






数据展示:
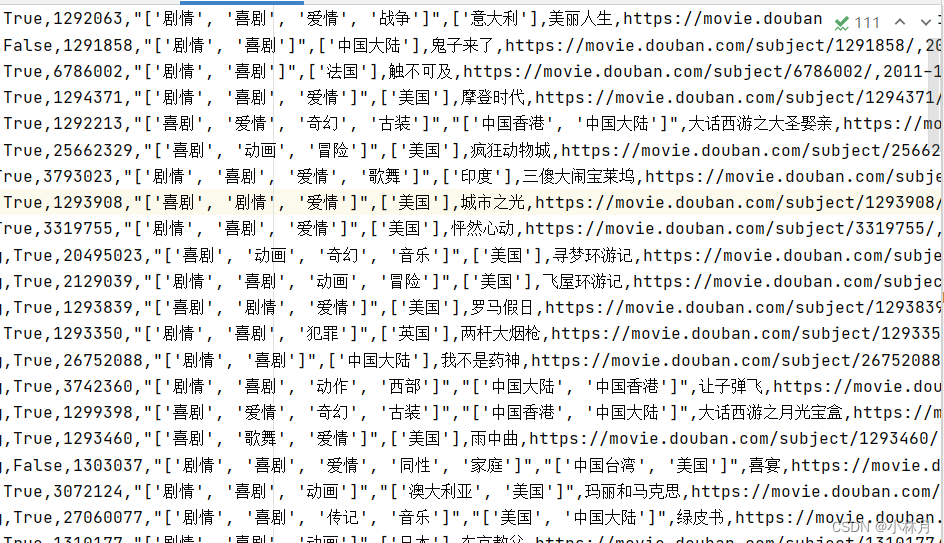
排行榜向下滑动的时候发起一个请求
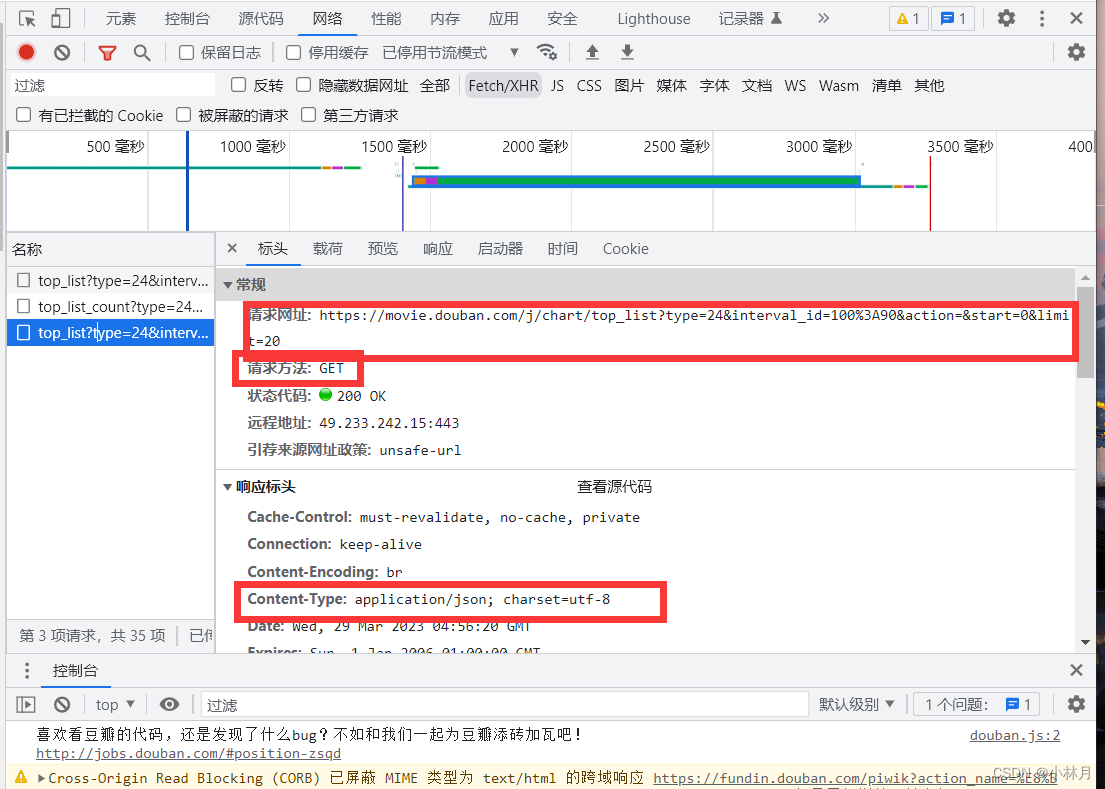
查看请求方法,网址,以及返回形式
直接利用requests模块上代码
import requests
if __name__=="__main__":
# 处理ucl携带的参数:封装到字典中
#UA伪装为一个用户浏览器进行访问数据
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
url = 'https://movie.douban.com/j/chart/top_list'
param = {
"type": "24",
"interval_id":"100:90",
"action":"",
"start": "0",#从第几部电影开始
"limit": "100"#到第几部电影结束
}
# 对指定的url发起的请求对应的url是携带参数的..并且请求过程虫处理了参数
response = requests.get(url=url,params=param,headers=headers)
diany_json = response.json()
#转换json文件为csv文件存储
keys = list(diany_json[0].keys())
# 这里输出类型转换前的类型和样子 供参考
# 为了方便保存的时候方便进行索引,于是先获取json内map的key值
list_json_data = []
for i in range(100):
list_json_data.append([diany_json[i][x] for x in keys])
# 上面一行的代码等于 :
# 1、
# list_json_data.append([json_list[i][keys[0]], json_list[i][keys[1]], json_list[i][keys[2]]])
# 2、
# tmpList = []
# for x in keys:
# tmpList.append(json_list[i][x])
# list_json_data.append(tmpList)
with open('data.csv','w',encoding='utf-8-sig',newline='') as f:
# 初始化 csv writer 对象
import csv
f = csv.writer(f)
# 遍历json数据列表并保存每个列表
for list_data in list_json_data:
f.writerow(list_data)

















 336
336

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









