










目的:抓取豆瓣高评分喜剧电影
导入所需的库
import requests#进行模拟浏览器进行发送请求
import json#导入JSON类型的库
不会导入库的话,请参考我的上一篇文章,上面有提及。小白如何抓取网页
进行确定URL和浏览器的伪装
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
url = 'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start+=&limit+='
#大家仔细看这个URL有什么特点,在豆瓣排行榜的喜剧电影专区,打开开发者工具,不会打开请参考上一篇文章。
#在network中的RXH中发现请求的URL地址如下:
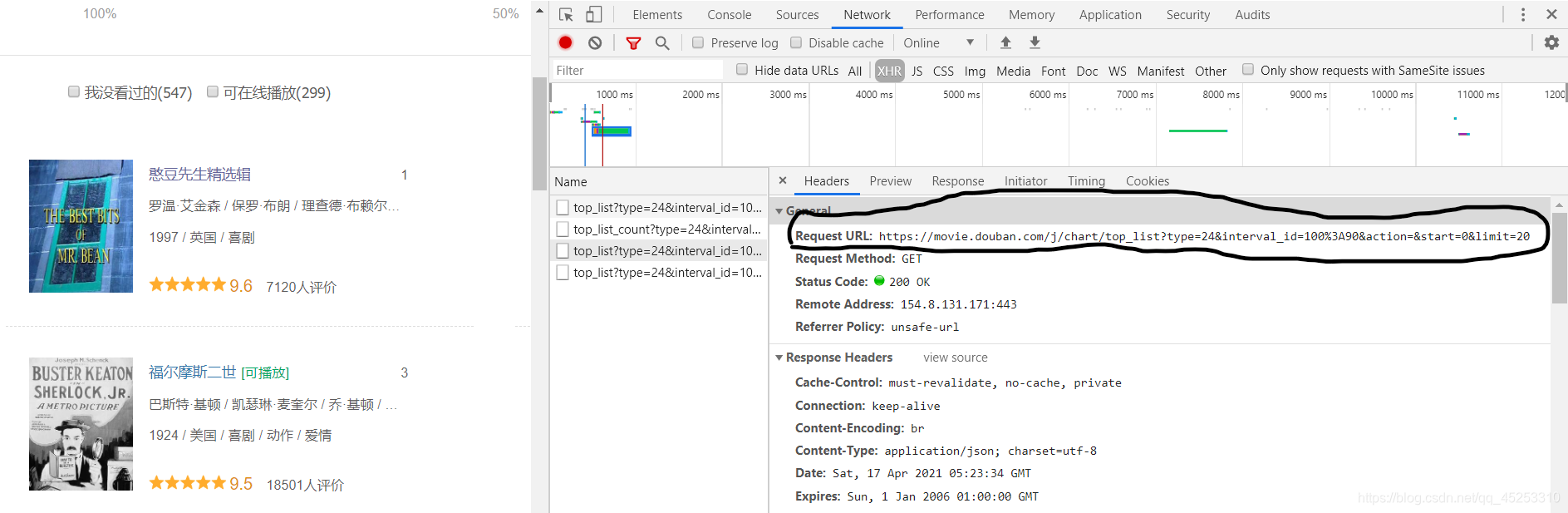
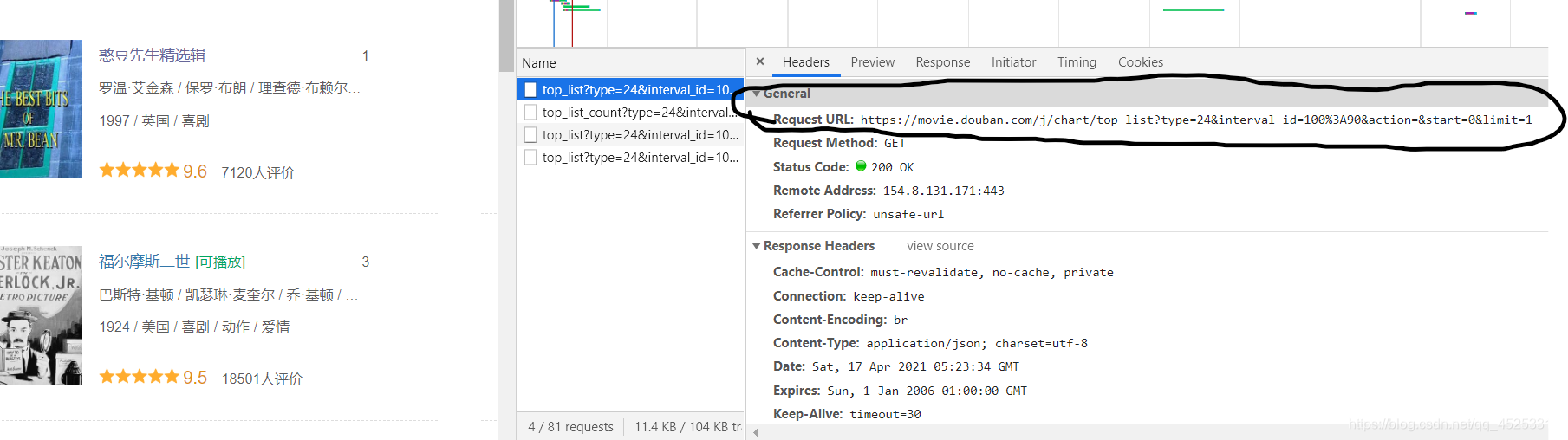
可发现其中变化的为后面的数字。所以为了抓取网站的全部内容,需要进行URL进行修改。仔细观看我所修改的URL地址
url = 'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start+=&limit+='
#添加一个加号+,进行修改,可以说是比较简单的方法。
进行字典的构建
number = input('选择从第几个喜剧电影开始:(第0部为排名第一):')#进行选择输入的电影起点
number1 = input('选择选取多少个电影:')#进行选择的电影的个数
word = input('想要保存的名称:')#进行选择电影的保存名称
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': number,
'limit': number1,
}

