






加密流量分类torch实践4:TrafficClassificationPandemonium项目更新1-2
更新日志
代码已经推送开源至露露云的github,如果能帮助你,就给鼠鼠点一个star吧!!!
3/10号更新
流量预处理更新
-
增加了基于
splitCap.exe分流预处理,并且除了提取负载与包长序列后,支持提取统计特征(26维度)。26维度统计分别为
"Avg_syn_flag", "Avg_urg_flag", "Avg_fin_flag", "Avg_ack_flag", "Avg_psh_flag", "Avg_rst_flag", "Avg_DNS_pkt", "Avg_TCP_pkt", "Avg_UDP_pkt", "Avg_ICMP_pkt", "Duration_window_flow", "Avg_delta_time", "Min_delta_time", "Max_delta_time", "StDev_delta_time", "Avg_pkts_lenght", "Min_pkts_lenght", "Max_pkts_lenght", "StDev_pkts_lenght", "Avg_small_payload_pkt", "Avg_payload", "Min_payload", "Max_payload", "StDev_payload", "Avg_DNS_over_TCP", "Num_pkts"从
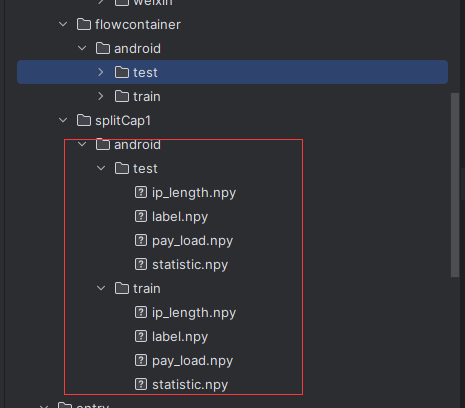
entry.pcap2npy/1_preprocess_with_splitCap_1.py进入配置文件preprocess下路径要为windows格式
运行完的预览图,可以看到有statistic.npy的统计特征文件
- 增加了基于
cic-meterflower工具对pcap的处理,将pcap处理为csv格式文件
使用
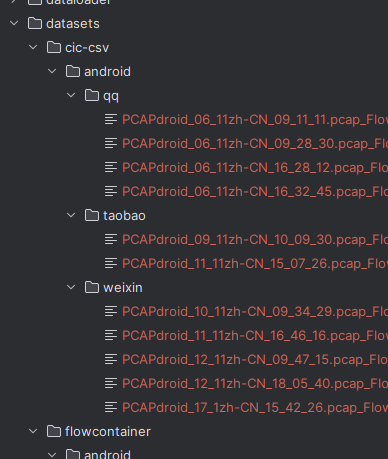
entry.pcap2csv/1_preprocess_with_cic.py,参考博客流量预处理-3:利用cic-flowmeter工具提取流量特征修改相应的路径变量注意:pcap路径与名称在使用该方式处理时不能出现中文,否则报错。
运行完的预览图,可以看到已经对中文进行改名,出现各个标签的csv文件
3/23日更新
当前更新对运行项目是无影响的,也就是说如果你是仅仅使用项目而不进行扩展的话,此处更新是透明的,对当前仓库版本的代码可以不进行同步。
代码已经推送开源至露露云的github,如果能帮助你,就给鼠鼠点一个star吧!!!
模型结构更新
简要:由原先各个模型独立抽象出了一个
base_model模型基类,由该基类继承nn.Module类,定义抽象方法forward与data_trans,方便不同模型进行各自的数据变换
-
为什么要改?
dataloader给模型输入的数据格式是固定死的,给每一个模型设定不同的dataloader违背了项目多个模型统一代码原则,而不同模型对于数据的输入样式是不同的,为了适用于之后会加入项目的模型,抽象出一个基类,设定一个data_trans抽象方法,每一个模型都根据模型的输入去实现该方法即可,这样做到了不更改dataloader的目的,做到代码复用 -
dataloader给定的数据样式?分析日志可以给出以下各个维度下
dataloader给定的数据shape[2024-03-23 17:19:38,802 INFO] 是否使用 GPU 进行训练, cuda [2024-03-23 17:19:44,781 INFO] 成功初始化模型. [2024-03-23 17:19:44,814 INFO] pcap 文件大小, torch.Size([404, 1, 1024]); seq文件大小:torch.Size([404, 128, 1]); sta文件大小: torch.Size([404, 1024]); label 文件大小: torch.Size([404]) [2024-03-23 17:19:44,851 INFO] pcap 文件大小, torch.Size([404, 1, 1024]); seq文件大小:torch.Size([404, 128, 1]); sta文件大小: torch.Size([404, 1024]); label 文件大小: torch.Size([404]) [2024-03-23 17:19:44,851 INFO] 成功加载数据集.负载pay: [batch_size,1,m*n]
包长seq: [batch_size,seq_len,1]
统计sta: [batch_size,sta_len]
- m*n是预处理的前m个包的前n个字节,这里目前写的是4*256也就是1024
- seq_len是预处理的前ip_length个包长,这里目前是128
- sta_len是预处理的统计维度,在10号更新的数据下是26














 3204
3204











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









