







一、梯度下降算法
1.简介
梯度下降算法是一种求解函数最优值的迭代算法,给定一个初值,通过负梯度方向进行更新查找。
2.程序实现及结果
import matplotlib.pyplot as plt
# 训练集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 初始化权重
w = 1.0
# 定义线性拟合函数
def forward(x):
return x * w
# 定义损失函数(均方误差)
def cost(xs, ys):
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred - y) ** 2
return cost / len(xs)
# 定义梯度函数
def gradient(xs, ys):
grad = 0
for x, y in zip(xs, ys):
grad += 2 * x * (x * w - y)
return grad / len(xs)
# 存储迭代次数和损失函数
epoch_list = []
cost_list = []
print('predict (before training):','x = 4','y=',forward(4)) #训练之前:预测
# 梯度下降算法
for epoch in range(100):
cost_val = cost(x_data, y_data)
grad_val = gradient(x_data, y_data)
w -= 0.05 * grad_val # 0.01 learning rate
print('epoch:', epoch, 'w=', w, 'loss=', cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
print('predict (after training):','x = 4','y =',forward(4)) #训练之后:预测
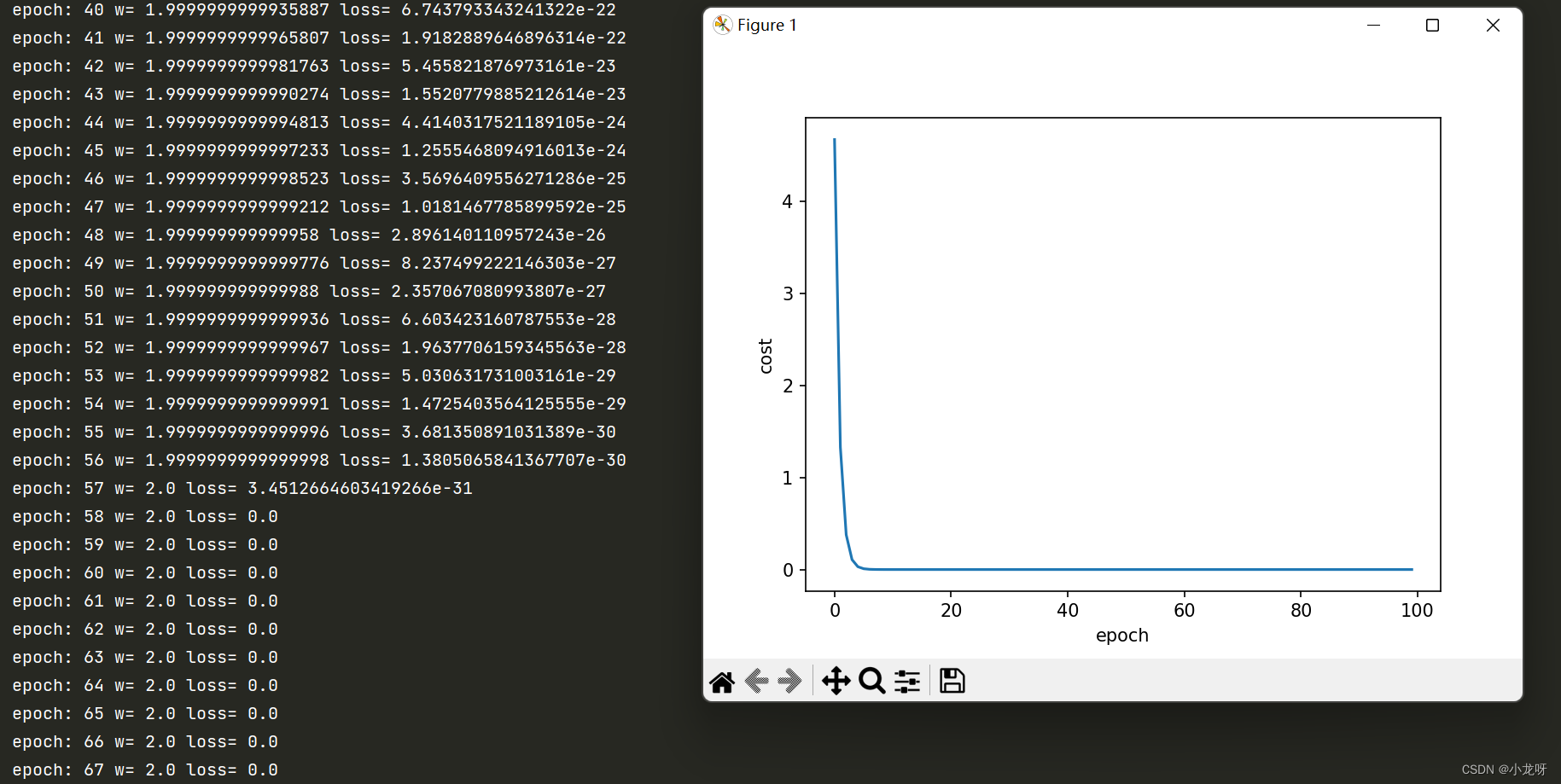
# 可视化
plt.plot(epoch_list, cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
二、随机梯度下降算法
1.简介
- 由于在最优解计算中,梯度下降算法往往会陷入局部最优的情况,所以我们引进随机梯度下降算法。在每一次迭代中,我们使用每一个训练样本的梯度进行参数更新。