进行对应的浏览器请求
response = requests.get(url = url,params = param,headers = headers)
list_data = response.json()#输出的list_data为一个列表需要进行循环取出
进行循环取出内容
for movie in list_data:
name = movie['title']
score = movie['score']
rank = movie['rank']
print(rank, score, name)
进行永久性保存
fileName = word + '.json'
fp = open(fileName, 'w', encoding='utf-8')#确保编码方式为utg-8
json.dump(list_data, fp=fp, ensure_ascii=False)#JSON文件的保存格式
最终成果
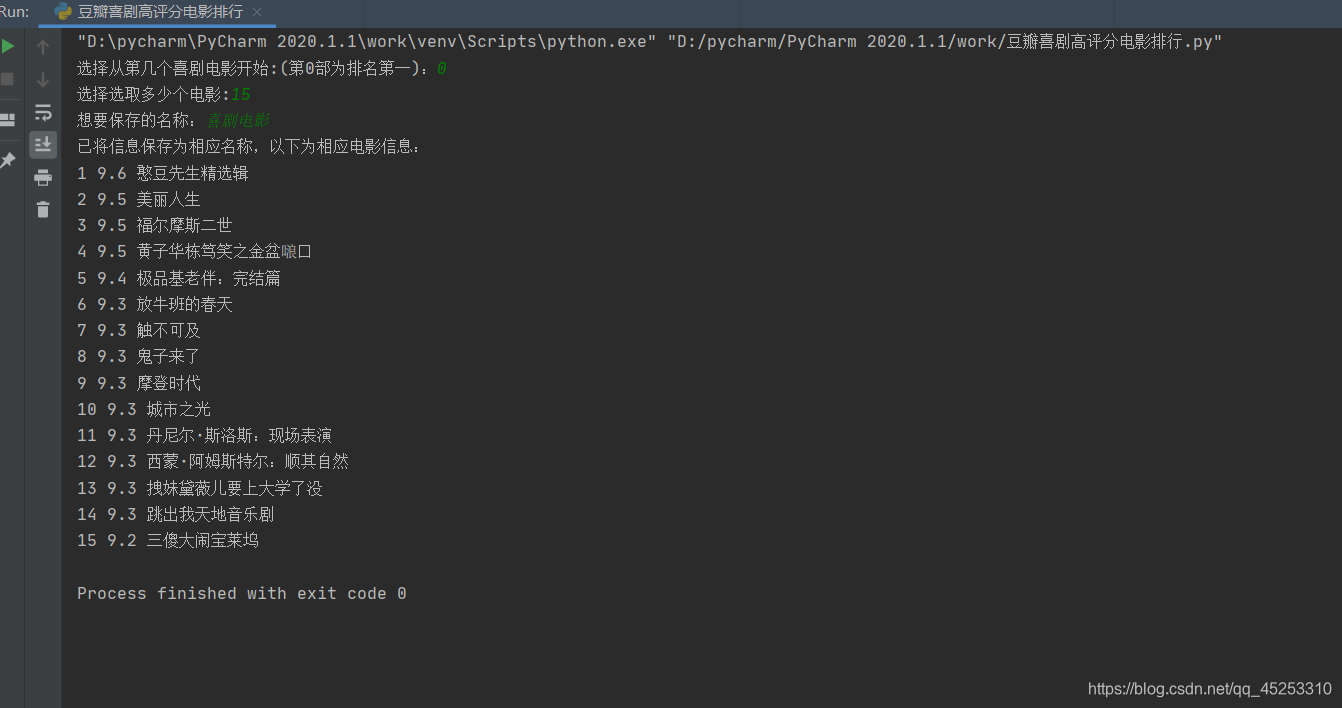

完整代码如下:
import requests
import json
if __name__ == "__main__":
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'
}
url = 'https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start+=&limit+='
number = input('选择从第几个喜剧电影开始:(第0部为排名第一):')
number1 = input('选择选取多少个电影:')
word = input('想要保存的名称:')
param = {
'type': '24',
'interval_id': '100:90',
'action':'',
'start': number,
'limit': number1,
}
response = requests.get(url = url,params = param,headers = headers)
list_data = response.json()
print('已将信息保存为相应名称,以下为相应电影信息:')
for movie in list_data:
name = movie['title']
score = movie['score']
rank = movie['rank']
print(rank, score, name)
fileName = word + '.json'
fp = open(fileName, 'w', encoding='utf-8')
json.dump(list_data, fp=fp, ensure_ascii=False)
重难点
在于对于URL的修改,可以增加为“+”来修改,此处为我的一点小技巧,嘿嘿。
对于字典的构建,可以用开发者工具进行查看。
若文章中有什么不懂的地方欢迎留言讨论,谢谢。
















 617
617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











