







Deformable Convolution Network
inspiration
这篇论文就是在讲通过自主学习一个offset(偏置),能够将感受野变换成目标形状,而不是固定的矩形。得到更多有用信息。
学习空间几何形变的能力,得到可变形卷积网络。
就很像我们之前的通过一个网络学习特征偏差(源域和目标域)
有点像space attention
这里使用了双线性插值代替了之前他们做的文章里的权重,很有意思,需要看看之前的文章!
Motivation
how to accommodate geometric variations or model geometric transformations in object scale, pose, viewpoint, and part deformation.
如何适应几何变体,或者是几何变形一直是视觉识别所要解决的问题

Traditional Approaches
-
Build the training datasets with sufficient desired variations (训练足够大规模的数据覆盖所有的变形情况)
-
Use transformation-invariant features and algorithms, i.e., SIFT (设计学习变形不变特征的算法,如SIFT“尺度不变特征变换”:1.提取关键点,如角点,边缘点,这些关键点在变形,伸缩之后还是会存在;2. 对定位的特征点构建特征方向;3. 对比特征向量 )
-
Drawbacks: geometric transformations are assumed fixed and known, hand-crafted design of invariant features and algorithms (几何变换被认为是固定模式的,无法考虑到没见过的情况;手动设计算法)
Spatial Transformations in CNNs
Regular CNNs are inherently limited to model large unknown transformations, which originates from the fixed geometric structures of CNN modules.
(传统CNN还是很依赖于固定的几何结构,比如矩形感受野的convolution 和 pooling, 还有需要大量已知变换)

DCN
提出了两个改进的Convolution操作和Pooling操作
- Deformable Convolution
- Deformable RoI Pooling
2D Convolution

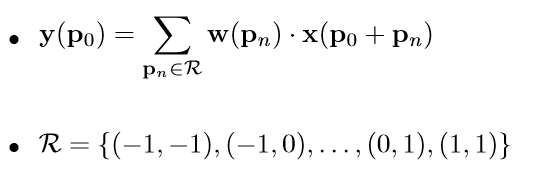

双线性插值 bilinear
很多代码都用到了,真的需要记住。
这篇论文,是在增加偏置的时候,由于偏置可能是小数,所以存在要求的像素点不在整数的坐标上。


RoI Pooling
要求对原来的feature map 固定一个interets of Region,也许不是kernel的大小,比如ROI为34,并且要求分割成33的大小,会有9个bin。于是,feature map不是均匀分割。看公式要求怎么加值。


Experiments






















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