- 这样可以使我们达到一个全局最优的情况,但是相应的计算复杂度也会提高,不太适用于训练样本较多的情况。在深度学习中,我们可以通过小批量随机梯度下降(Mini-Batch SGD)加速训练。
2.程序实现及结果
import matplotlib.pyplot as plt
# 训练集
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
# 初始化权重
w = 1.0
# 定义线性拟合函数
def forward(x):
return x * w
# 定义损失函数
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
# 定义梯度函数
def gradient(x, y):
return 2 * x * (x * w - y)
# 存储迭代次数和损失函数
epoch_list = []
loss_list = []
print('predict (before training):','x = 4','y=',forward(4)) #训练之前:预测
# 随机梯度下降算法(stochastic gradient descent)
# 每个epoch都使用三个样本分别进行参数更新,一共更新100*3=300次
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.05 * grad # 通过训练集中每个样本的梯度进行参数更新
print("\t grad:", x, y, grad)
l = loss(x, y)
print("progress:", epoch, "w=", w, "loss=", l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict (after training):','x = 4','y =',forward(4)) #训练之后:预测
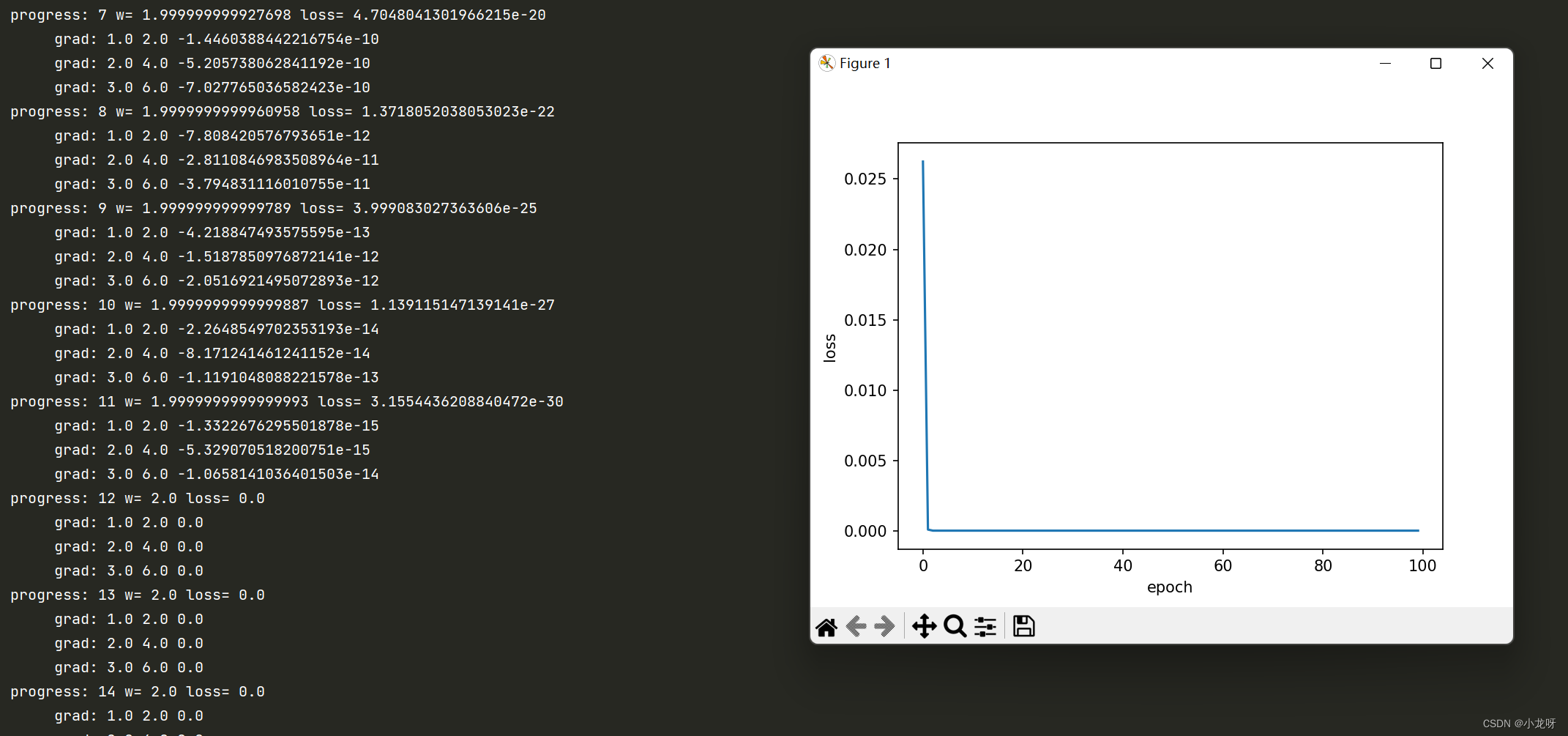
# 可视化
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
本文为系列文章:
| 上一篇 | 《Pytorch深度学习实践》目录 | 下一篇 |
|---|---|---|
| 线性模型(Linear Model) | 资料 | 反向传播(Back Propagation) |















 682
682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











