







本文只是简单介绍这些文章的算法和网络结构,详细内容可以在我的博客内找,这几篇里SRLUT是比较新的(2021)。
原文链接:
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
SRLUT: Practical Single-Image Super-Resolution Using Look-Up Table 【CVPR2021】
ESPCN:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network
VESPCN: Real-Time Video Super-Resolution with Spatio-Temporal Networks and Motion Compensation
RCAN
RCAN: Image Super-Resolution Using Very Deep Residual Channel Attention Networks
这篇文章网络是迄今为止最深的(是指该篇文章的时间)。
文章主要目的就是冲着深度去的,训练了一个非常深的网络,提出了RIR结构、提出了通道注意力机制CA。

这篇文章主要两个点:
- 通过多层套娃(三次),训练了一个非常深的网络(超400层),提出了RIR结构。
- 作者认为特征图像不同通道包含不同重要程度的信息,于是提出了通道注意力机制CA。
RCAN主要包括四个部分:浅层特征提取、Residual in Residual(RIR)深度特征提取、上采样和重建部分。
本文的重心放在RIR部分,其他部分和EDSR和RDN基本是一样的,所以不多做介绍。
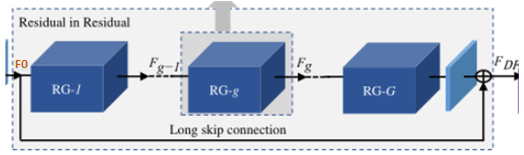
RIR部分总体结构:RIR由RG作为基础模块,由一个长跳跃连接LSC的多个残差群组RG组成。每个RG包含一些具有短跳跃连接SSC的通道残差块RCAB。每个通道注意力残差块RCAB由简单残差块BN和通道注意力机制CA组成。
-
先看第一层(最外层):
RIR由RG作为基础模块,由一个长跳跃连接LSC的G个残差群组RG组成。
长跳跃连接(LSC),能够稳定超深网络的训练,还能简化RGs之间的信息流,而且将浅层信息和深层信息相融合,增强图像信息,减少信息丢失。
-
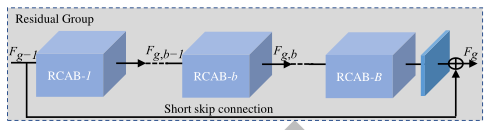
第二层:每个
RG包含一条短跳跃连接SSC和B个通道残差块RCAB。
短跳跃连接(SSC),能够融合不同层级的局部特征信息。
-
在讲第三层之前先介绍一下通道注意力机制CA,因为在最内层结构中用到了。
不同通道包含的特征信息是不同的,所以需要分配给每个通道不同的权重,让网络更加的关注一些包含重要信息的通道,于是引入了注意力机制。
使用全局平均池化将每个通道的全局空间信息转化为通道描述符(一个常数,其实就是每个通道一个权重值)。
先将每个通道的特征经过全局池化转化为一个常数,再经过卷积1( W D W_D WD)+ReLU+卷积2( W U W_U WU)+sigmoid得到最终的权重值s。
卷积1将通道数缩小到 C r \frac{C}{r} rC,卷积2将通道数放大回C。最后得到的权重s与原本的特征x相乘,得到权重分配后的特征。
CA通过关注通道之间的相互依赖性,自适应地重新分配通道特征的权重.

-
第三层:每个通道注意力残差块
RCAB由简单残差块BN和通道注意力机制CA组成。(最内层)
普通残差块由卷积+ReLU+卷积层构成,串联一个通道注意力机制CA,还有一条跳跃连接。

再复习一下RCAN结构:浅层特征提取、Residual in Residual(RIR)深度特征提取、上采样和重建部分。RIR由RG作为基础模块,由一个长跳跃连接LSC的多个残差群组RG组成。每个RG包含一些具有短跳跃连接SSC的通道残差块RCAB。每个通道注意力残差块RCAB由简单残差块BN和通道注意力机制CA组成。
总结:这篇文章提出的网络深度非常的深
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 39
39











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









