指示其对重建参考图像的信息量。然后对所有帧的加权特征进行卷积和融合。在与时间注意融合后,进一步应用空间注意为每个通道中的每个位置分配权重,以更有效地利用跨通道和空间信息。
具体实现:
在融合过程中采用了时间和空间注意,如图4所示。使用TSA融合模块来为每一帧分配像素级的聚合权重。在嵌入空间中,应该更多地关注与参考帧更相似的相邻帧。对于每个帧
i
∈
[
−
N
:
+
N
]
i∈{[-N:+N]}
i∈[−N:+N], 相似距离
h
h
h 可以计算为:
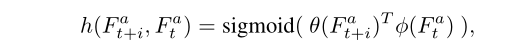
其中
θ
(
F
t
+
i
a
)
和
ϕ
(
F
t
a
)
\theta( F^a_{ t + i }) 和 \phi(F_{t}^a)
θ(Ft+ia)和ϕ(Fta) 是两个embeddings,可以使用简单的卷积滤波器实现。Sigmoid激活函数用于将输出限制为[0,1],稳定梯度反向传播。然后,以像素方式将时间注意力图和原始对齐特征
F
t
+
i
a
F^a_{t+i}
Ft+ia相乘。用一个额外的融合卷积层来融合这些注意力调制特征:
θ
(
F
t
+
i
a
)
~
\tilde{\theta( F^a_{ t + i })}
θ(Ft+ia)~。
根据融合后的特征计算出空间注意遮盖。金字塔的设计被用来增加注意力的接收范围。之后,融合特征由掩模通过元素乘法和加法进行调制。
整体架构
给定
2
N
+
1
2N+1
2N+1个连续的低质量帧
I
[
t
−
N
:
t
+
N
]
I_{[t−N:t+N]}
I[t−N:t+N],将中间帧
I
t
I_t
It表示为参考帧,其他帧表示为相邻帧。视频恢复的目的是估计一个高质量的参考帧
O
t
~
\tilde{O_t}
Ot~,它接近地面真实帧
O
t
O_t
Ot。
以视频SR为例,EDVR将2N+1个低分辨率帧作为输入,并生成高分辨率输出。PCD对齐模块在特征级将每个相邻帧与参考帧对齐。TSA融合模块融合不同帧的图像信息。融合后的特征然后通过重建模块,重建模块是EDVR中残余块的级联,可以很容易地被单图像SR中的任何其他高级模块替换。在网络的末端执行上采样操作以增加空间大小;最后,通过将预测图像残差与直接上采样图像相加,获得高分辨率帧
O
t
^
\hat{O_t}
Ot^。
对于具有高空间分辨率输入的其他任务,例如视频去模糊,输入帧首先使用跨步卷积层进行下采样。然后大部分计算在低分辨率空间中进行,这在很大程度上节省了计算成本。最后的上采样层会将特征调整回原始输入分辨率。在对齐模块之前使用预模糊模块来预处理模糊输入并提高对齐精度。
采用了两阶段策略,具体来说就是级联相同的EDVR网络,但深度较浅,以细化第一阶段的输出帧。级联网络可以进一步消除先前模型无法处理的严重运动模糊。
实验:
PCD对齐模块采用五个残差块(RB)进行特征提取。在重建模块中使用40个RBs,在第二阶段模型中使用20个RBs。每个残差块中的通道大小设置为128。我们分别使用大小为
64
×
64
64\times 64
64×64和
256
×
256
256\times 256
256×256的RGB块作为视频SR和去模糊任务的输入。最小批量大小设置为32。除非另有规定,否则网络采用五个连续帧(即N=2)作为输入。我们用随机水平翻转和90°旋转来增加训练数据。只采用Charbonnier惩罚函数作为最终损失,
使用Adam optimizer通过设置
β
1
=
0.9
,
β
2
=
0.999
β1=0.9,β2=0.999
β1=0.9,β2=0.999。学习速率初始化为
4
×
1
0
−
4
4×10^{−4}
4×10−4。通过较浅网络的参数初始化较深网络,以加快收敛速度。使用8个NVIDIA Titan Xp GPU对它们进行培训。
在测试期间,翻转并旋转输入图像,为每个样本生成四个增强输入。然后,我们对每个输出应用EDVR方法,对恢复的输出进行反向转换,并对最终结果进行平均。使用两阶段恢复策略。
具体结果看论这里就不放了。论文中实验结果对比了以往的方法、有无PCD和TSA对结果的影响。能够证明具有很好的效果。
顺便写个段前空格的方式
//半角空格(英文)
  //全角空格(中文)
最后祝各位科研顺利,身体健康,万事胜意~

















 394
394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









